好长时间没写论文阅读笔记了,今天读一下LeCun讲了一年的"世界模型":新的训练范式、训练快、参数少(0.6B)、效果好、方法简单、概念明确。
我在讲解时会说一些我的思路,因此我里面提到的一些优点、缺点有一些不是论文里说的是我自己的观点,完整故事逻辑大家可以去看原论文,论文写得很好。
作者团队就是LeCun团队

Introduction
自监督学习一直是实现通用人工智能的关键。
我的理解:
1.所有的自监督学习方法都是建立在数据的基础上,更多数据,更多智能。
2."无监督"数据其实并不是真正的无监督。举个例子,文本都是一段一段的,前文后文有关系,所以我们可以开发auto-regressive。CLIP中选用了互联网(图像-文本)对也是天然含有相关性的。自监督学习其实是在挖掘数据中这种通用的、数据天然包含的、自相关的关系。
作者在这篇文章中主要讲了一种新的自监督学习的架构,因此对标的是之前的几种训练范式,作者在这里首先归纳了已有的几种训练范式
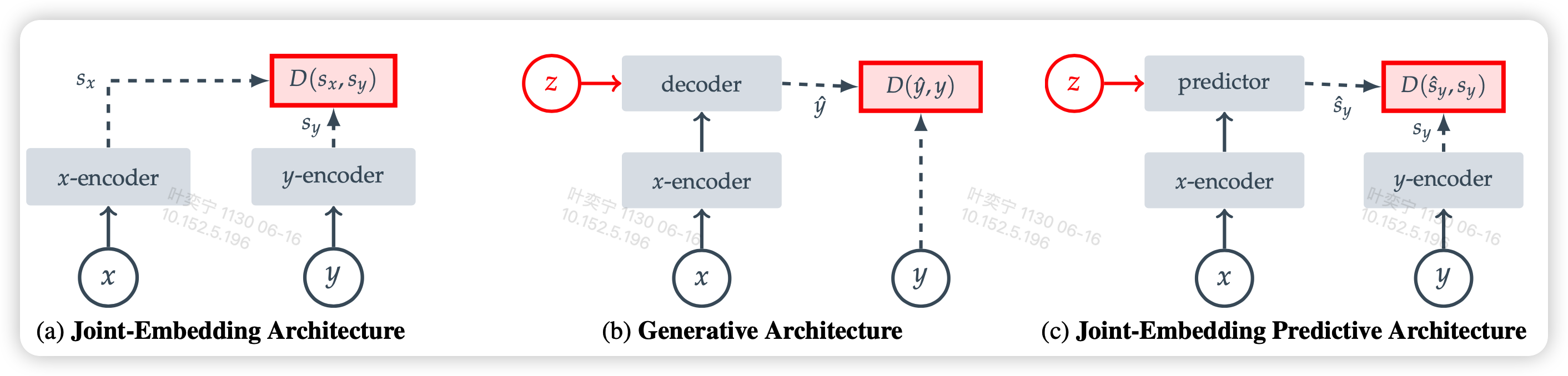
所有的范式都需要找到相关的数据 x,y。
- 这里的相关可以是:x、y是同一张图片,但可能x是被mask一部分信息的
- 也可以是x、y是不同模态的描述同一信息的数据
编码式
首先是Join-Embedding Architecture,用两个编码器分别给相关的x,y进行编码,然后通过编码\(s_x,s_y\)之间相似度来计算loss
这种编码方式的优势是训练比较快,但是有个主要的问题就是representation collapse,如果编码器永远输出0,那么相似度肯定一直是0,阁下又将如何应对?为了解决这个问题,有一些工作从各种地方减少之
- 对比学习:前几年大火的对比学习在正样本的基础上,再引入负样本,在正正样本相似度大的基础上,让正负样本之间的相似度尽可能小。
- non-contrastive loss:尽量减小信息熵,这个领域我没了解过
- 聚类:把相似的物体天生聚类到一起,这个可以视为对比学习的一种特殊形式?
