半年没写论文阅读笔记,其实笔记草稿写了不少,都没转正。主要觉得像是机械的翻译,没有思想在里面,不如不发。最近大家开始陆陆续续放出来o1-like的模型了,其实翻过头看,大家的思考方式还是几年前的STaR,去年我也写过 一篇阅读笔记 介绍。
今天不妨来重新思考一下STaR,连接上跟进的几篇STaR-like的工作,谈谈我对于o1的理解吧。参考文献:
- STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
- Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
- Training Chain-of-Thought via Latent-Variable Inference
- Rest Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
- Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering
- Training Language Models to Self-Correct via Reinforcement Learning
本文的展开顺序不是上面任何一篇论文的写作思路,而是会有一个自己的行文思路,穿插上面论文的实验和思考。
几年之前,我和一个数竞的学弟交流,我问他:你是怎么学数学的?当时他的回答很有意思,大概是说:
我在脑子里有一套自己的知识组织的方式,和老师教的不太一样。每次做题的时候,我需要先把题目按照自己的那套组织方式"捏"在一起,然后就自然想通了做法,后面的时间主要花在"怎么把自己的想法翻译回证明过程"上。
这会带来一个问题:每次看到新数学证明的时候,需要花比别人长很多的时间去理解,把他们的整理按照我自己的组织形式去理解一遍。一个定理理解不了,所有用到这个定理的其他定理都成黑盒,也理解不了。还没人可以问
听起来很哲学,像个现编的小故事,但这是个真事。我当时很惊讶:同样一份数学,在不同人眼中可以有不同的定义和理解方式,这些"方式"可以互相翻译、对齐到大家都认可的一个经典文本证明空间去。
——现在想想,这就是o1,或者说STaR。
“Old-School” STaR and its reward-hacking problem

STaR算法的流程,四句话总结:
- 找到一堆数学题(含有题目和答案)
- 每道题让模型sample好多次解答
- 按照答案正确分去分好坏样本,认为答案正确的样本是good-datapoint。
- 把好样本训回去,变成model@2
