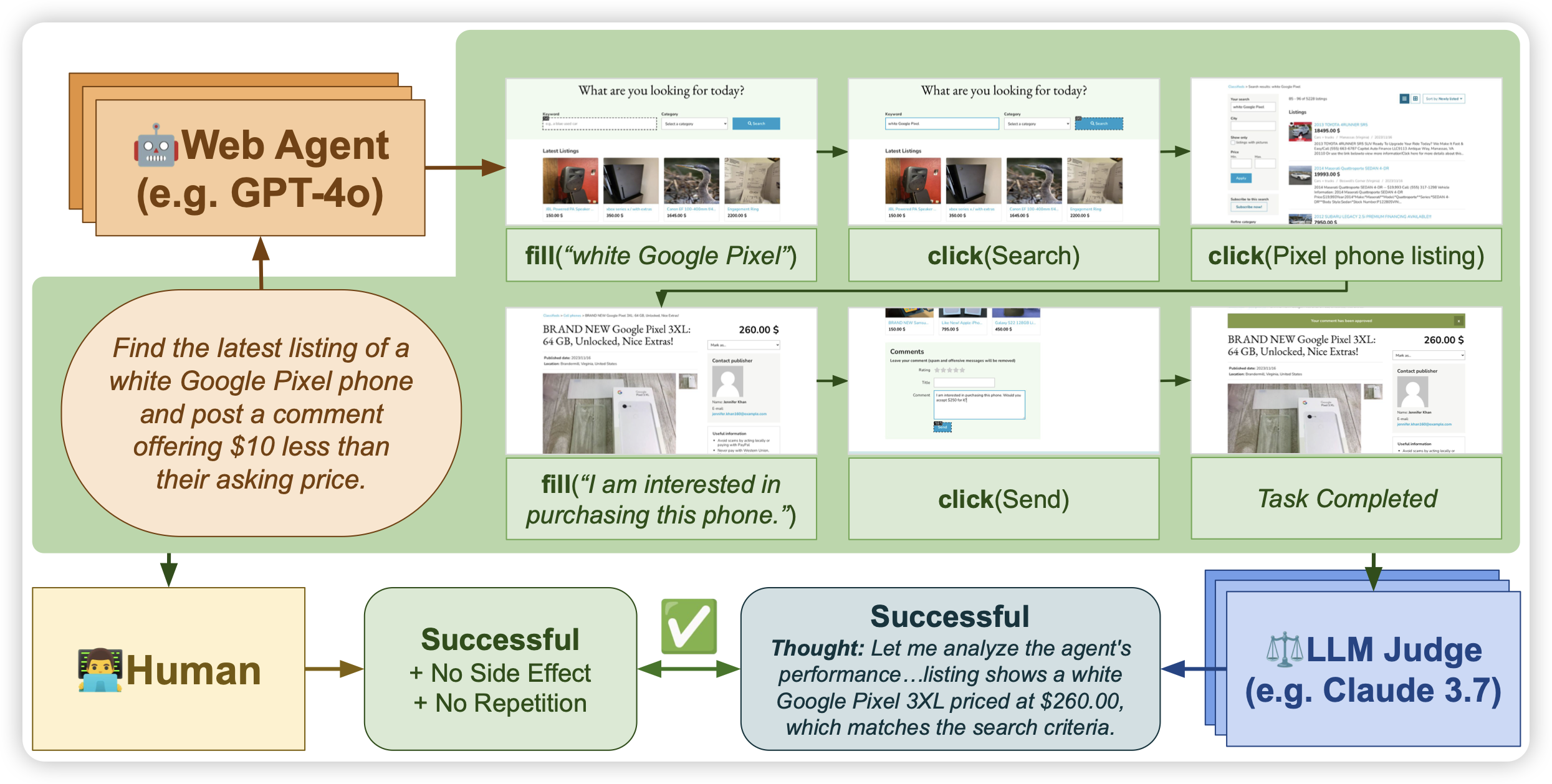
AGENTREWARDBENCH: Evaluating Automatic Evaluations of Web Agent Trajectories
一篇有趣的工作,这里作者不关注gui agent的性能,而是去关注能不能对trace进行打分。作者找了一堆benchmark,一堆agent做出来了trace,然后让人打分,最后实现了一些rewarder,和人算一致性。
今天刚看了shunyu的the second half,感觉这类reward工作以后会越来越火的