另外,作为经验规律,除了mask之外,还要做各种各样的数据增强来获取正样本,这个工作很dirty,但是对这类方法的最终效果非常重要。不优雅。
生成式
另外一大类方法是生成式,将x编码后的结果用一个解码器解码回y,然后在obj粒度计算相似度。其实GPT可以视为这类方法,如果x是上文,y是最后一个单词,z是空的话。
这种方法天生没有collapse的问题,因为\(s_x\)是可训练的,但y永远是锁定的。不过这类方法带来另外的问题是过于关注局部细节,这会导致大量的训练资源浪费在不重要的地方。因此训练速度一般也很慢,质量也无法保证(支持的例子可以看diffusion系列的工作)
- 对于图像,80%的像素其实都是没啥信息的,换句话说是不可预测的,但模型并不能区分哪里是不可预测的,而且这个loss对于所有像素一视同仁。
- 进一步看,对于文本模态,可以用之前笔记提到的数据集天然随机性解释,crosseentropy loss有下限。
这个问题没法显式地解决,因为”无监督“这个条件本身就代表无法预测。
JEPA
作者想到了另外的办法,能不能结合上面的范式,利用双方的优点呢?
作者认为,可以做生成,但计算loss要在representation维度。这个可以天生避免上面说的无效信息问题:因为编码器在训练过程中对于x和y都可以自动忽略无效信息