他的方法其实还有另一半,对于做不出来的题目使用guide-distribution,这半边在后面的follow-up工作中,都验证是无影响甚至负收益,就略过了
没有更多了,就这么简单。听起来很美好,但是STaR其实有几个问题。都是比较本质、不好缓解的问题
STaR没有对thought做监督: STaR算法的流程,其实没有核验thought的正确性,而是根据答案的正确性去给thought质量做一个反馈。这里面有个美好的假设:答案正确了,过程一定是对的。
如果一道题目只训一遍,这就是对的,STaR里确实只迭代了一轮。然而,一般情况下,我们不会遇到这种"题目溢出"的情况,都会希望一道题目可以利用很多次。如果模型第二次见到同一道题目,可能会出现reward-hacking的情况:thought随便说一个,然后把正确答案背出来。这就坏了。
Sampling Diversity Degradation: 还是刚才那个reward-hacking问题,即使不背答案,也很可能会是把之前一轮的"好样本"过程再背一遍,毕竟训过了一遍,肯定会以高概率再说一遍的。每次都找正样本来,肯定会导致diversity越来越差的。

(reward hacking meme)
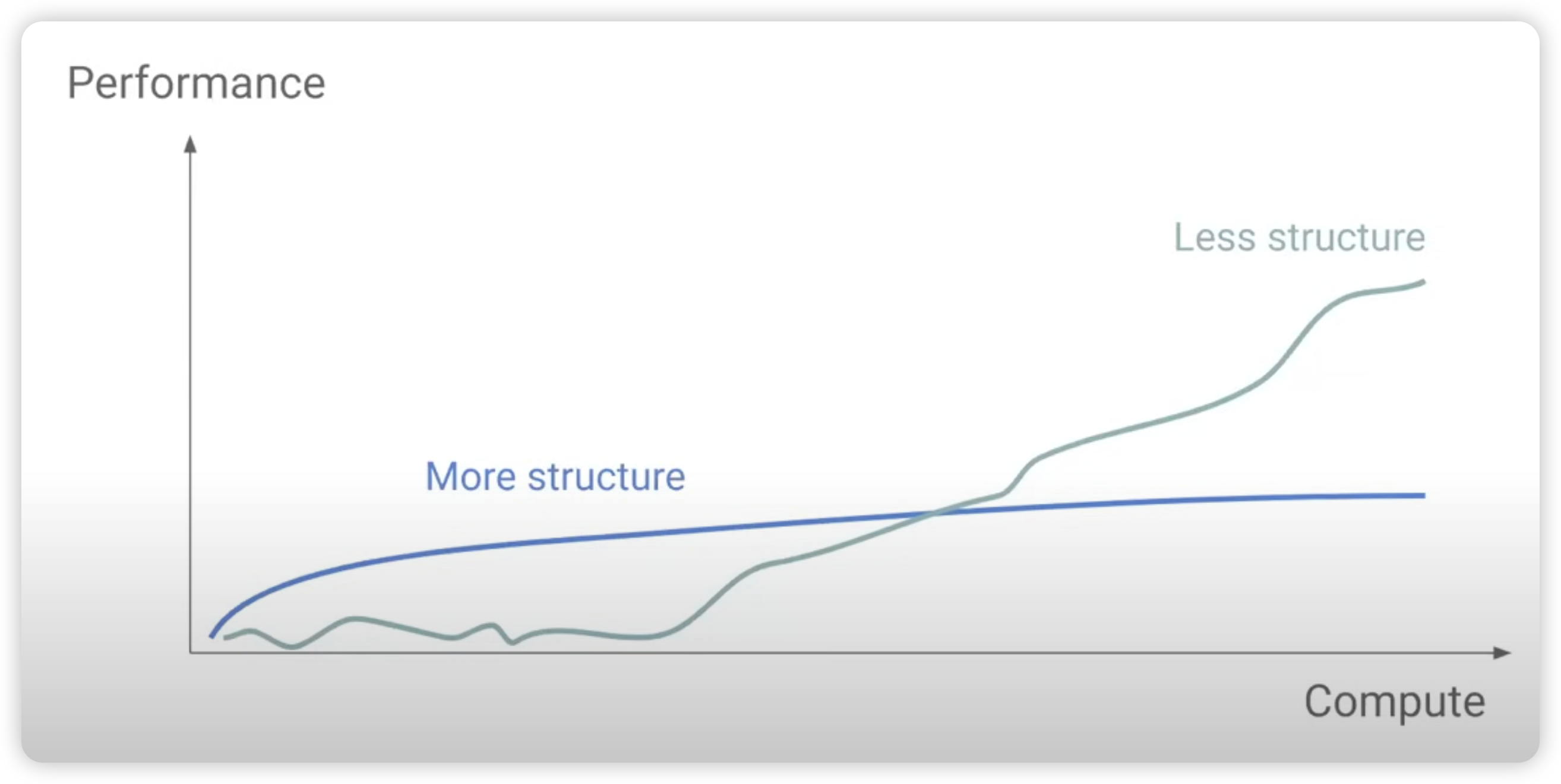
So, will "Just Scaling" works on STaR?
我都能发现的问题,Ilya肯定能发现。Ilya的想法是:对thought作监督!所以做了一篇let's verify step by step (可以参考这篇笔记)。我训一个PRM,给模型每一行证明都打一个分。如果模型随便说一个thought,就会发现prm的分数有突变,然后就能发现有reward-hacking了呢?
Ilya的定义里,prm@step_n代表着截止到第n步的胜率。本质是RL里面的value,而不是advantage,这个后面有工作探讨了优劣(OVM、PAV)。
这条路线是否可行?没有人知道答案,我其实倾向于不可行。因为越是强的系统,越是不可预测(人只能预测自己能力范围内的事情)。alphago move-37,全世界没有人预测到,它就不好吗?prm指标突变,可能只是policy系统超越了prm系统的上限。昨天Ilya在NeurIPS talk上说了一句耐人寻味的话:More reasoning is more unpredictable. Reasoning is unpredictable, so we must start with incredible, unpredictable AI systems.
