ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
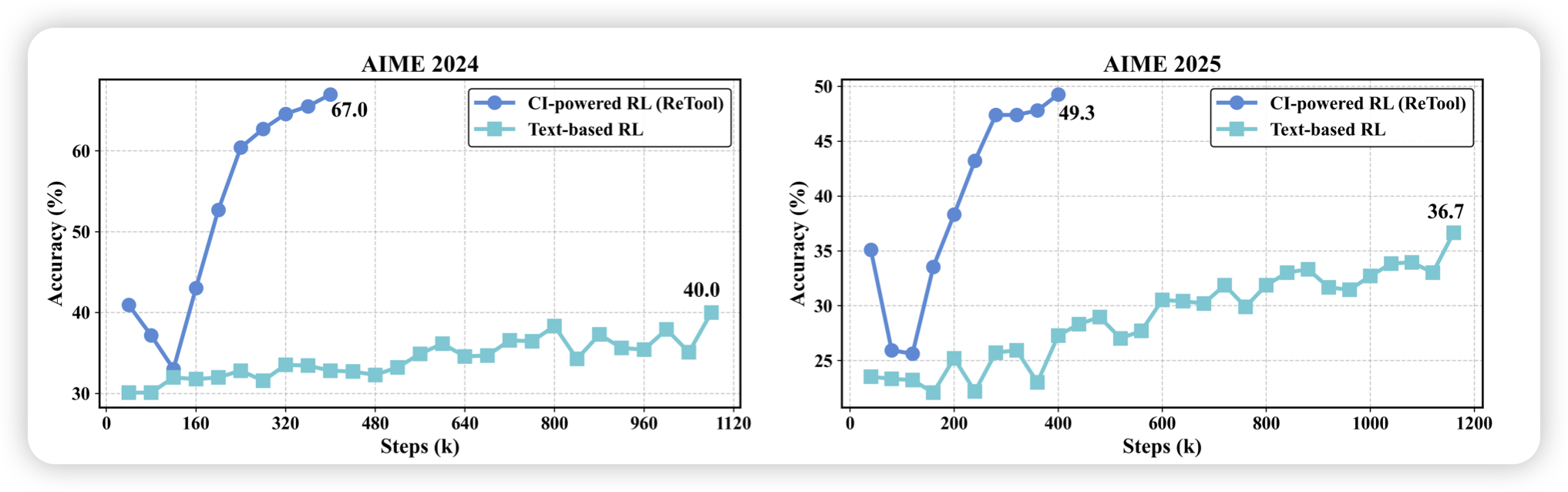
推荐一下工友的工作。大家都在等待agent end2end rl起飞,这里迈出了第一步:如果在数学题中可以写代码,能不能训练出长thought呢?作者发现,在有一个工具的setting下,是可以做出正收益,让thought长度健康增长的。
其实这个方向并不新,几年前就一直有人做了,但是gsm8k。在aime级别题目、10k reasoning budget这个scaling尺度下,我印象中应该只有deep research有过正收益了