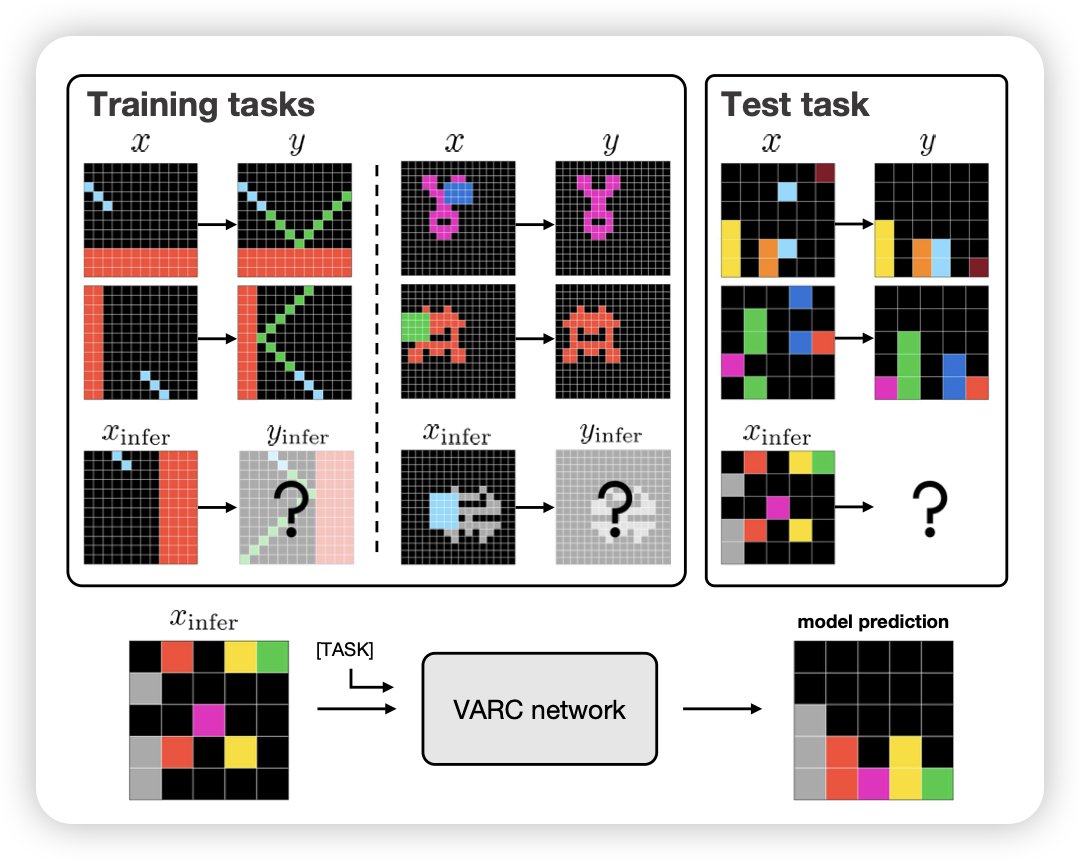
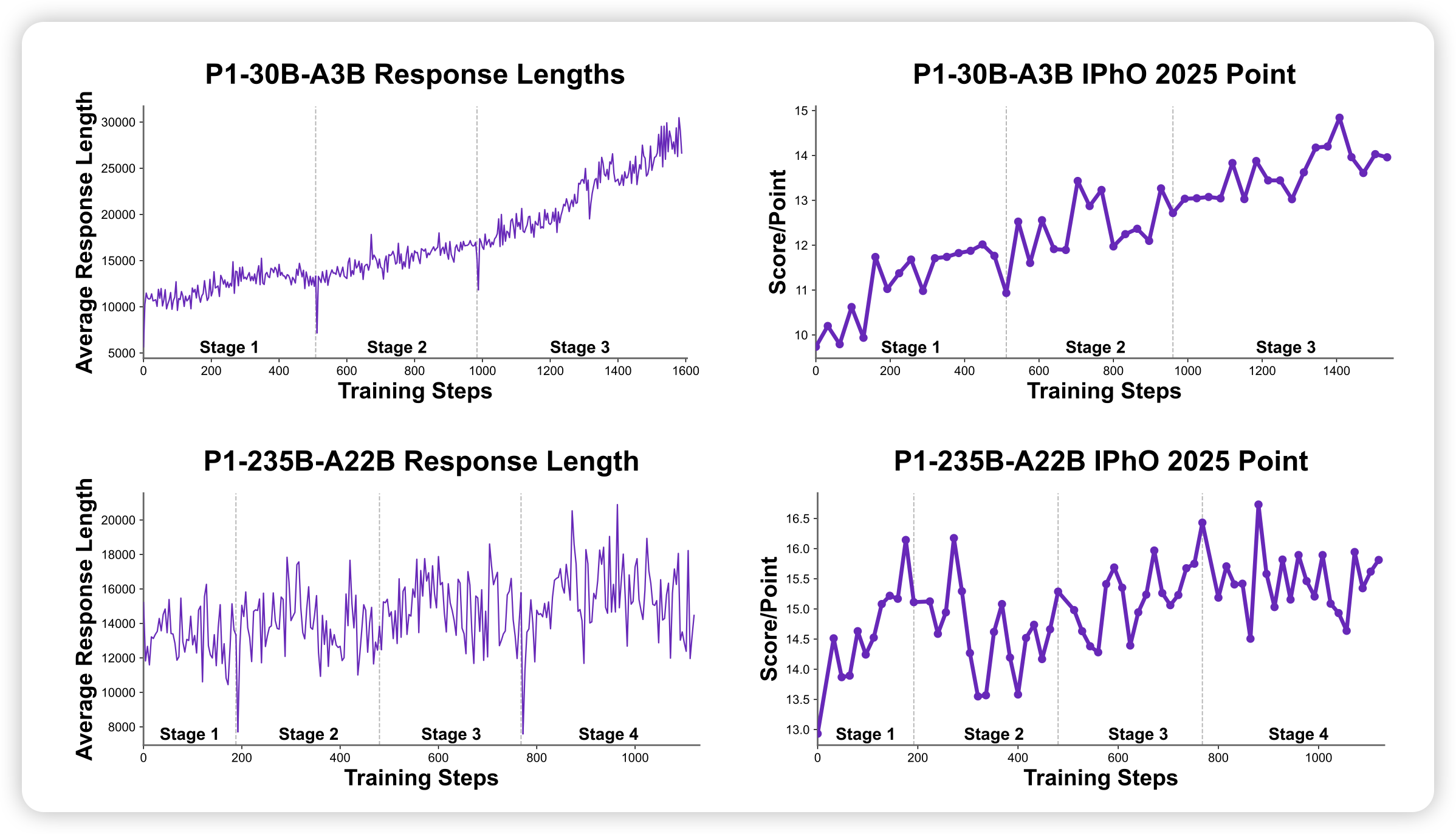
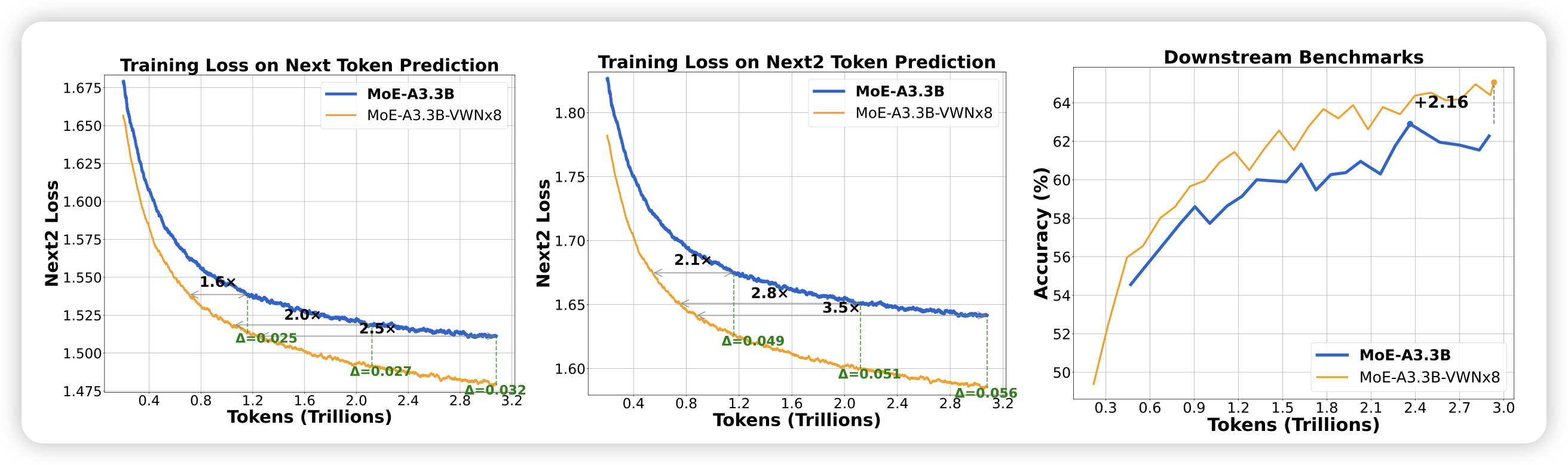
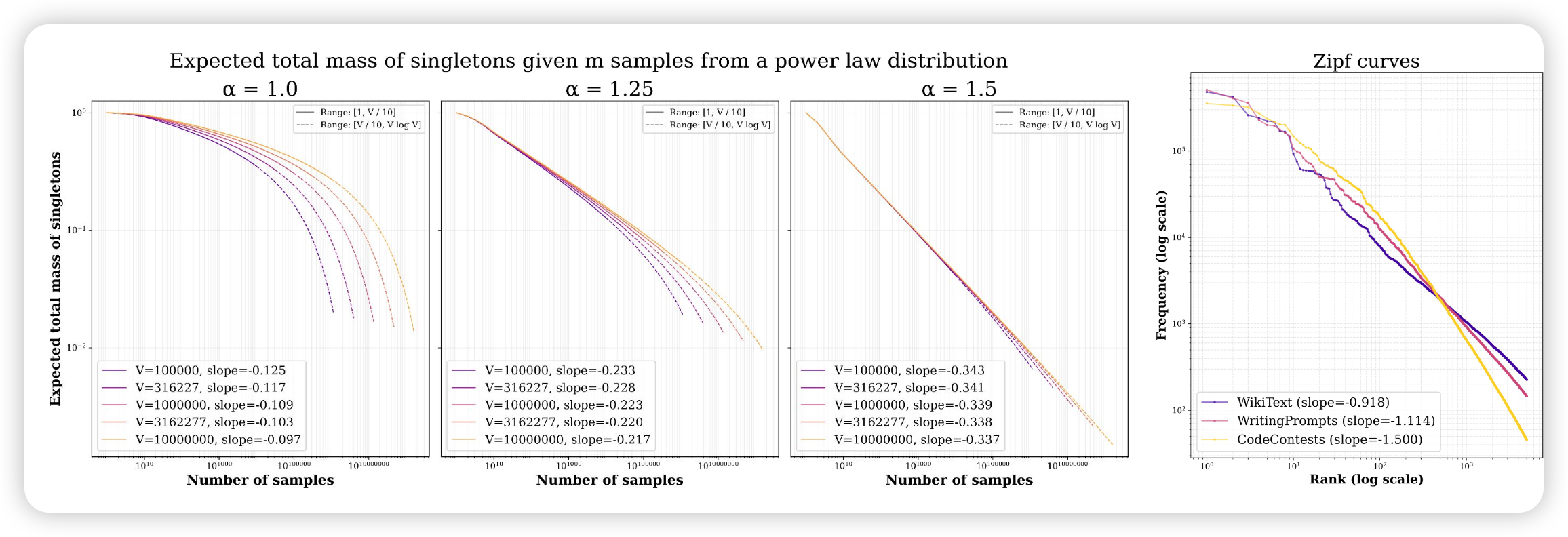
| 2025年十二月December | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 😁 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 | |||
| 2025年十一月November | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 1 | ||||||
| 😁 | 😁 | 😁😁 | 5 | 😁 | 7 | 😁 |
| 😁😁 | 10 | 😁 | 😁😁 | 😁 | 14 | 😁 |
| 😁 | 17 | 😁 | 19 | 20 | 😁 | 22 |
| 😁 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | ||||||
