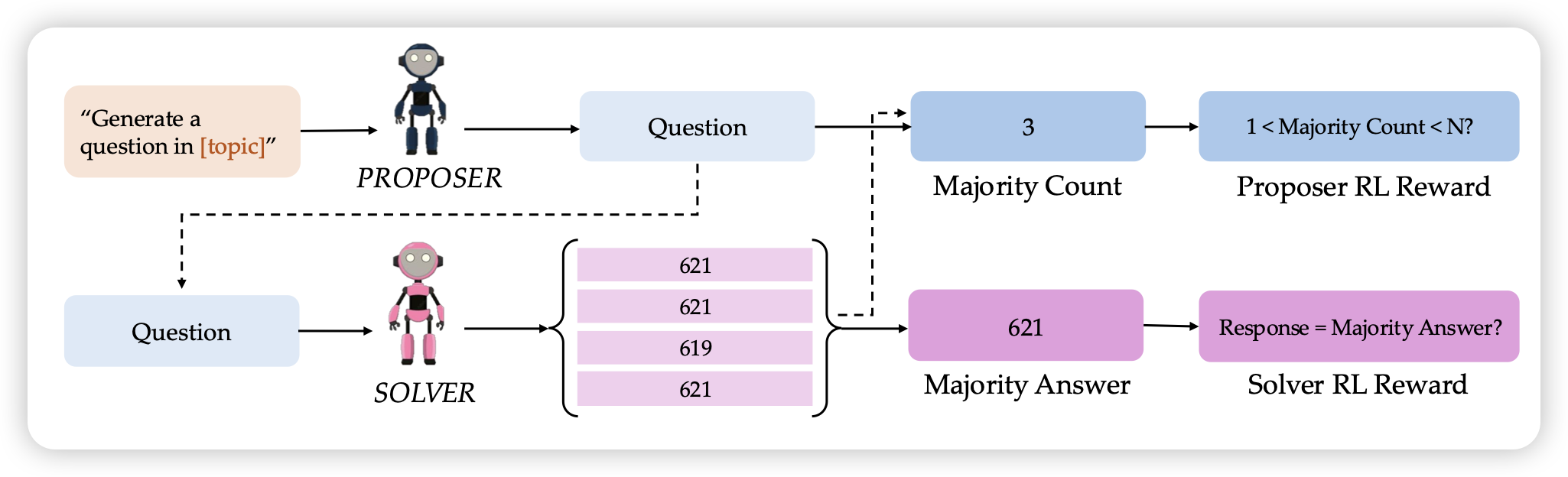
2025-08-06-insights 发表于 2025-08-11 更新于 2025-08-20 分类于 Arxiv-Insights 阅读次数: Valine: 本文字数: 122 阅读时长 ≈ 1 分钟 SELF-QUESTIONING LANGUAGE MODELS 作者提了个比较有趣的训练范式:让一个出题模型出题,然后自己做几遍。通过⬇️所示的方法给双方做rl打分 感觉思路还挺有意思的,就是做的场景有点简单。用rl给出题模型做迭代,是一个很新的东西 相关文章 本月更新(Recent Update) arxiv-insights 2025-11-19-insights 2025-11-18-insights 2025-11-17-insights