Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
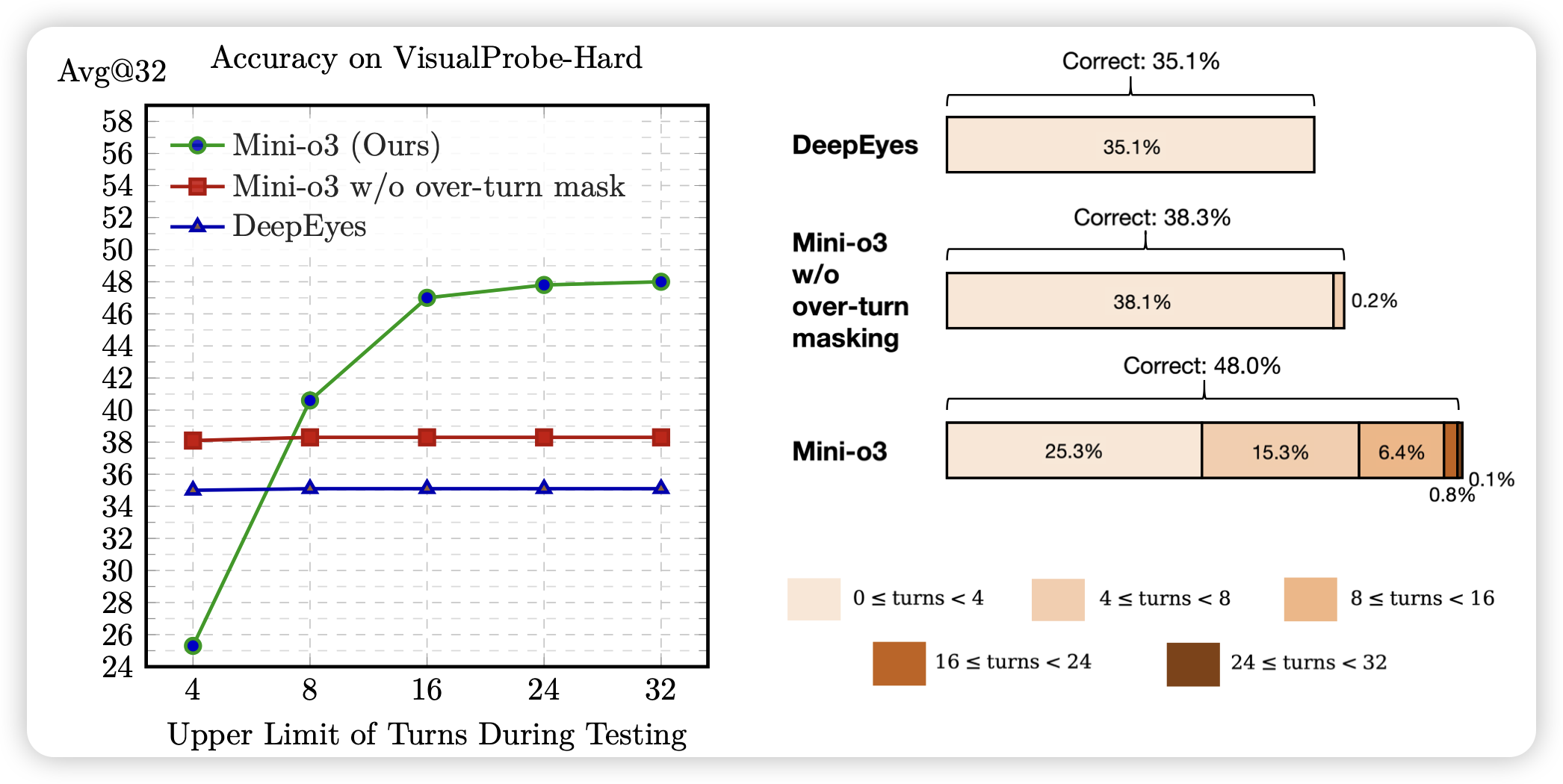
seed出的一篇visual cot领域的工作。这个场景是让模型去通过放大缩小图片,来研究图片里是否包含一些信息。作者做了一个算法上的改进,在多轮rl过程中,如果遇到模型hit max iteration时没有提交任务,这条数据就不训练,而不是按照0分赋值。这是因为这些样本实际上“不一定”是坏样本,可能只是budget给的不够。作者把这个设计叫做over-turn mask
对于overlong样本如何处理,现在学术界似乎分化出了几派观点。有人会mask,有人会罚分,有人会给一个soft punish做一下线性的reward衰减,还有人直接在system prompt里说明budget让模型学习去自己研究budget...不知道有没有谁可以把这个问题比较本质的解决?有点像是之前大家最开始给量子论打补丁的样子...
