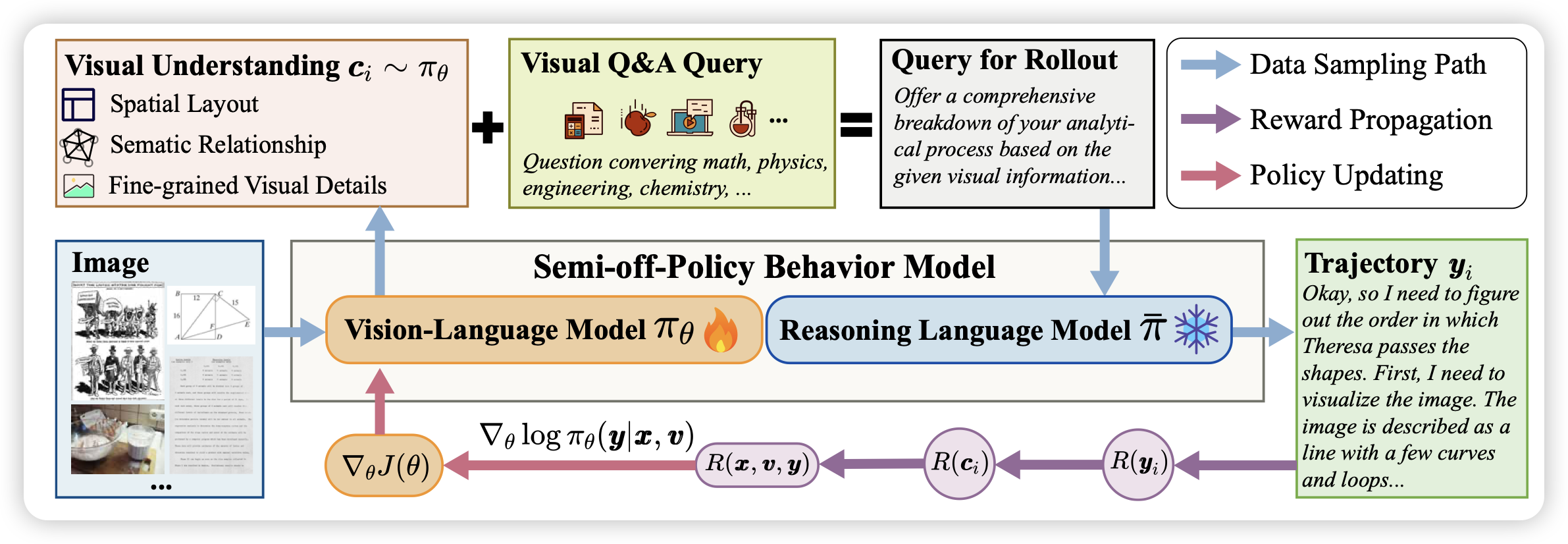
Semi-off-Policy Reinforcement Learning for Vision-Language Slow-thinking Reasoning
这篇工作想要解决VLM中的感知问题,而且希望vlm学会对reasoning有帮助的perception。所以,作者让一个可训练的vlm先生成caption,然后让一个freeze的text-reasoning model看着caption回答问题,用后者的平均正确率来给出perception部分reward。
作者这里没有直接使用end2end vlm rl的原因是,起点模型本身的reasoning能力过于差,而无法进行高效rollout
这个设计哲学还挺有意思的:把系统的其余部分锁定,然后对剩余的原子能力进行单点提升