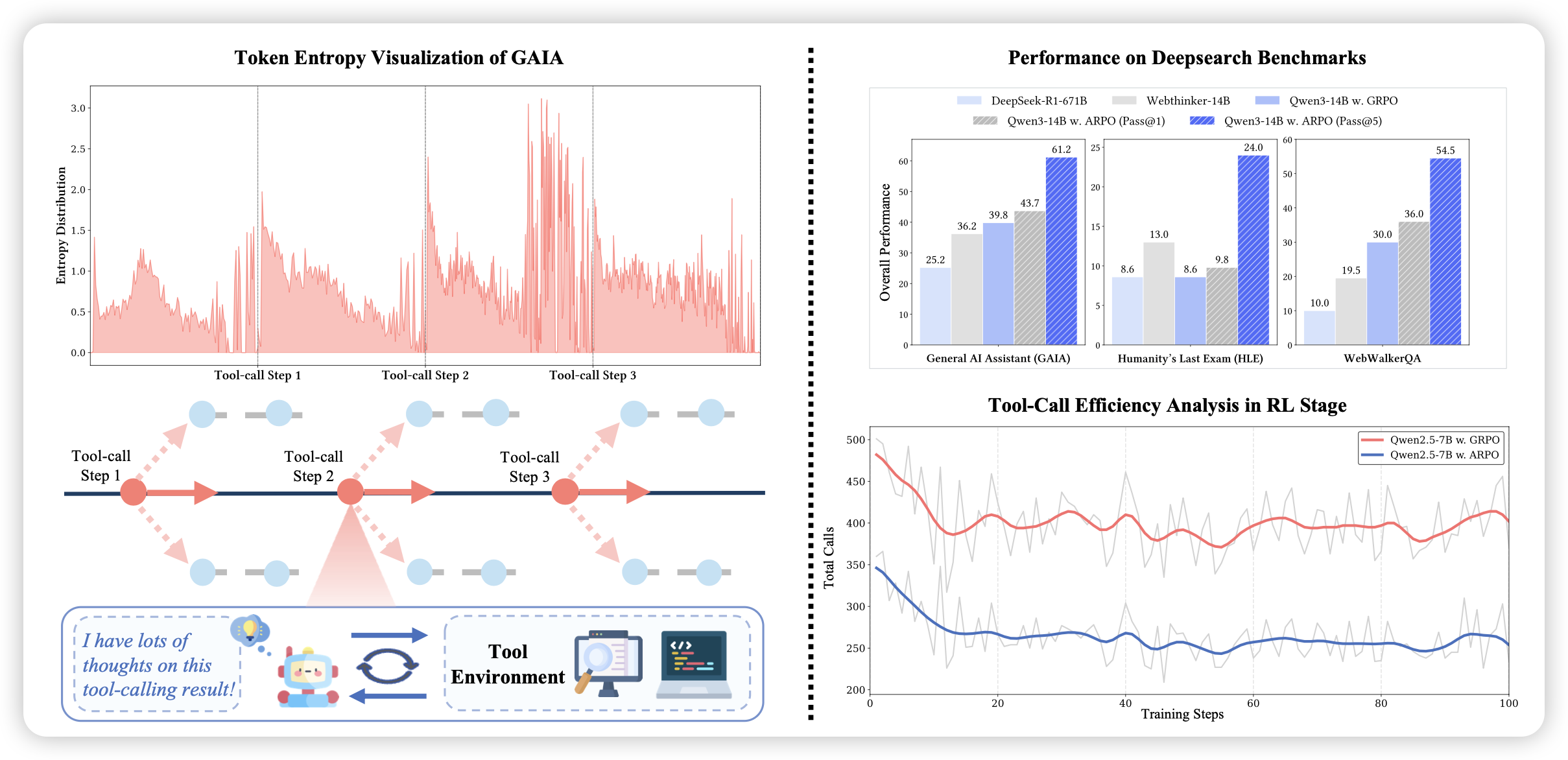
Agentic Reinforced Policy Optimization
这篇工作比较有趣。大家还记得前段时间seed发布了一个,根据entropy的高低,在最高的几个地方fork出来新的rollout,来提升在high-entropy地方的采样效率的工作(First Return, Entropy-Eliciting Explore)。