不过,和编码式结构一样,这种方法仍然面临塌缩问题。
method
具体来看,作者本篇工作聚焦于图像模态,这样设计I-JEPA工作流程图
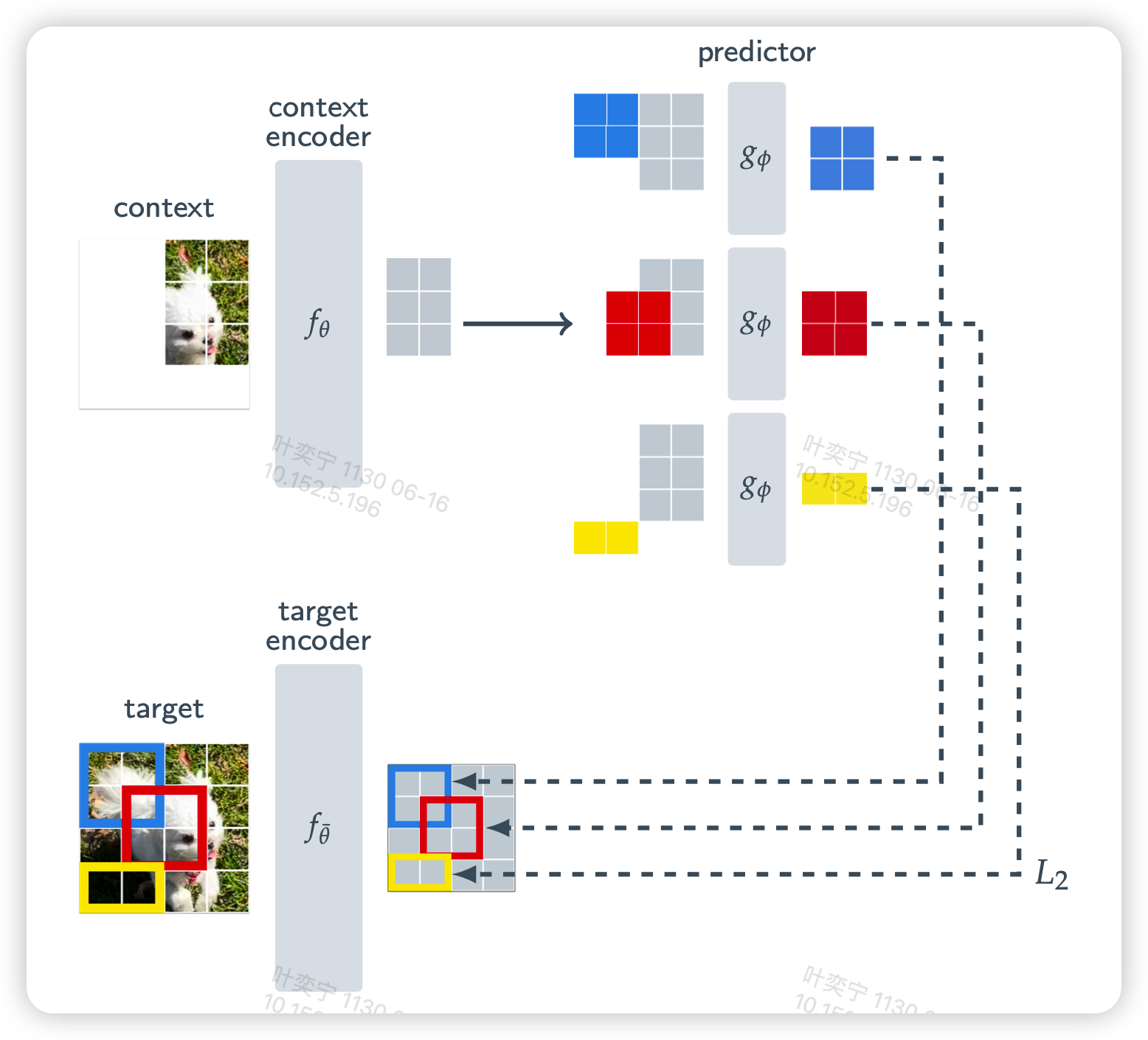
首先对于一张完整的图片,采样一部分作为context,这是可见的已知信息,然后剩下的部分mask掉,接着用一个编码器编码context得到patch embedding。
编码完以后将需要预测的部分换成 [MASK] token,然后扔进解码器获取解码到的这些patch的embedding。最后对mask位置的真实像素用一个编码器编码,将预测的编码与真实的编码计算L2 loss

在实际训练中,作者先
- 给一个图片随机采样了4个面积占比(0.15-0.2)、长宽比(0.75-1.5)的长方形块作为targets,
- 接着sample了一个面积占比(0.85-1.0)的大长方形块作为context
- 最后将context中和target交集的部分删去,保证不包含target的信息
实验
效果