∆L Normalization: RETHINK LOSS AGGREGATION IN RLVR
刚说完multi-agent中length的问题,这篇工作就是在讲length问题带来的loss aggregation。作者想解决的核心问题是:一个batch里的各个traj,大家的length差距很大,该如何给每个token做loss权重,才能让每个人都公平呢?作者在这篇工作了给了很多数学,最后推导出了一个看上去很公平的算法

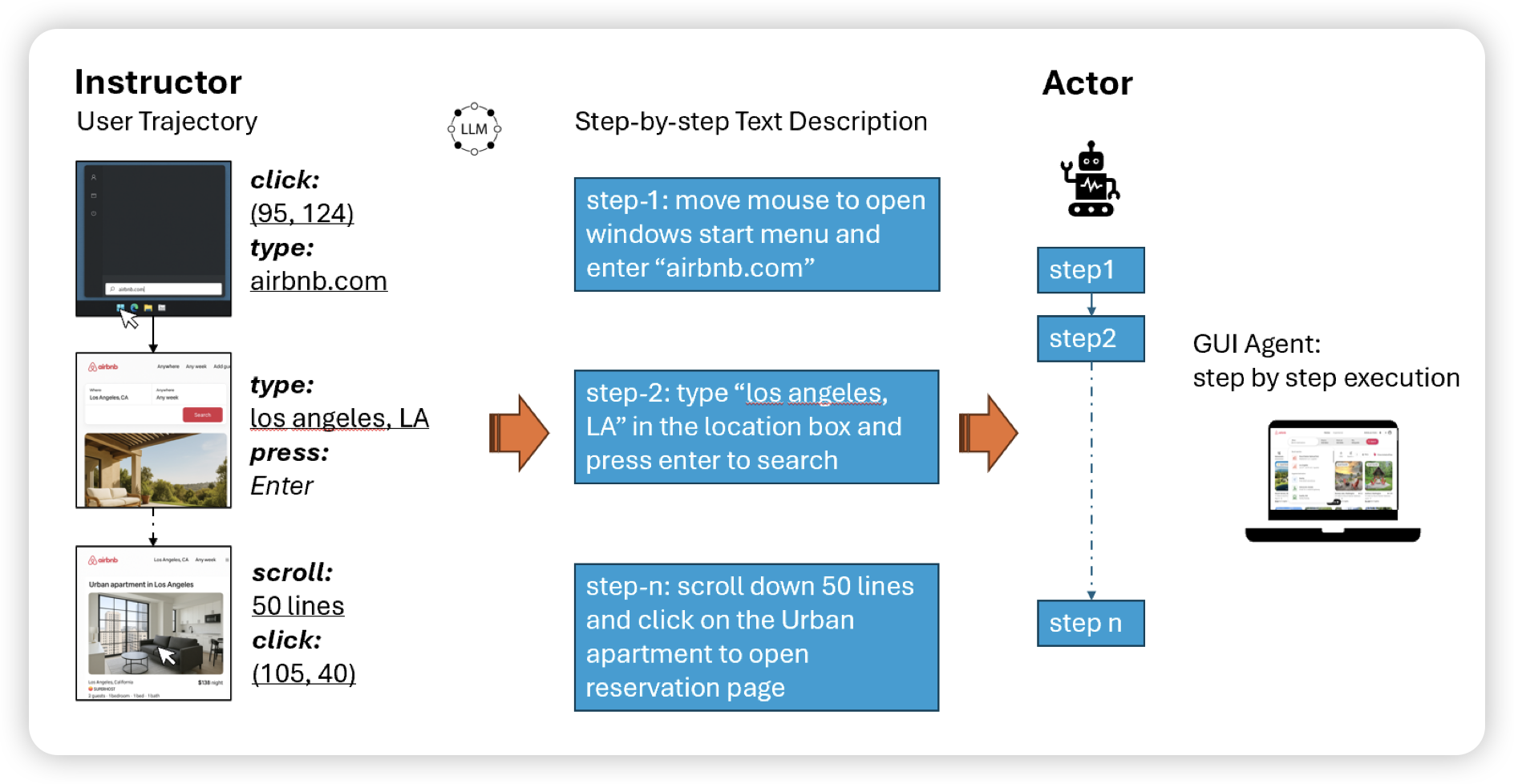
Instruction Agent: Enhancing Agent with Expert Demonstration
这篇工作虽然图画得比较简陋,但是事情挺有意思的。作者在GUI Benchmark OSWorld上尝试了让模型follow每个题目,人写的过程指导。发现在给出正确指导的情况下,模型在70%以上的情况下都可以把本来不会做的题目做对
这个方向在几个月前有几篇和tutorial learning相关的工作,但是再后面似乎就没有做这个方向了。我一直很喜欢,之前想出一篇阅读笔记梳理来着
CAViAR: Critic-Augmented Video Agentic Reasoning
这是一篇deepmind参与的、有点奇怪的工作,有点像是回到了o1刚出来时大家做reason module时的讨论。作者希望模型可以把thought表达成一种类似代码的形态⬇️,准确来说是如果遇到了真的代码,是可以真的跑代码的。用这个方法来做video reason任务
话说如果alphaelove/昨天的software那些 tree search/进化 的工作可以work,那这种形态的东西可能反而更适合了?
