Kimi-VL Technical Report
昨天火了一把的kimi-vl,今天arxiv挂出来了。激活参数不多,效果也挺好,这篇report里罕见的还比较开放,数据构成、比例啥的都说了
看起来kimi是打算走开源路线了吗
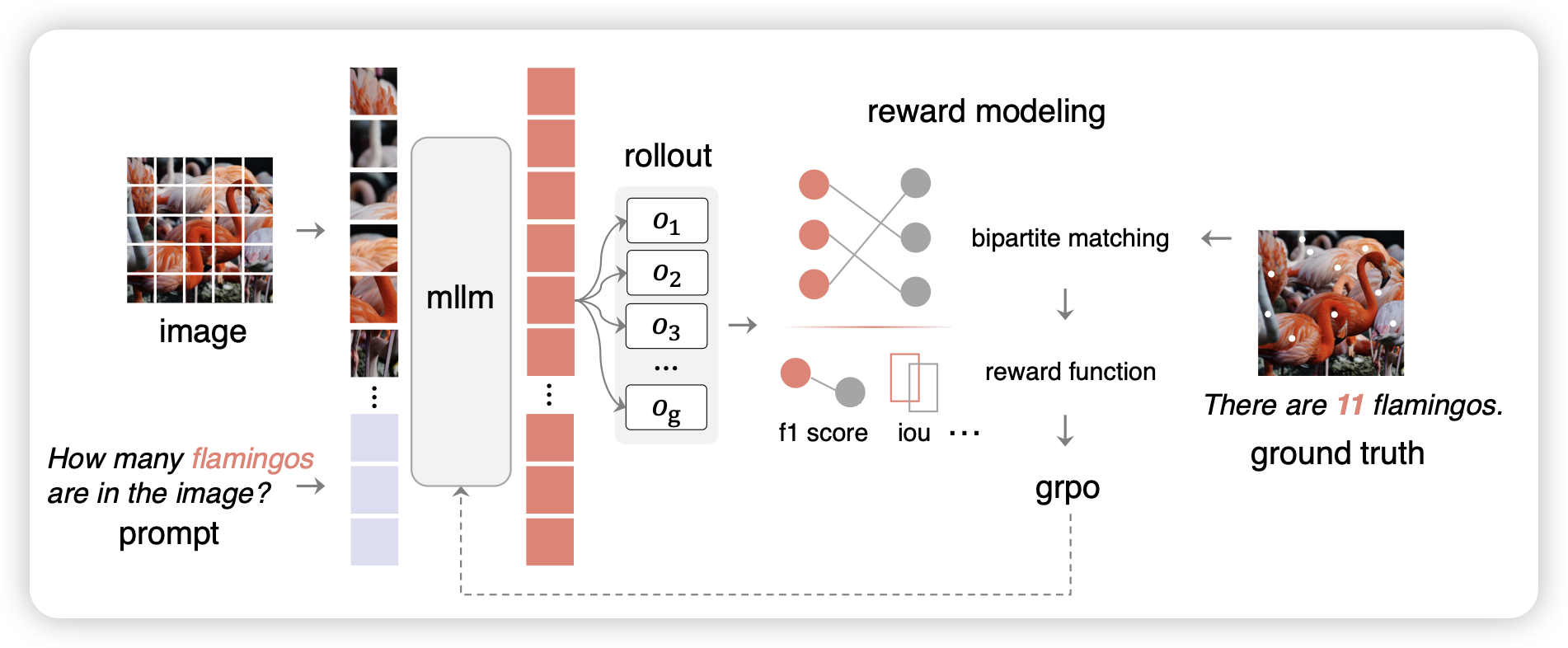
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
前几天有个叫ui-r1的工作用rl增强grounding能力,今天来了一个general vlm的版本。作者发现,影响得分的主要原因在于。trainset里面的grounding truth往往不止一个,如果对训练框架做一些魔改的话,是可以效果很好的。
话说rl reward这里,有假阴和假阳两种错误情况。不知道rl算法对那边的误差更敏感……似乎没人探索过这个问题。像math场景,就假阴比较少,假阳比较多;这个场景我理解是假阴比较多,假阳比较少