Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Kumar参与的工作,在agent setting上,作者定义了两个tes time scaling的维度:单个step内的thought长度,还是单个step里thought少,但是step多(test-time interaction)?作者发现相比之下,后者的效果更好。由此,作者设计了rl算法,使得agent可以在训练过程中逐渐增加action budget
感觉好像claude讲过一遍这个故事了?

MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
这篇工作的思路比较有趣,作者认为:完成Agent任务时,既可以通过gui键鼠操作来完成,也可以通过MCP工作调用来完成。只是由于任务不同,天生对于不同的接口有不同的支持性。那么,能不能day1就搭建一个同时支持两种方案的评测集,这样就可以公平的对比MCP-Agent、GUI-Agent、Hybrid-Agent了呢?
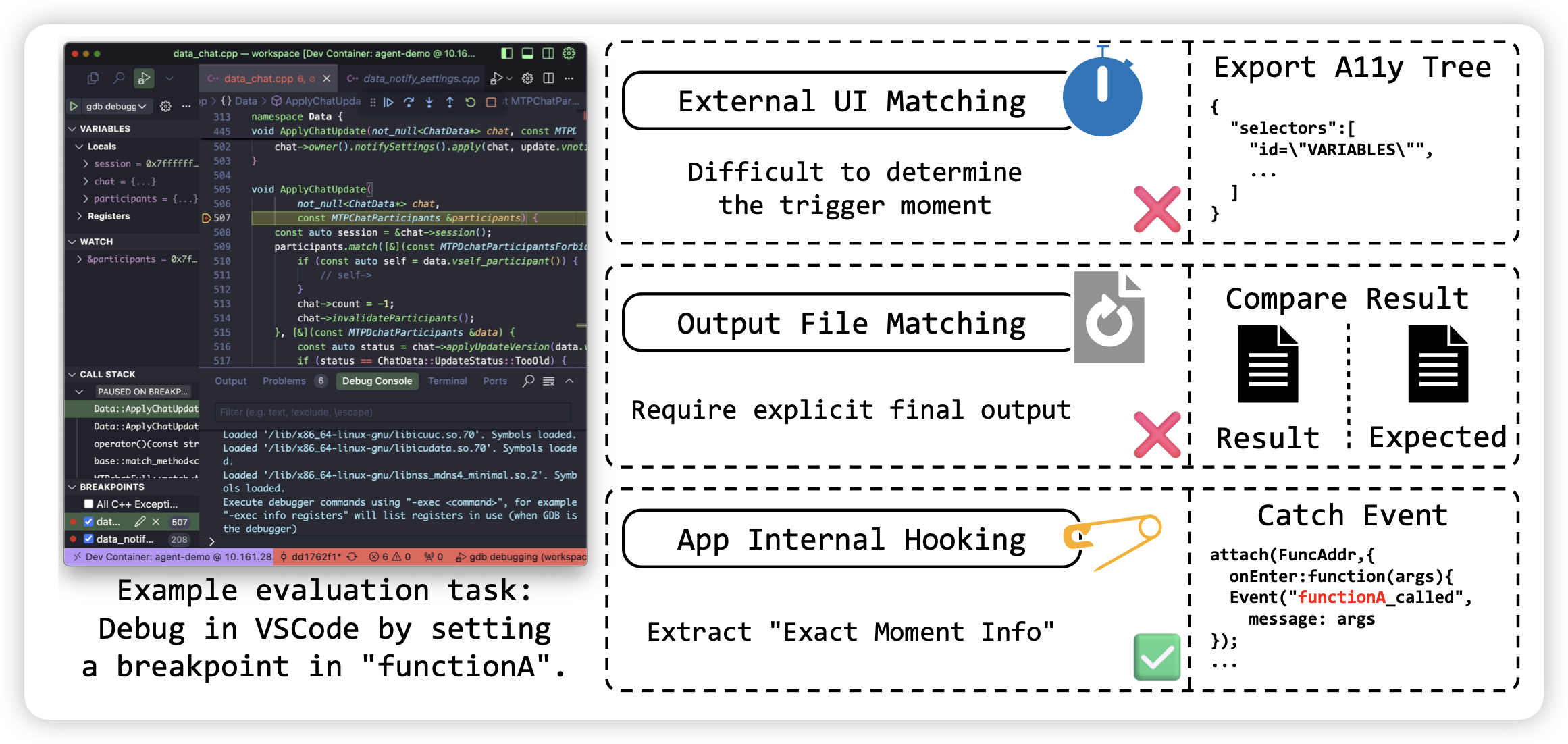
GUI-Reflection: Empowering Multimodal GUI Models with Self-Reflection Behavior
一篇GUI Agent领域的工作,作者具体focus在reflection的行为上:当遇到问题时,能不能发现错误并纠正之前的问题。对于正常的human-sft数据,基本上trace里每个步骤都是正确的,这会导致模型根本没见过错误恢复的数据,online推理时一旦遇到问题,就难以纠正。作者想到的方法是,直接拿sft数据里,构造“犯错”的步骤,让模型学着去恢复。
