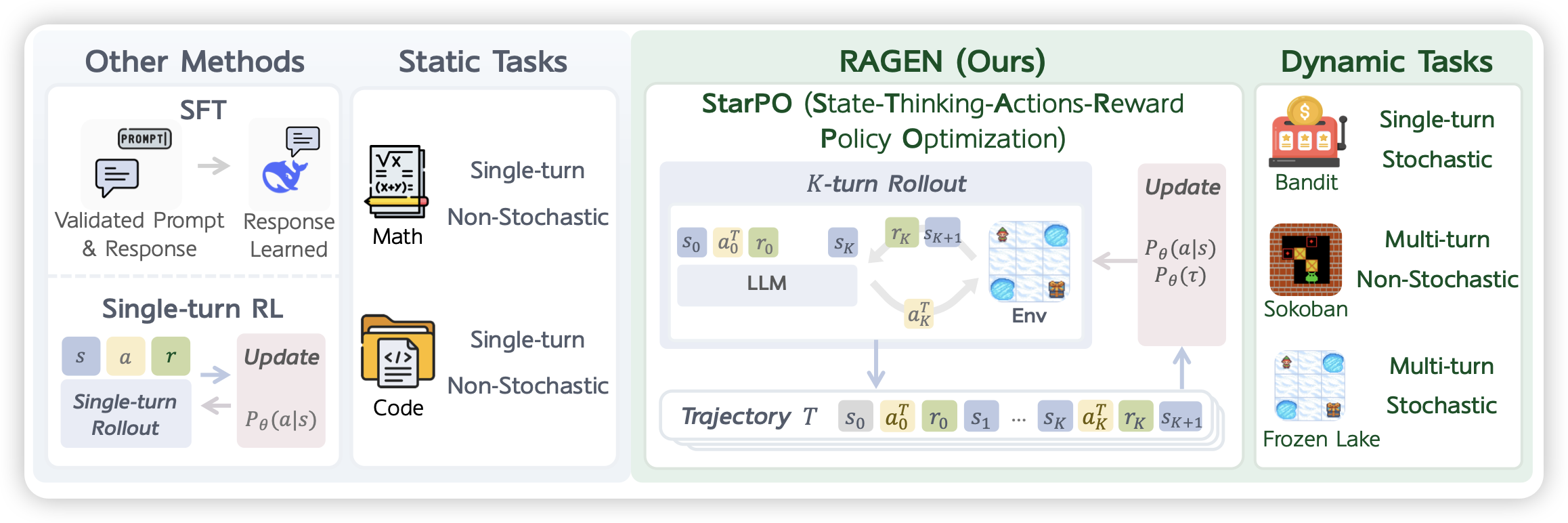
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
一篇agent rl方向的论文,写得有点零零散散,但大概覆盖到了多轮react形式的训练,以及里面的loss trick,感觉还是挺不错的
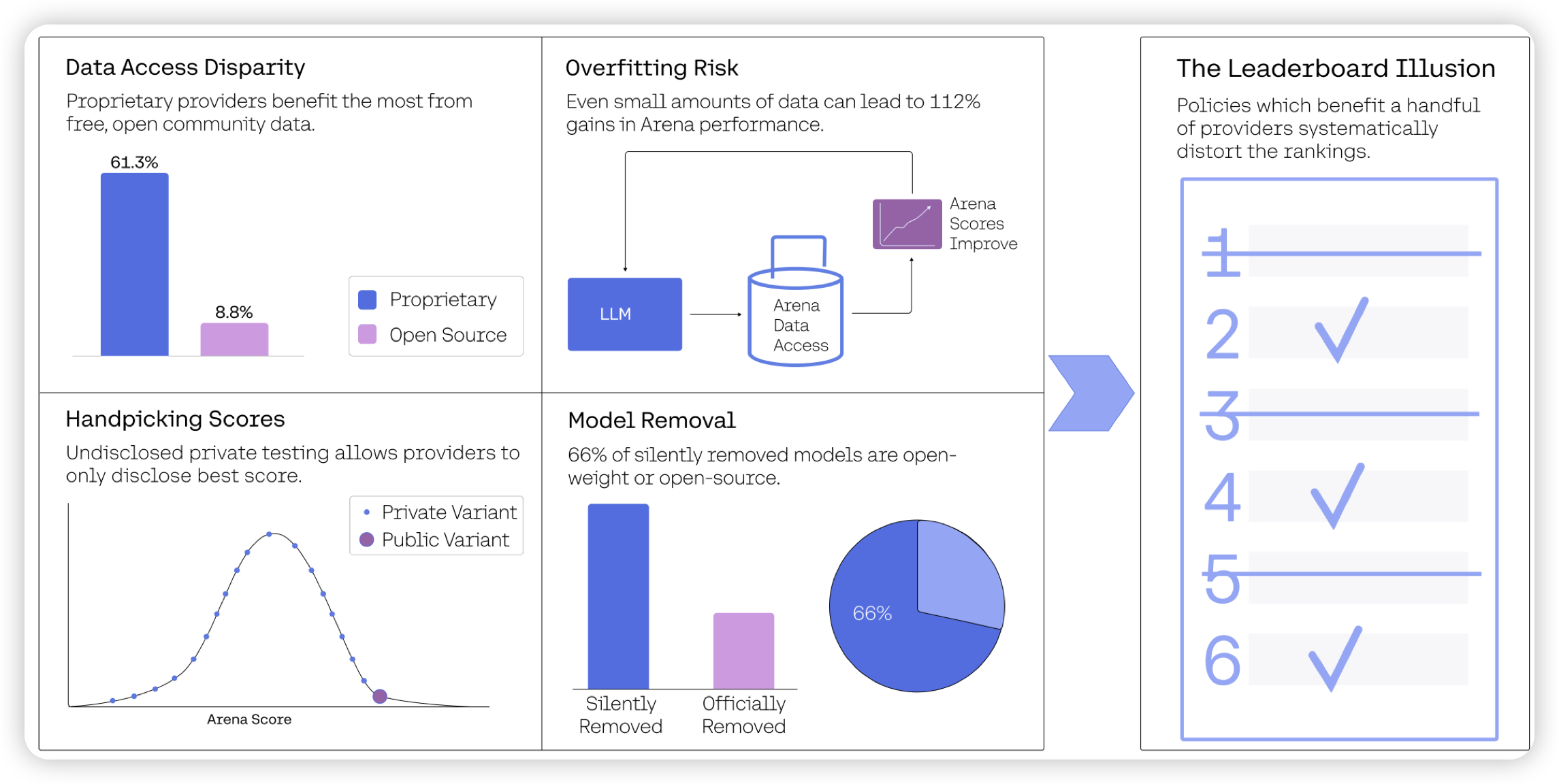
The Leaderboard Illusion
一篇见解深刻的文章,作者分析了一个问题:chatbotarena都是人类盲选打分,但真的公平吗?作者发现了以下问题:
- 闭源因为效果好,就更大的可能被留在elo系统里,导致公司有更多的chatbotarena真实数据来做优化
- 各家总是在模型发布前在chatbotarena发布多个模型,最后公布效果最好的一个。这某种程度是对chatbotarena做best-of-n
总体来看,越是大公司,越是有力。openai一家公司享有20%的数据,另外83家开源模型加起来占29%