在实现细节中,作者需要三个模型:context-encoder、decoder、target-encoder。这三个模型都是可训练的、然后都用ViT架构。作者提到了一个训练trick:target-encoder在参数更新时使用EMA移动平均来更新,评价指数0.996……
使用16个A100用时72h就完成了训练。
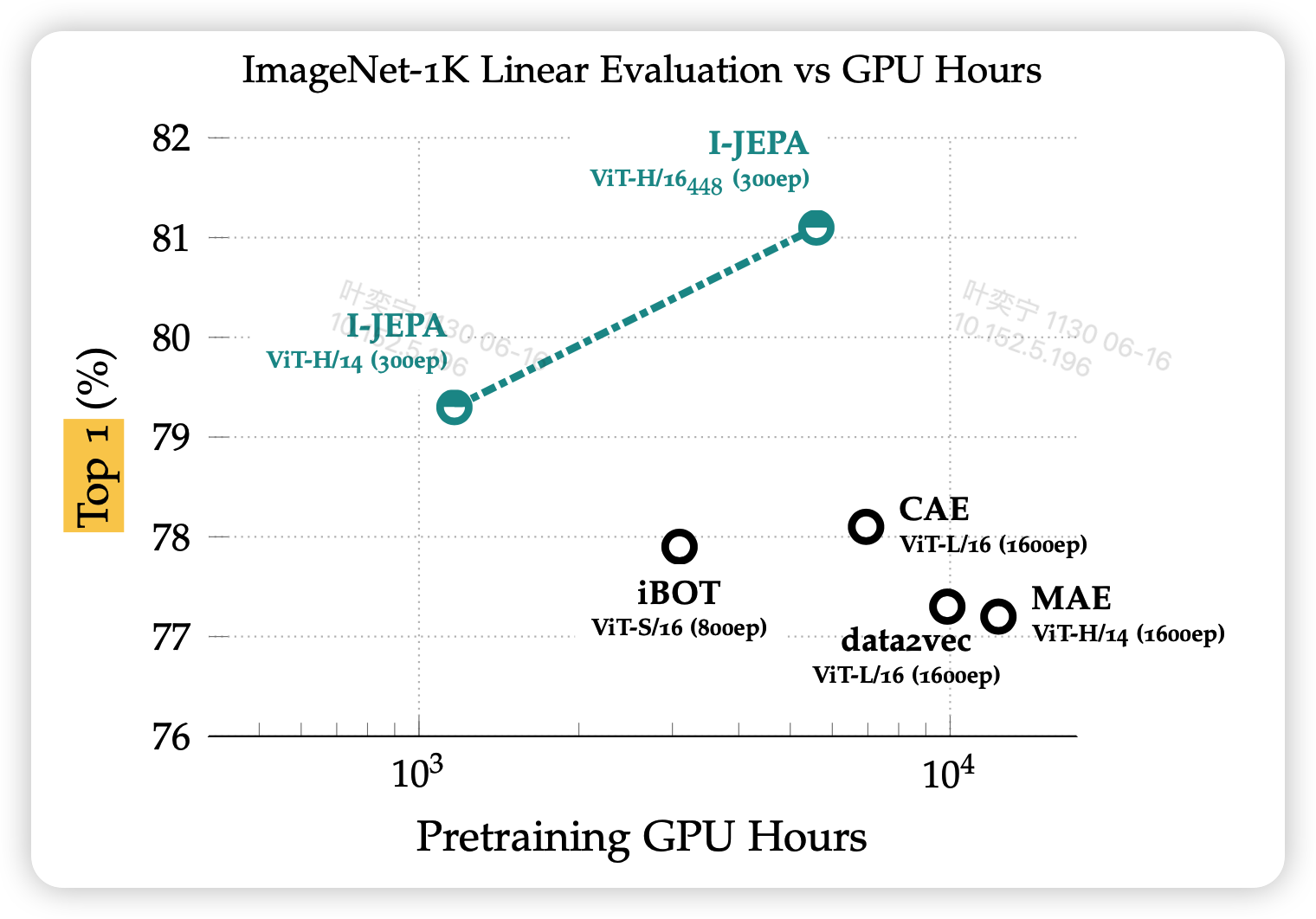
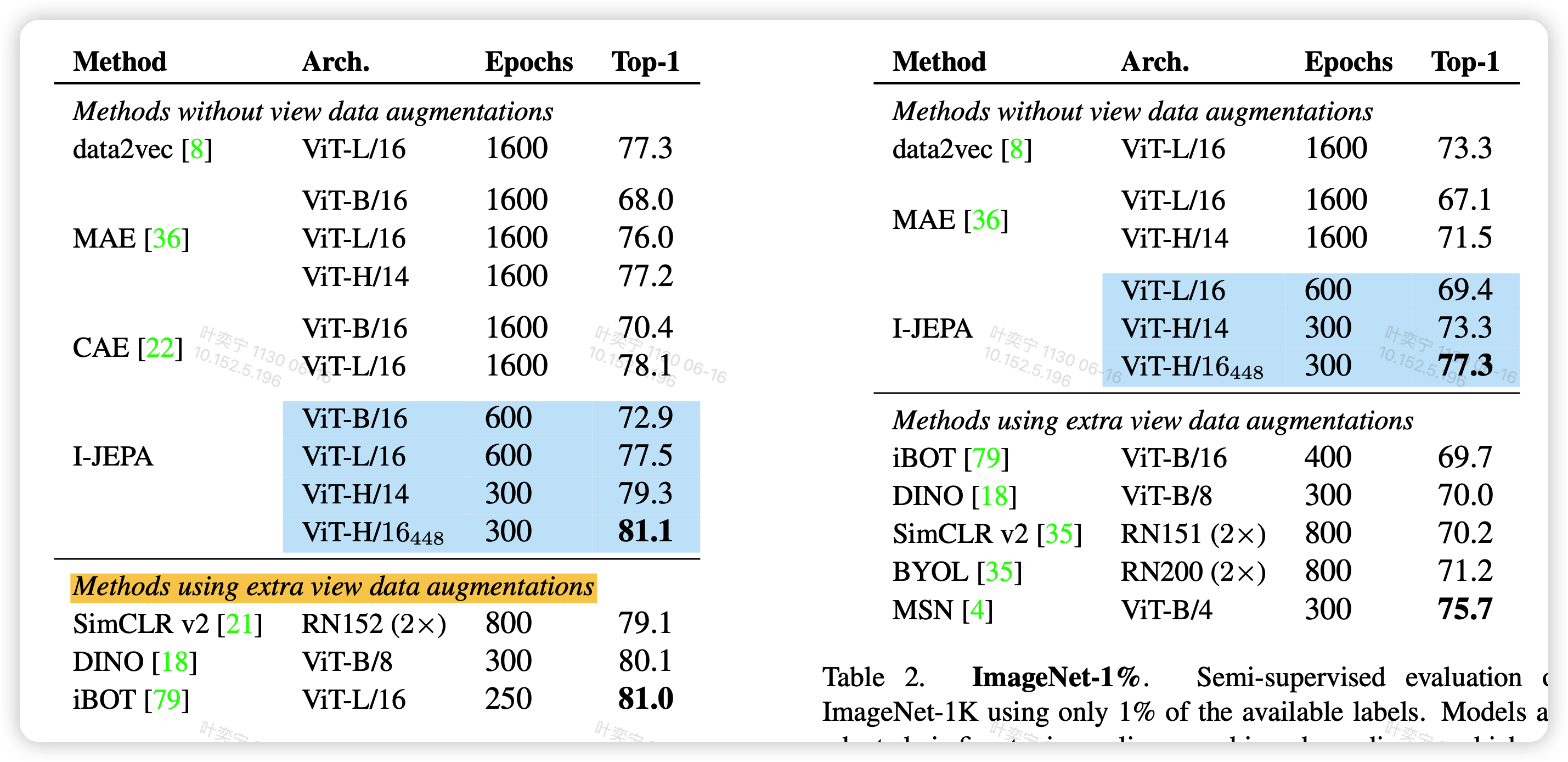
在分类任务上,作者对比了锁参encoder然后加一个linear分类头fine-tune的结果,发现效果很好(左图)
接着,作者尝试了当训练数据只有1%是的效果,发现比起其他模型,效果下降更少,说明泛化能力更强
![]()
然后作者还测试了迁移能力
迁移是指:训练使用imageNet,因此imageNet测试集和训练集是一个数据分布。如果在别的分类任务上测试,数据分布不同,就需要模型有迁移能力
同样是分类任务,和1%数据的分类任务,发现I-JEPA的性能依旧稳定
scalability
- 作者测试了模型规模的影响,发现模型越大,效果越好,和transformer的特性一致
- 测试了训练数据规模的影响,发现训练数据更多,也会使得模型效果更好
