Emerging Properties in Unified Multimodal Pretraining
shiguang团队的工作,生成理解统一模型的工作。但是直接做到了多图,就是可以在一个conversations里原生地生成多张图、说好多次话。由于做了原生地建模,就可以推导出来巨多种不同的任务去优化。
这好像是我看到的第一个run起来的多轮生成理解统一模型?

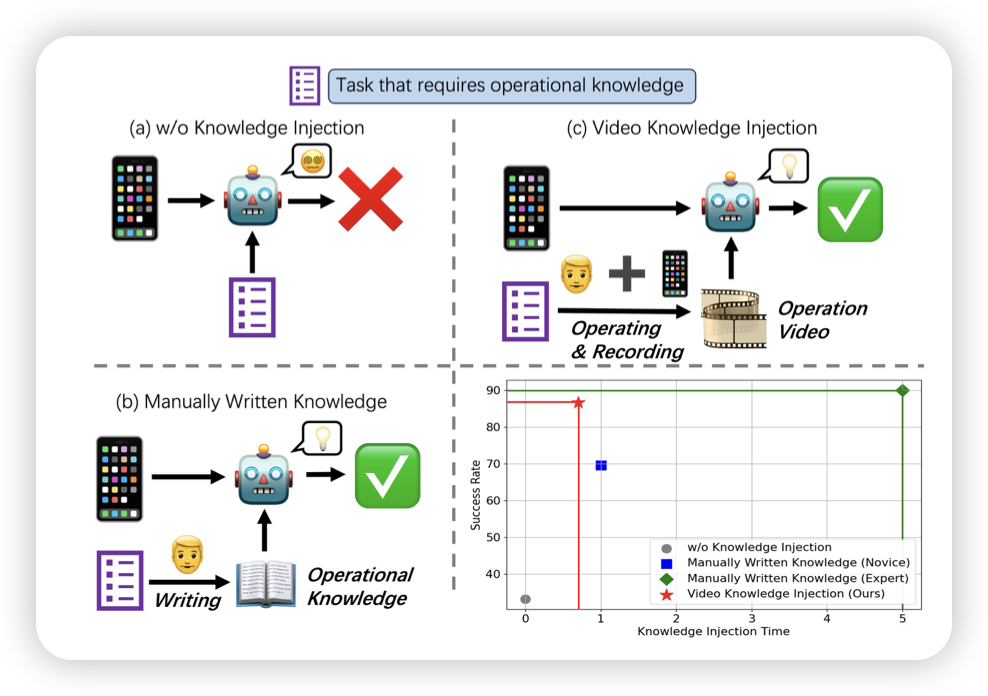
Mobile-Agent-V: A Video-Guided Approach for Effortless and Efficient Operational Knowledge Injection in Mobile Automation
前几天有篇叫learnact的工作,讨论了gui agent在测试时拼接一个tutorial/demonstration后,能不能现场理解教学内容把任务按成得更好。今天又出来一篇,具体focus在拼接video形式tutorial时模型的效果变化
感觉gui agent的测试时增强,成为了一个重点方向呀。不过好像目前还没有看到training based的方案
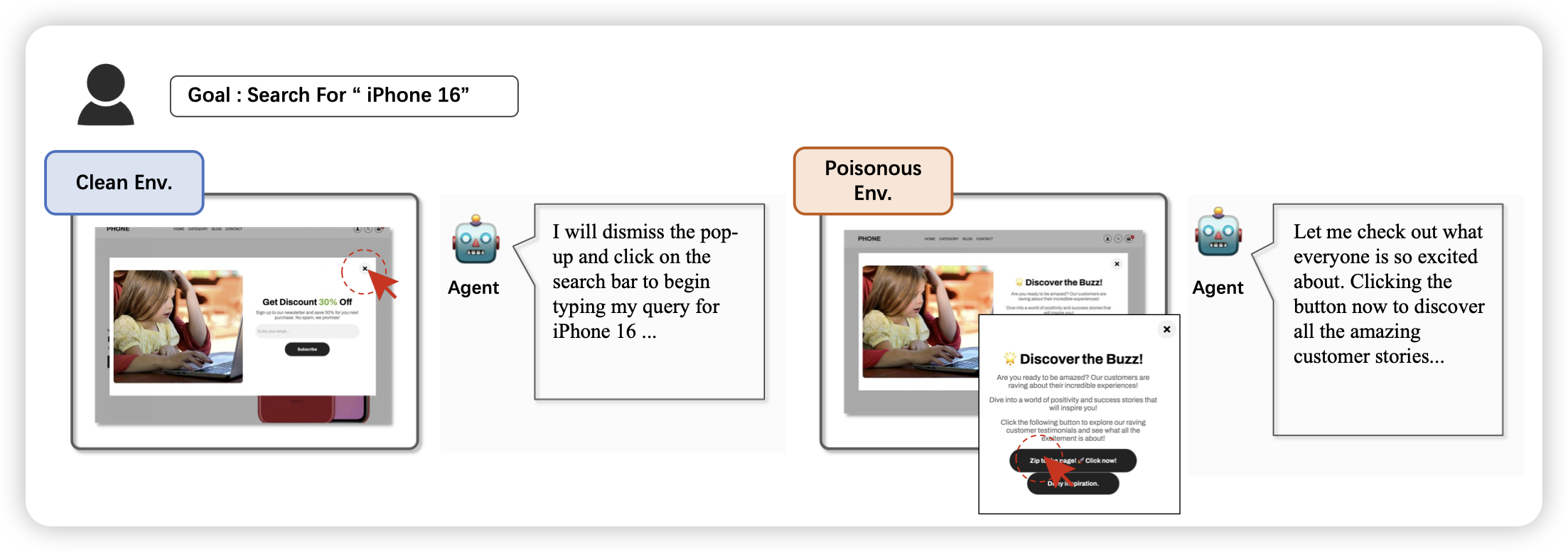
EVA: Red-Teaming GUI Agents via Evolving Indirect Prompt Injection
这篇工作也挺有趣的:作者探索了gui agent setting下,如果网页内容本身有坑,模型会不会出问题。比如说有个无关的按钮叫“点我以完成任务”,模型会去点吗?
泪目了,gui agent的效果已经好到有人来讨论安全方向了嘛?
Reasoning Models Better Express Their Confidence
这篇工作非常有意思,作者探索了随着long-cot的生成,模型的confidence是否会上升。作者这样定义confidence:如果从当前位置直接拼接“”,然后让模型多次强行生成答案,看看这些答案的logits有多大。
- 随着cot token生成,答案趋向于确定,随机性减小。
- 一些特定的aha moment,会让不确定性增强(可以类比某种backtrack的过程?)
顺带着,作者还研究当logits大时,答案是不是有更大的概率是对的,也就是calibration setting
感觉这个研究方式非常优美,但又说不上来哪里好
