Group Sequence Policy Optimization
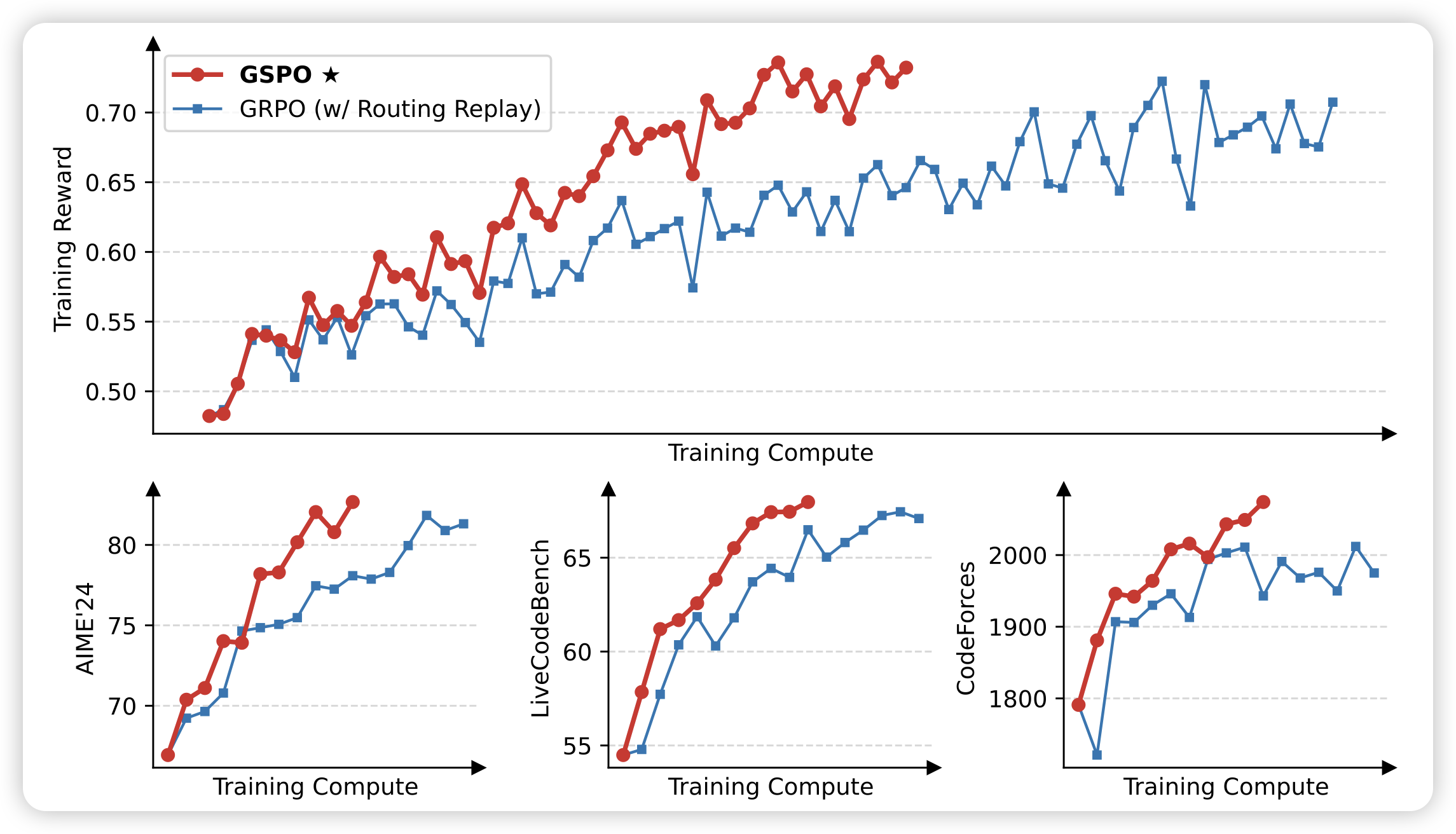
一篇很好的工作,是qwen team讲解了自己训练用的rl算法。作者发现grpo在sequence-level计算advantage,但在token-level做clip,作者认为这个不合理。应该改成先把一个seq的所有token的\(\frac{\pi}{\pi_{old}}\)算出来,然后所有token做平均,完了再e指数作为sequence-level clip。这样可以保证一个seq内的loss更稳定。通过这种方案,虽然大大提升了被clip token的占比,但反而极大提升了训练的稳定性
合理
Revisiting LLM Reasoning via Information Bottleneck
大家都知道rl ppo的时候,一般除了pg loss以外,还会给个entropy_loss,让模型鼓励把每个token的entropy放大,主要是为了防止entropy崩掉。注意这里不是cross-entropy loss。
作者的改进是,把entropy loss部分做一个加权,让每个token的entropy loss乘以adv倍,这样只在有收益的token上鼓励entropy高,别的位置不管,或者鼓励entropy低,按照确定性的方式走
