Shuffle-R1: Efficient RL framework for Multimodal Large Language Models via Data-centric Dynamic Shuffle
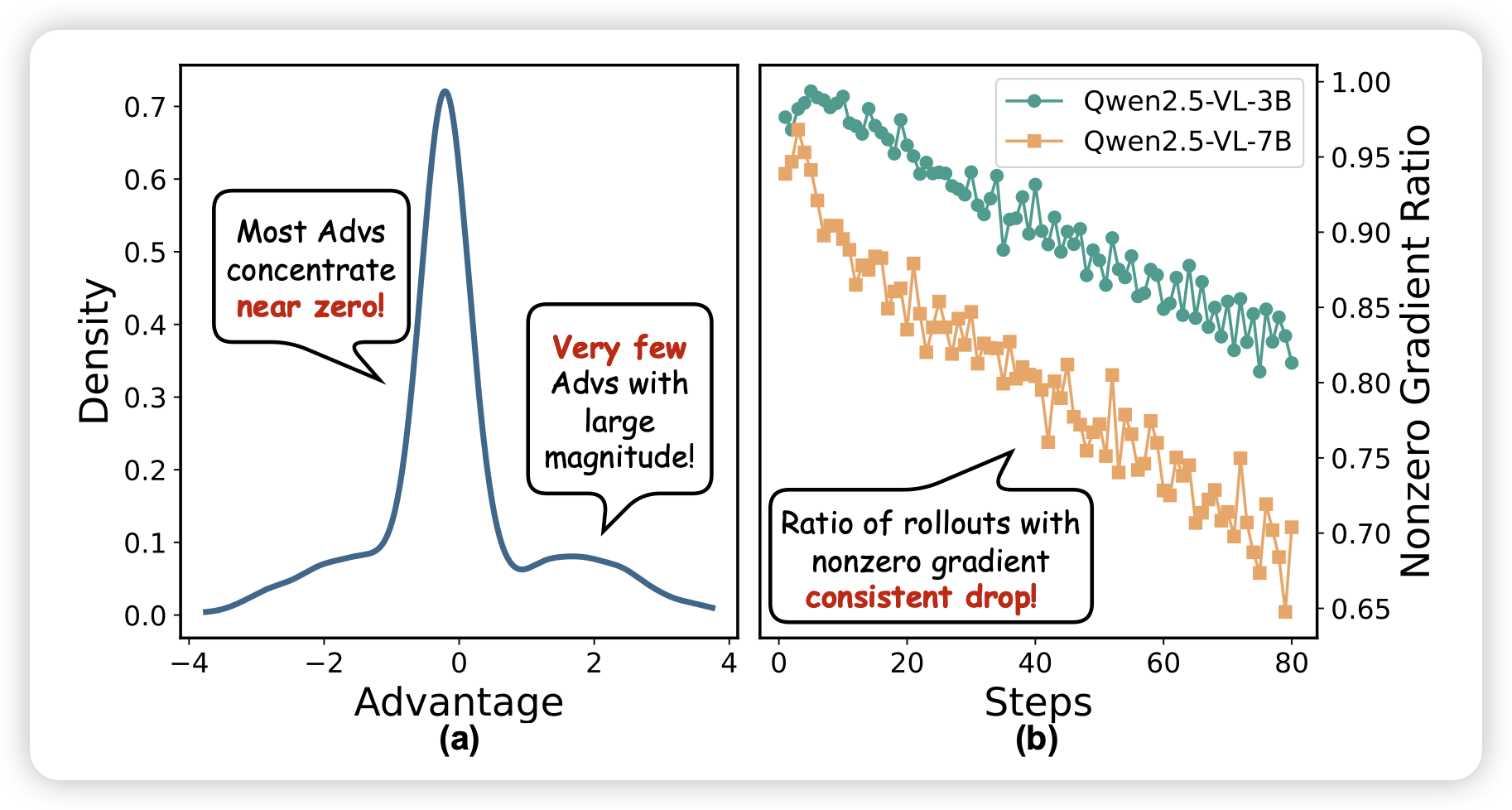
这篇论文谈到了grpo中的dynamic sample问题,只有一个题目同时有做对/不做对的才会训进去,随着训练这个比例会越来越低,导致训练效率越来越低,大部分样本都被drop了。作者的大致解决思路是:加入一个经验池,里面评估了之前做过的各种题目的一些信息,然后通过这些信息决定下一次roll哪些数据,而不是从dataloader直接采。