回到刚刚的问题上:STaR会reward hacking,是不是代表着STaR的scaling性质不好,不可行呢?其实重新思考一下,可能恰恰是因为STaR没有做scaling,所以才有这个问题。所谓reward-hacking,其实是模型的"背诵答案"回路,和"学会推理"回路之间的博弈(我后面统称system1 knowledge&memorization 与system2 reasoning),当数据规模小时,system1学习更快、更讨喜。但随着规模的增大,更泛化的system2会渐渐胜出,因为他有统计意义上的优势。
模型可以背下来5000道题目的答案,但是如果是5000亿道,还能背下来吗?一个200B的模型就能记住这么多事,随着题目增加,记忆能力捉襟见肘,开始遗忘;反而是用system2的方式可以节省参数、不会遗忘,最后会渐渐胜出。
(题外话)如果大家感兴趣的话,可以阅读"grokking"和组合泛化研究方向的工作,他们在寻找和对比AI中的不同的learning pattern,对于所谓的思考回路、记忆回路有更明确的讨论。比较好的工作:
Explaining grokking through circuit efficiency
Unifying Grokking and Double Descent

STaR总体上,是鼓励system2的。因为他给了模型一个机会去使用reasoning token,或者讲:把系统变得更scaling,让模型可以用test-time scaling(我的意思是,你可以不用thought,仅仅做reward-hacking背答案;但你也可以选择用thought,总之我给你了这个功能)。当计算规模上来以后,即使概率很小,模型也总能误打误撞地慢慢发现使用thought的好处,逐渐的把使用thought的能力推广到整个训练集上。
"STaR" the entire training-corpus will leads to o1?
我们再打破一个砂锅,想深一层:STaR只能做数学题吗,数学题这个场景有什么好处?可被验证!类比一下np-hard问题。解决一个数学题很困难,但验证正确性很简单,甚至不需要模型,这种方案一般称为functional verifier(我仅仅指答案对比的题目,不是证明题)。所以,我们其实都不需要orm、prm这一大堆东西,找到一堆带答案的题目就够了,不用管题目本身是不是特别困难。
其实数学题这种pattern,在训练数据里是大量存在的,只是他们没有被建模出来,之前Jason Wei提到了训练数据中极度不平均的信息密度,都是预测这些token,但显然很多token的预测很简单,剩下的token预测很困难。模型有没有办法的自适应的增加计算量,来把数据集的信息密度重新变得平均呢?这就是o1。
事实上,如果我们想到了一些办法去衡量训练集的信息密度,然后把信息高密度区域转换为可以被验证的类数学题的qa形式(functional verifier),那么其实就能把训练集按照STaR的方式学习。随着模型在"练功房"里持续不断地思考、试错,渐渐会形成一套自己的方法论(可能和人类认识世界的方式完全不同),用自己的方式去理解数据中所有的知识、推理的问题,并按照自己的见解对他们进行重组,最后变成适合于每个模型自己的long-cot训练回参数里,永久记忆。这就是我理解中的"合成数据"。
所以,nvidia的新单子bh200集群,把cpu:gpu的比例从4:1调整到2:1,就是为了方便OpenAI在CPU上部署更多functional verifier吗 [doge]
这两篇twitter涉及到了对于information density有更详细的讨论
https://x.com/_jasonwei/status/1855417833775309171
https://x.com/_jasonwei/status/1729585618311950445
传统意义上,大家可能会觉得:知识不是推理,用o1也没有用。这个观点的前提是“纯靠system1就能把知识全记下来”,但人的背诵也不是查表,否则就不会有“记忆宫殿”之类的一系列方法了。对于模型,即使训练语料就写着“中国的第八大城市是xxx”,但其实你也可以用一些更low-level的知识推导出这些结论,比如“北京有xxx km^2, 上还有yyy km^2....所以第八大城市很可能是zzz”,只需要记住基础知识,就可以在运行时随时再推导回来。具体哪些知识会被深刻记忆,那些知识会被学习成“基础知识+推理”的形式,就可以是模型自己决定的了。你不需要监督和关注这个内容,他们本身也是无法预测的。
所以,"what is reasoning?"是一个不太scalable的问题,更好的方案是假设: everything is scalable, and we can observe relative benefit on all subset.