| 2025年十月October | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 1 | 2 | 3 | 4 | |||
| 5 | 😁 | 😁 | 😁😁 | 😁 | 😁 | 😁 |
| 😁 | 😁 | 14 | 😁 | 😁 | 😁😁 | 18 |
| 19 | 😁 | 😁 | 22 | 23 | 😁 | 25 |
| 😁 | 😁 | 😁 | 29 | 30 | 31 | |
| 2025年九月September | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 1 | 😁 | 3 | 4 | 5 | 😁 | |
| 7 | 😁😁 | 9 | 😁 | 11 | 😁 | 13 |
| 14 | 😁 | 😁😁 | 17 | 😁 | 😁 | 20 |
| 😁😁😁 | 😁 | 😁 | 24 | 😁😁 | 26 | 😁😁 |
| 28 | 😁 | 😁 | ||||
| 2025年八月August | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 1 | 2 | |||||
| 😁 | 4 | 5 | 6 | 😁 | 😁 | 9 |
| 😁 | 😁 | 12 | 😁 | 😁😁 | 15 | 16 |
| 17 | 😁😁 | 19 | 😁 | 21 | 22 | 😁 |
| 😁😁 | 25 | 26 | 27 | 😁 | 😁 | 30 |
| 😁 | ||||||
| 2025年七月July | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 😁 | 😁 | 😁 | 😁 | 5 | ||
| 6 | 7 | 😁 | 9 | 10 | 😁 | 😁 |
| 😁 | 14 | 😁😁 | 😁 | 😁 | 18 | 19 |
| 😁 | 😁 | 😁 | 23 | 24 | 25 | 26 |
| 😁😁 | 😁 | 😁 | 😁 | 31 | ||
| 2025年六月June | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 1 | 2 | 😁😁 | 4 | 5 | 6 | 7 |
| 😁 | 9 | 10 | 11 | 😁 | 😁 | 😁 |
| 😁 | 😁😁😁 | 17 | 😁😁 | 19 | 😁 | 21 |
| 22 | 23 | 😁 | 25 | 😁 | 27 | 😁 |
| 😁😁 | 😁 | |||||
| 2025年五月May | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 😁😁 | 2 | 3 | ||||
| 😁 | 😁 | 6 | 7 | 😁😁😁 | 😁 | 10 |
| 11 | 😁 | 😁 | 😁 | 😁 | 😁 | 17 |
| 18 | 19 | 😁 | 21 | 😁 | 23 | 😁 |
| 😁😁 | 😁 | 😁 | 28 | 😁 | 😁 | 😁 |
| 2025年四月April | ||||||
|
星期日 Sunday |
星期一 Monday |
星期二 Tuesday |
星期三 Wednesday |
星期四 Thursday |
星期五 Friday |
星期六 Saturday |
| 😁 | 😁 | 3 | 4 | 😁😁 | ||
| 6 | 😁 | 😁 | 😁 | 😁 | 😁 | 12 |
| 13 | 😁 | 😁 | 😁 | 😁 | 😁 | 19 |
| 20 | 😁 | 22 | 23 | 24 | 😁 | 26 |
| 27 | 28 | 😁😁 | 😁😁😁 | |||