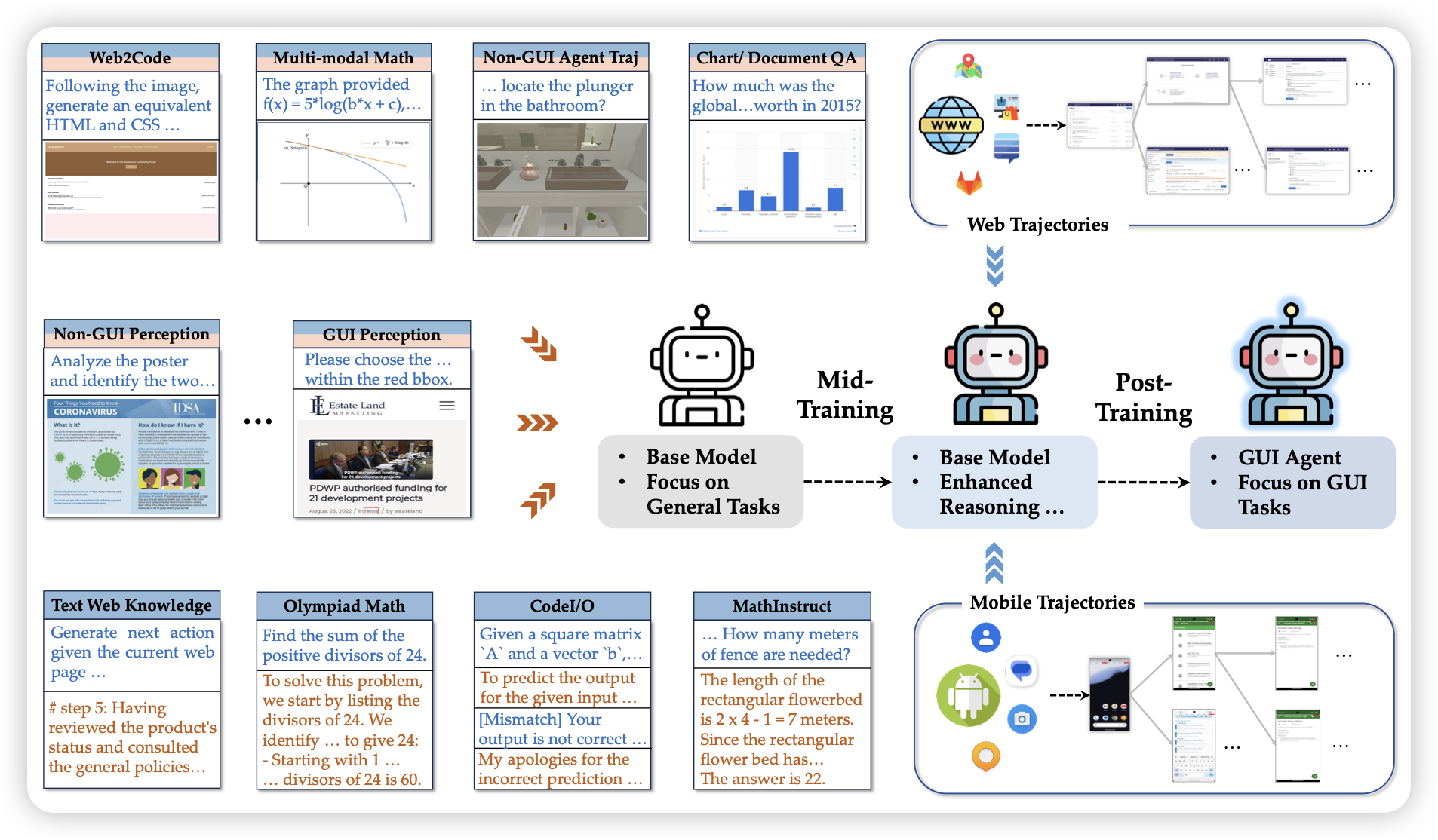
Breaking the Data Barrier – Building GUI Agents Through Task Generalization
这是一篇探索gui agent model训练的工作,做得还挺solid的。作者纵向对比了不同类型的vlm训练数据对gui agent场景到底有什么影响,发现:math/code对gui有帮助,gui perception反而对gui agent没什么帮助。
我们之前做ui-tars,加入了教程数据,如果这篇对比一下gui tutorial的帮助就好了