from Data Engineering to Verifier Engineering: Align system1 to system2
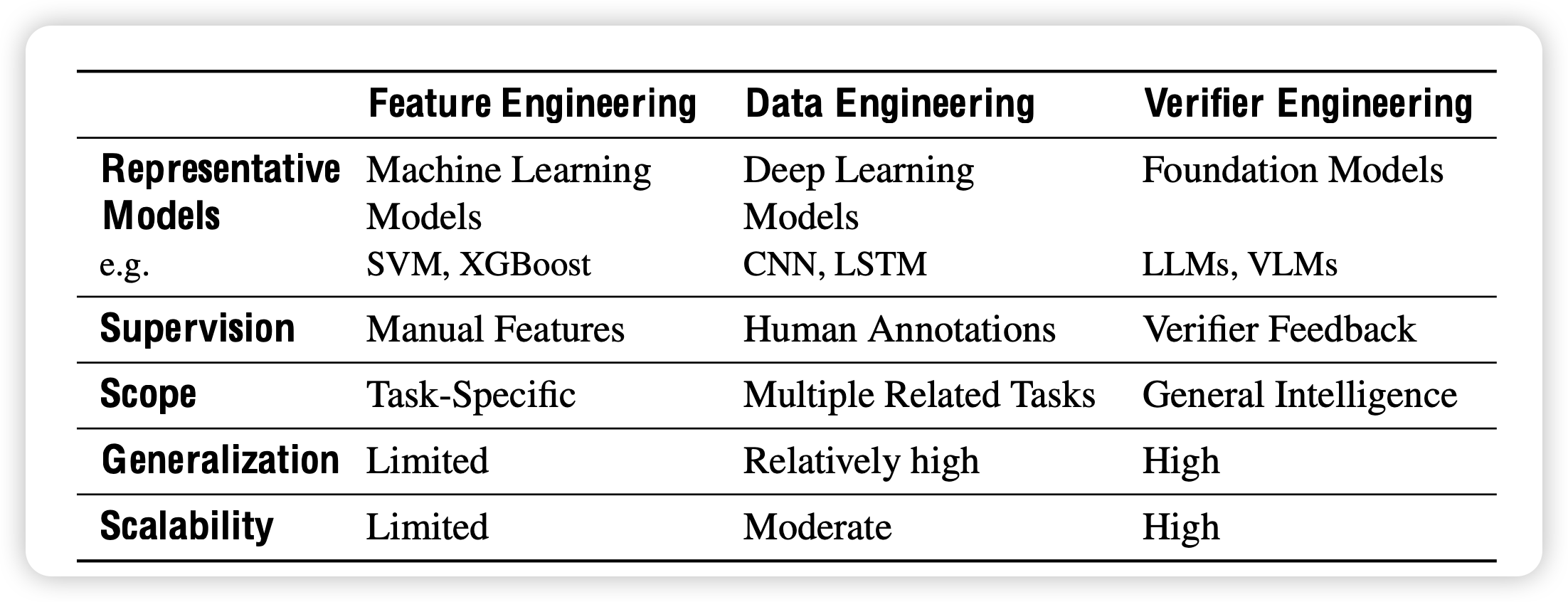
在讨论这个问题时,已经代表了一种范式的转变——我们从GPT3、GPT4时代准备数据(Data Engineering)的思路,转变成了现在o1时代准备问题和答案(Verifier Engineering)。
在我的理解里,之前大家准备数据,主要是假设所有模型可以用同一套方案记忆这些知识,用一套方法论去推理。所以只需要拷贝一份数据,就可以从头把一个模型"hash"出来。但现在,大家逐渐发现不同模型是有独属于自己的记忆方案的:小模型和大模型记忆数据的能力不同,代码模型和文本模型对推理的倾向性也不同。仅仅靠data engineering,训出来的模型效果并不理想,因为这份数据并不是属于他的,而是全人类的智慧结晶,或者说是人类思考方式的平均数。
反而,准备verifier,让目标模型自己探索出解决这些问题的方案,就是在激发模型按照自己独特地方式思考、去理解每条数据背后的思想:是什么思路,导致亚里士多德说出这样的话的? 两种方案的目标是一致的:都是为了解决一个问题集上的所有问题。但实现方式完全不同,verifier 方式需要更多的算力,但会激发一个更定制化、更可扩展的AI系统。
可以想象,如果我在10000道题目中背下来了解答过程,假如第10001道和前面差得很远,那其泛化性堪忧。但如果我形成了一套方法论,并且验证我的方法论在10000道题目上都有效,那我只需要按照我的方法论去解决10001道,成功的概率确实不小。如果这套方法论已经被验证适用于所有的20TB token训练集,那么它的泛化性,可能就是LeCun所谓的世界模型了。
参考"Incentivize, don't teach"演讲里面的说法:
prepare data实际上是: teach him how to fish
prepare verifier实际上是: teach him the taste of fish and make him hungry。他会学着开始去使用渔网、去查看天气,等一系列技能,即使我们从未教过他这么做。
