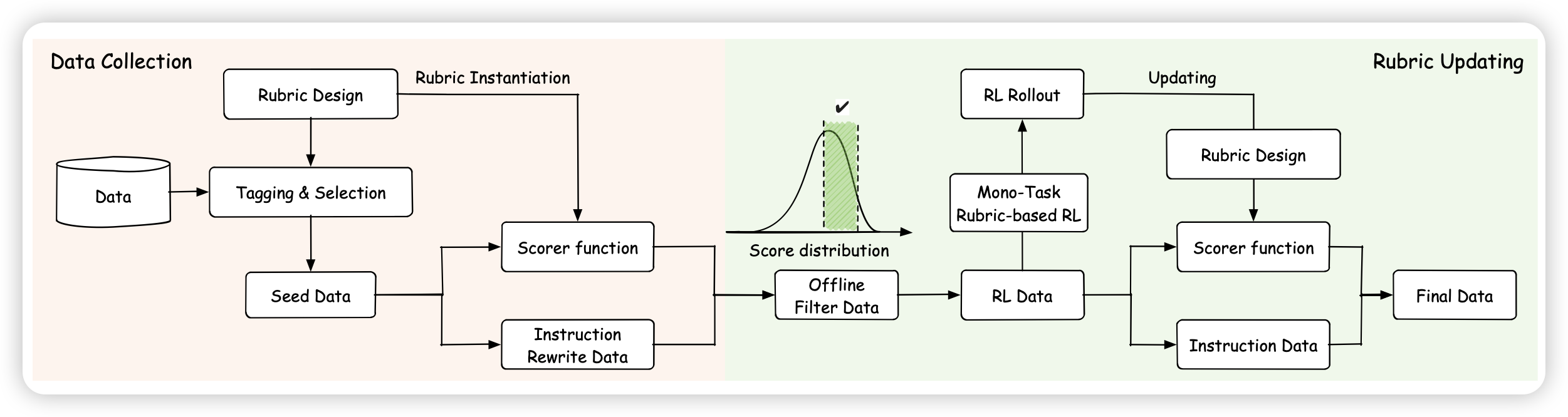
Ovis2.5 Technical Report
阿里竟然出了一个不是qwen vl的vlm。作者做了一个5阶段的训练,包含最后的thinking rl环节
Qwen3-vl还会有吗
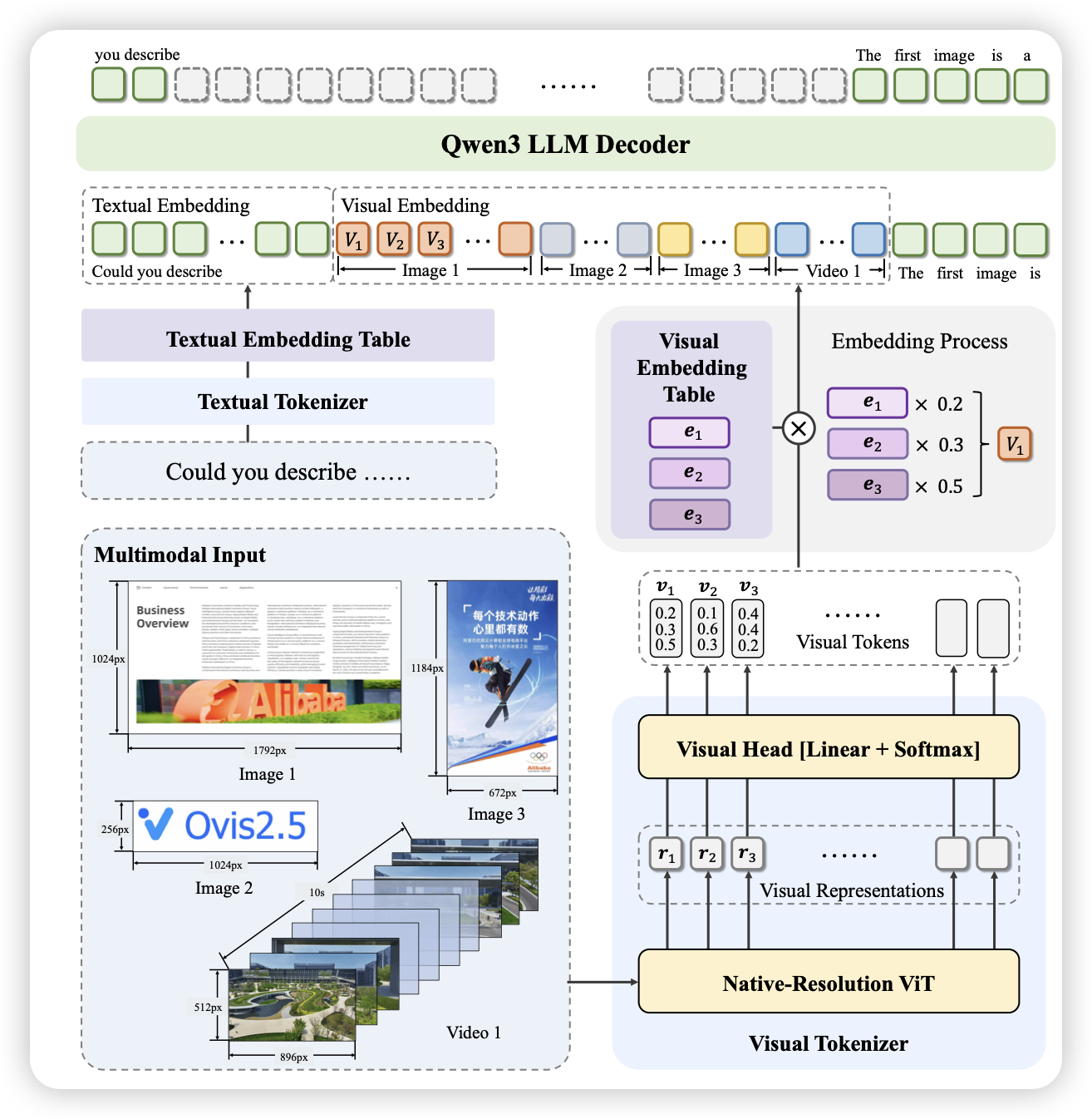
Reinforcement Learning with Rubric Anchors
这是一篇通用领域rl的工作。作者想要把reasoning rl这套搬到非rlvr领域。但是该如何verify任务正确性呢?作者找标注员和模型去一个个任务写评价标准,让模型根据标准给答案打分,以此做了一个rubric-based训练集。