J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
meta的grm工作。作者希望用rl去训练模型打分的能力,因此把一些具有function verifier的题和没有function

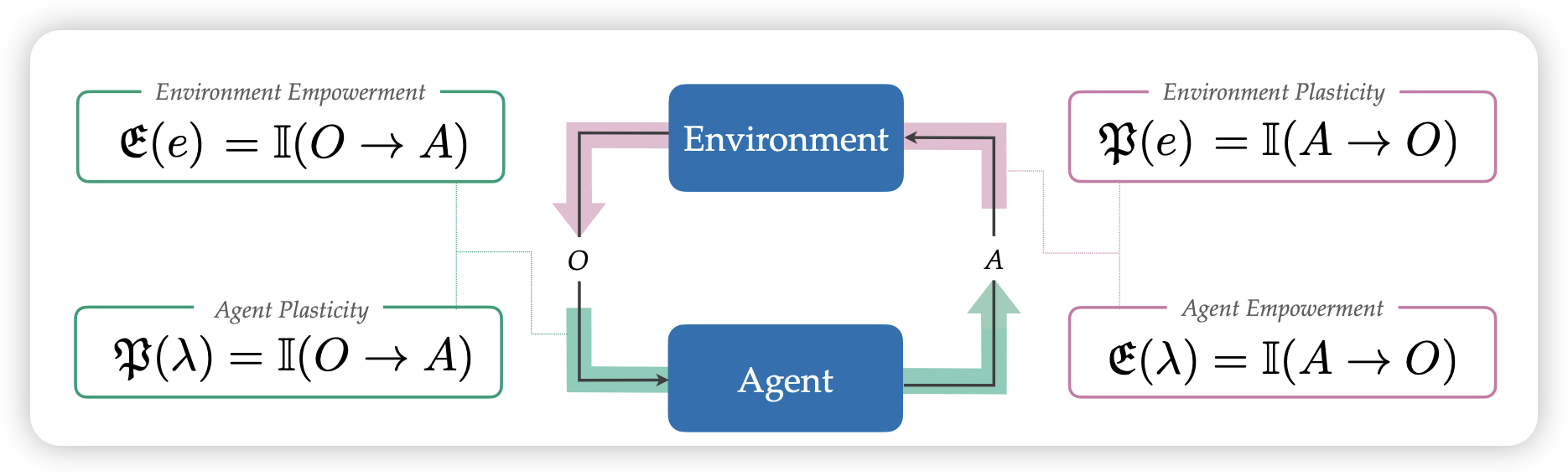
Plasticity as the Mirror of Empowerment
这篇deepmind的工作讲了两个概念,非常深刻:
- plasticity:从环境变化中学习适配自己的能力
- empowerment:自己的动作对空间的影响能力
作者发现这两个能力是没法一起优化的。比如说:一只老鼠在迷宫左区,能通过灯光信号学习环境规律(高可塑性),但无法控制灯光开关(低赋权)。同一只老鼠在迷宫右区,如果能完全控制灯光(高赋权),就无法从固定环境中学习新信息(低可塑性)。