从诗意的角度理解:data engineering是给模型设计一套最好的课程;而verifier engineering是希望模型从头扮演人类历史上的每一个智者,重走人类发展的老路。站在巨人的肩膀上,肯定不如自己成长为巨人来得实在。我无法想象,如果一个模型从头的、一个人的、重新的、推导出和发现了世界上的所有定理和知识,那现在他该有多聪明,还有什么问题能难倒他持续不断地思考。
另外和data engineering一样,verifier engineering也是一劳永逸的,你只需要准备一次verifier,就能无限地训练不同的模型,每次再拿出来那些verifier就好。商业公司的秘密,可能也会从私有化数据,转变成私有化verifier。区别是,之前偷过来训了数据,可能不用花很多钱就能复刻一个训练;现在偷过来verifier,想复刻一个的价格仍然是天文数字,而且需要你的training infra支持训练,(比如bh200这样2:1的cpu:gpu配比)。
Wait, another thought: more concrete problems in o1 discussion
这套大方向的思路其实是形而上学的: 你既不能证实,也不能证伪——训练成功或者失败都有办法解释。可能需要关注于一些更具体的问题:
- dataset re-sample: 如何把训练集的所有问题都变成functional verifable的。或者退化地思考,能否训练一个ORM,在所有情况下,达到90%的准确率?
这个问题可能是整个o1系统里最基础、但也是最困难的部分。现在好像没人在解决这个问题,都是在做数学、classic-reasoning场景。大家的想法是:我先做数学场景,反正数学可以functional verifier,把低垂果实先摘掉。等谁把这个问题的解法开源出来,我再切换过去。是不是很像2023年初大家等alpaca 52k的心情[doge]
OpenAI是怎么做的?我有点怀疑他们是PRM,要不然为什么会推出reinforcement fine-tuning功能呢?
- dataset re-order: 即使我已经找到办法,把训练集退化成了1000亿道题目,我怎么知道这些题目中,哪些比较简单、哪些比较困难?
