VIBEVOICE Technical Report
一篇speech synthesis领域的文章。和之前的工作不同在于,他直接用diffusion生成latent,然后不解码到离散词表,而是直接让autodecoder转换成声音。同时下一个timestep输入的也是latent。
Latent in latent out明显是更直觉的方案,但是之前好像大家都是输入离散token。不知道这里面的难点在哪里?是不是模型生成的latent分布有累积误差?这个是latent-o1的障碍
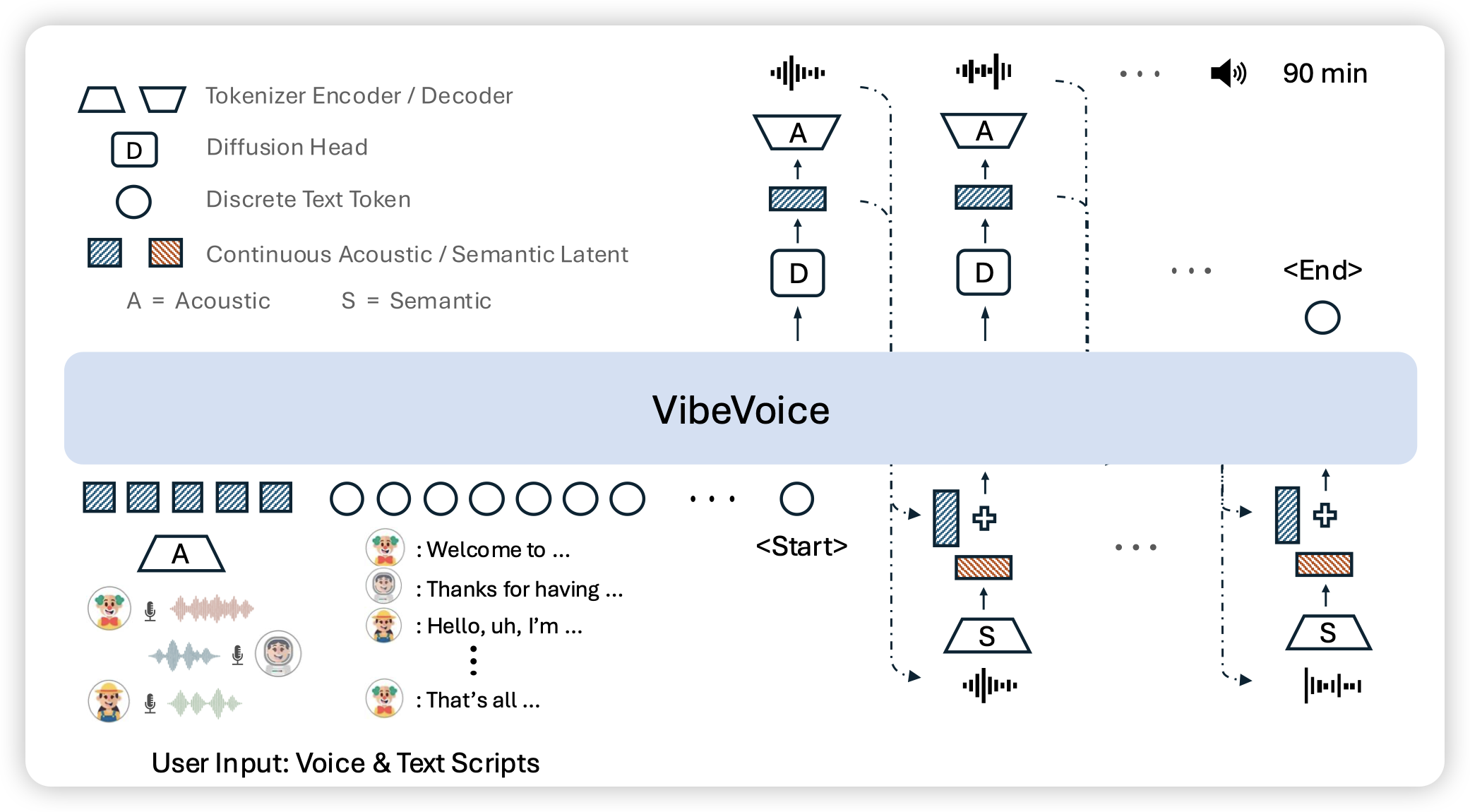
一篇speech synthesis领域的文章。和之前的工作不同在于,他直接用diffusion生成latent,然后不解码到离散词表,而是直接让autodecoder转换成声音。同时下一个timestep输入的也是latent。
Latent in latent out明显是更直觉的方案,但是之前好像大家都是输入离散token。不知道这里面的难点在哪里?是不是模型生成的latent分布有累积误差?这个是latent-o1的障碍