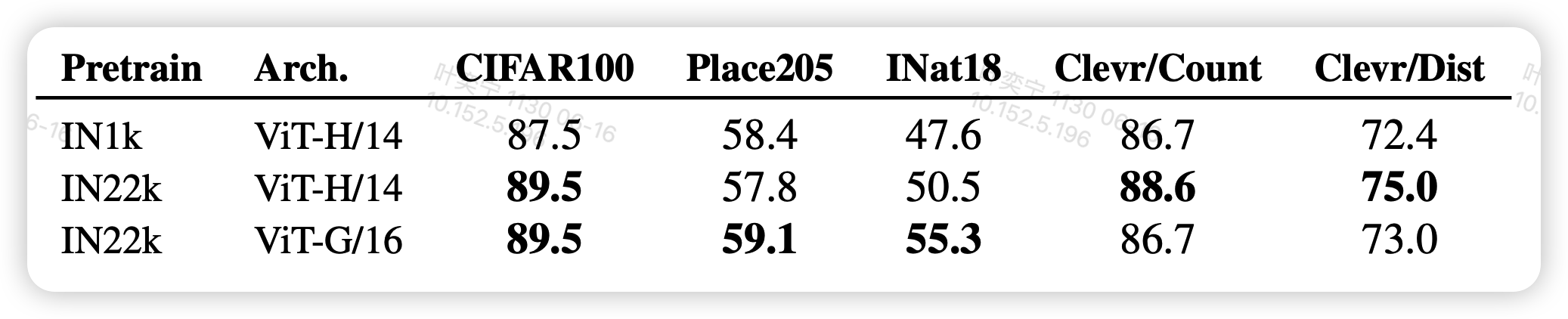
消融实验

作者尝试了不同的mask方法,发现这一套mask的效果最好。我感觉不只是最好的问题,其实这个方法好像对于mask方式非常的敏感,差一点效果会天差地别。(54.2>>15.5)。
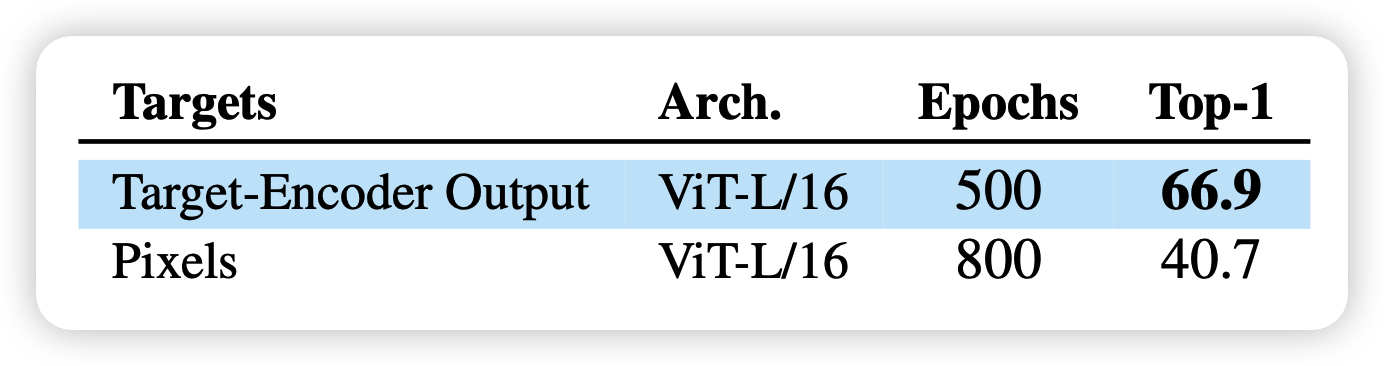
最后,作者还说了之前提到的用像素粒度还是representation粒度计算loss的实验,发现用pixel计算相似度(抛弃target-encoder部分),会导致效果显著下降。不知道是不是因为绝大多数的训练资源花在了计算没有意义、不可预测的信息上。
我的思考
- 作者在提到几种范式的时候,说他们都能用energy-based model的理论去解释。记得之前经典diffusion算法火的时候就有一批研究者和energy-model联系在一起了。我一直没看过这个理论,找个机会读读、讲讲energy-model吧
- 这一套讲故事的逻辑看起来很像T5:先说BERT编码模型xxx,接着说GPT模型xxx。最后来了个"看到一部分上下文基础上,预测剩下的部分"的prefix model
从这里出发,可以思考两个问题:
1.为什么后来的NLP还是decoder-only占了上风呢?
2.按作者的说法,NLP是在物体模态做loss。这种办法的主要问题是模态迁移能力比较差。
LeCun之前一直在推的"世界模型"理论,主要是认为GPT这一套不可解释,不能通向真正的智能。需要让模型有两个能力
- 在多个模态间迁移,真正观察整个世界的能力
- 可以真正做逻辑推理的架构(auto-regressive transformer架构没有显式地给逻辑推理留出空间)
这套JEPA方法上是通过观察世界的一部分信息,去预测剩下部分的语义信息(而不是预测剩下部分)。故事上讲得通,但我没想清楚为什么这会给逻辑推理留出空间??
最后,我们可以简单展望一下
- 首先这个方法不受模态限制,只是这篇聚焦于图像模态(Image-based JEPA),后面显然有多模态版本的。联系一下几周前meta发的那个ImageBind一个模态看所有模态的论文。
- 另外,作者没细说那个mask的问题。我个人感觉,如果图像模态都对于mask方式这么敏感的话,其他模态想调试好估计挺难的。
不过这也符合人类学习的方式:顺序很重要、有效信息很重要?
- 再就是,作者这种三个参与训练的模型的方式,感觉有点不优雅,就像PPO一样?