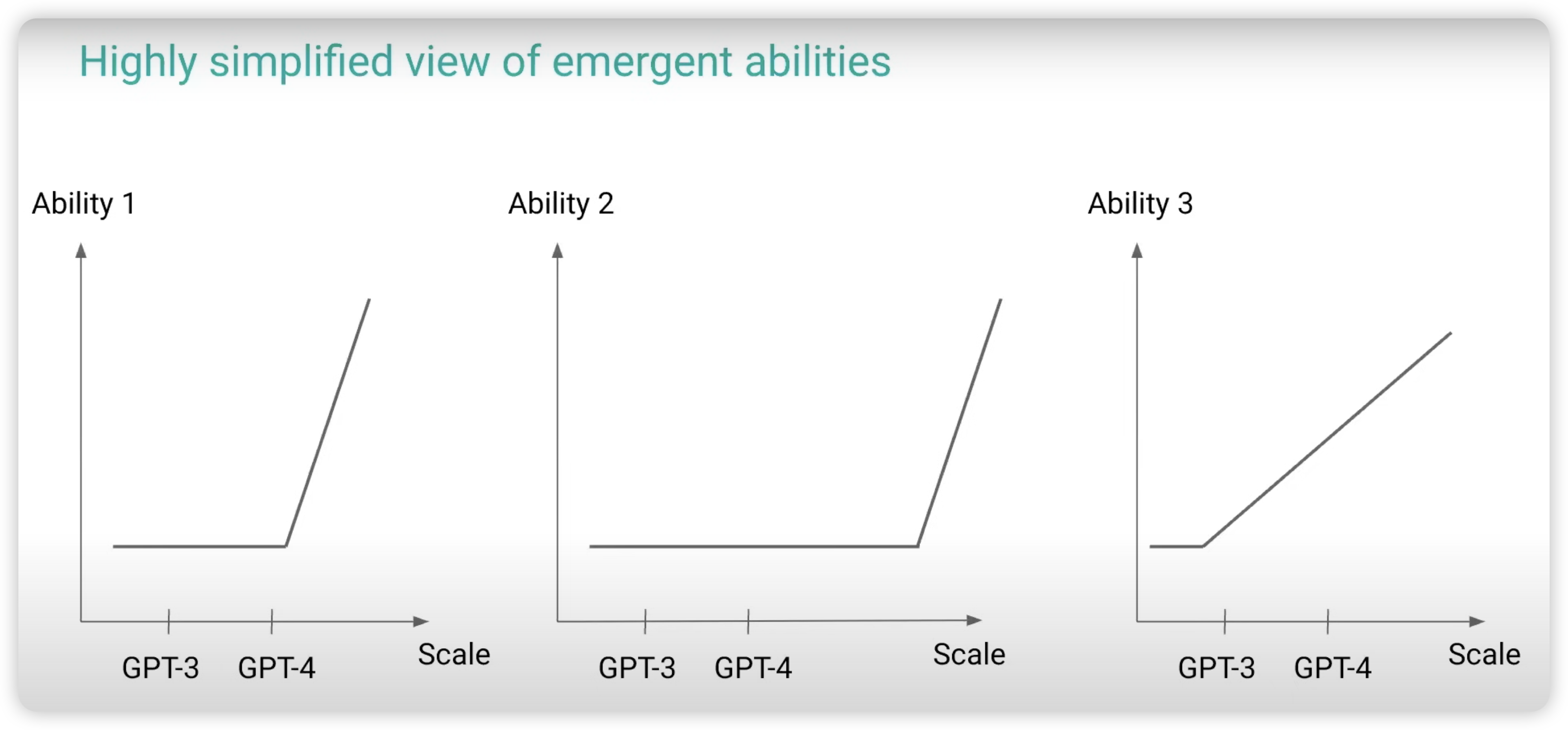
这是一个很有价值的问题,因为你可以想象,有的题目我sample 16次就有答案,有的题目我sample 1024次才有答案,有的题目我sample 100万次才有答案。如果我不sample,就永远不知道需要sample多少次。而我现在期望的是,只sample 1亿次,然后把尽可能多的题目学会。这里面其实一套课程学习的思路,我能不能想办法对题目的难度进行分类,然后让模型先在简单的题目上尝试,把简单题目学习得大差不差了,再去难一些的地方尝试。所以,我们可能需要每时每刻找到"即将Emergent的能力"。从数据效率的角度来看,之前需要sample1000次的难题,现在可能只需要sample 100次了),如果找到一个好的顺序,可能他可以节省好几万倍的算力。
可悲的是,"顺序"对于不同的模型还是不同的:比如我恰好数学悟性好,随着训练我很快就能学会高中数学;但我不擅长语文,语文的能力就涨的特别慢。想要把所有题目提前按难度分类好,永远存下去,可能还是不可行。就得每次随着训练不同模型,专门去给他设计顺序。
有些人会想:我用PRM行不行,先sample 100次,看看prm最高分大概是多少分。我看来,这里面也有个大问题:虽然题目解决了,我可以发现他解决了,但是如果没解决,我怎么知道距离解决还有多远?甚至是说,判断一个题目的完成度,在我看来比完成这个题目还要困难!