这篇工作,作者推广到了agent场景,发现在工具调用结束,刚看到tool-output的地方,特别容易entropy很高。所以作者复刻了这个fork方法,在fc-agent场景取得了比较高的采样效率
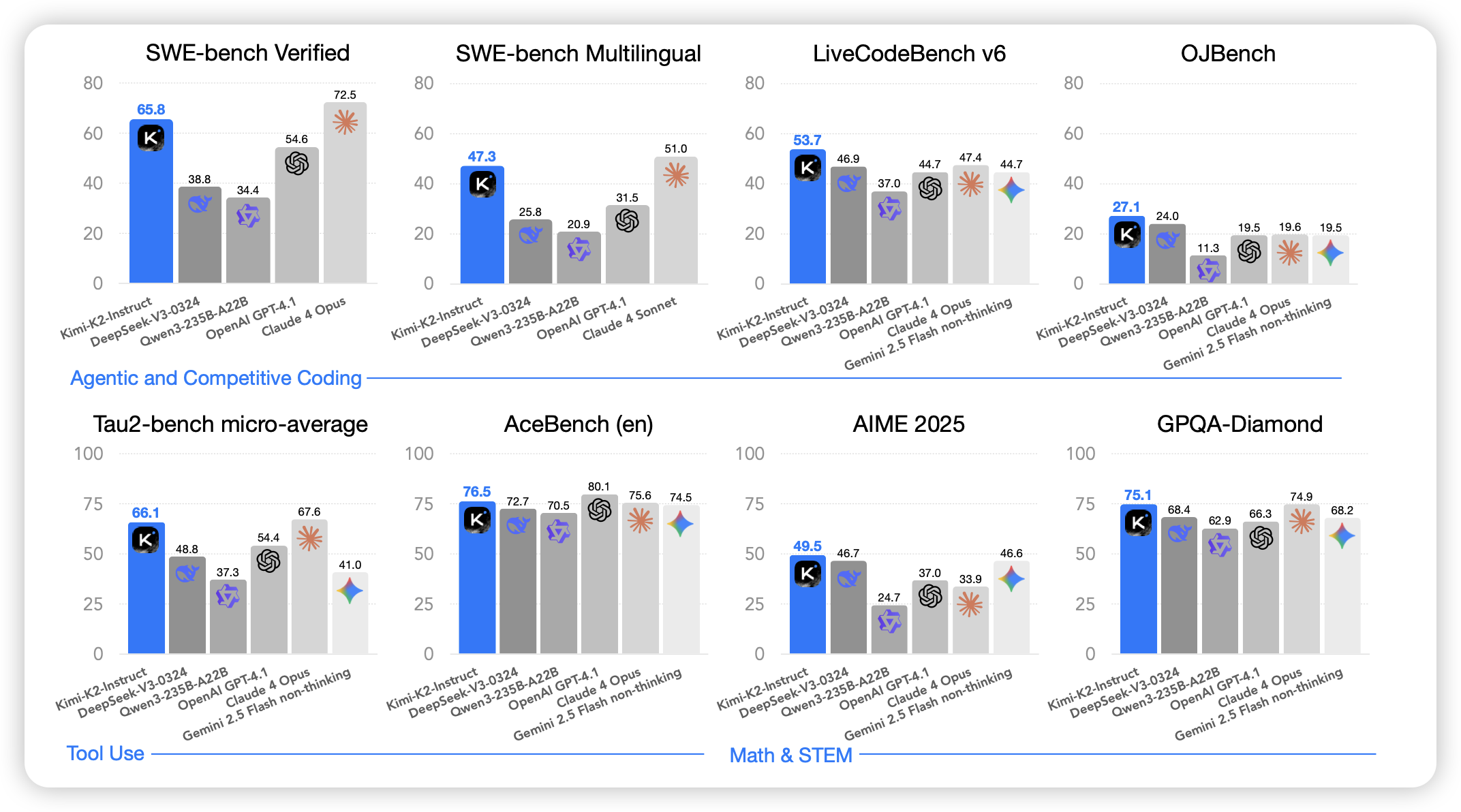
Kimi K2: Open Agentic Intelligence
K2 report,在twitter上火了好久,今天终于上arxiv了。作者训了个很稀疏的1TB总参数模型,在下游训了多轮的text-only agent rl。