幸福的家庭都是相似的,不幸的家庭各有各的不幸。——托尔斯泰
之前大家讲"generative-verifier performance gap",就是说模型作为verifier的能力更强,可以给policy model提供训练信号。问题在于,这个讨论没有考虑"policy + search"的情况!我只知道"verifier > policy"和"policy+search > policy",但是我其实需要的是"verifier > policy+search",我的verifier能区分我sample出来的1000个样本里,最好的两个样本谁比谁好吗?这个结论甚至可能是错的。(假如是小于,那所有的rm-based method都要寄了)
- forawrd-method: 如何去高效地搜索试错?假设我已经把数据集做了re-sample, re-order,搞好了verifier。那接下来我该怎么设计一个sample算法(在搜索领域,可能更好的翻译是rollout efficency),提高算力利用率?
这里面又有好多设计了,o1刚出来大家说: OpenAI 用的是ToT,math-shepherd那套,有好多工作去定义出来"reasoning-module",或者说"reasoning-atomic"。后来又觉得不像,又说要录音,把人的思考过程录下来,让模型学着模仿。再后来,大家发现需要所谓的o1-distilled seed-reasoning data去启动,然后直接按照temperature sampling的方式去搞。那么openAI是怎么搞的呢?总之它肯定不是蒸馏的o1的推理数据
- backward method: 假设我已经rollout出来很多的reasoning数据,都给出了附加得分,接下来怎么训回模型?STaR其实是提供了一个最原始的方法:丢掉坏数据!后面大家有人会做得更优雅,比如把坏数据加个负数loss?把训练搞得再稳定一些以后,你就发现竟然重新推导出来的DPO?
openAI是怎么做的?大家都猜测是PPO,大抵是因为PPO的作者现在在openAI。从头到尾,秘密行动[doge]。我个人倒是感觉这个问题可能不太难,把前面三个解决好,可能最后这里随便用一个算法也不会太差。
我的思考
期待谁放出来第一篇提供全栈解决方案的、开源数据和模型的论文!到时候给大家分享阅读笔记
另外,我还有几个问题:
- 对于"o2"的思考:如果我已经训练了一个o1(不妨假设他是200B),他磕磕绊绊终于找到了一套理解世界的方案,现在我想启动一个2000B的模型,我知道这个2000B的模型很可能在大多数问题上靠背诵就解决了。那我200B的o1可以对他的训练提供什么帮助呢?
能不能把phi-4做一个o1版本的呢?
既然文本模型可以做o1,sora可以吗?生成物理世界时,如果物理规律很难以把握的话,是否可以通过测试时计算,描述畅想一下需要遵循的规律,再生成呢?
模型的thought,一定要是文本吗?是否可以不把内容对齐到推理空间呢?目前大家要使用word embedding这个概念,是为了计算crossentropy,但如果我们在backward算法上,刨除掉对于reasoning token的loss,只监督output。那么我们可以在thought部分干脆不对应到词表里了?退化地讲,即使对应到词表,也不一定要是现在的词表吧。目前的词表是根据预训练预料的n-gram频率算出来的,我们为什么要假设推理token的词频分布需要和预训练数据的分布一样呢?比如模型总是说"let's think step by step",那这可以是一个token吗?更高的pre-compression rate,其实是在提高算力利用率的。
openai似乎很多年前做过一篇相关的博客Learning to Communicate。我还挺期待模型什么时候可以做一个赛博坦语的thought,最后说出来一个"注意到xxx"把哥德巴赫猜想证明出来[doge]