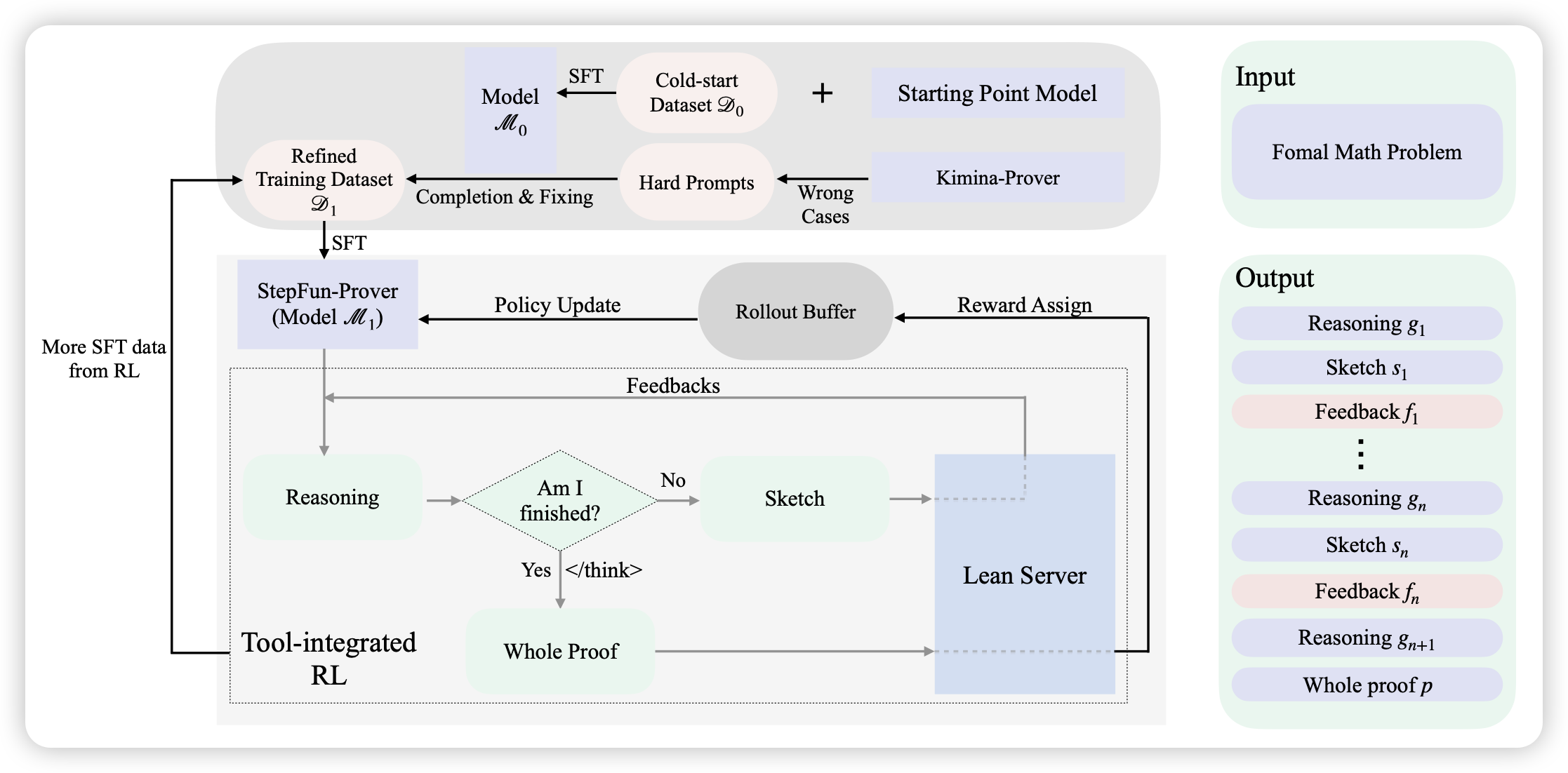
StepFun-Prover Preview: Let’s Think and Verify Step by Step
一篇lean4模型的rl工作,但作者建模成了多轮,每轮都可以生成证明、或者refine,变成了一个类似swe-agent的形式。通过这种agent框架,把lean4的sota又往上抬了一格