RM-R1: Reward Modeling as Reasoning
有一篇generative-rm的工作,最近勃发出来很多类似的工作

FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
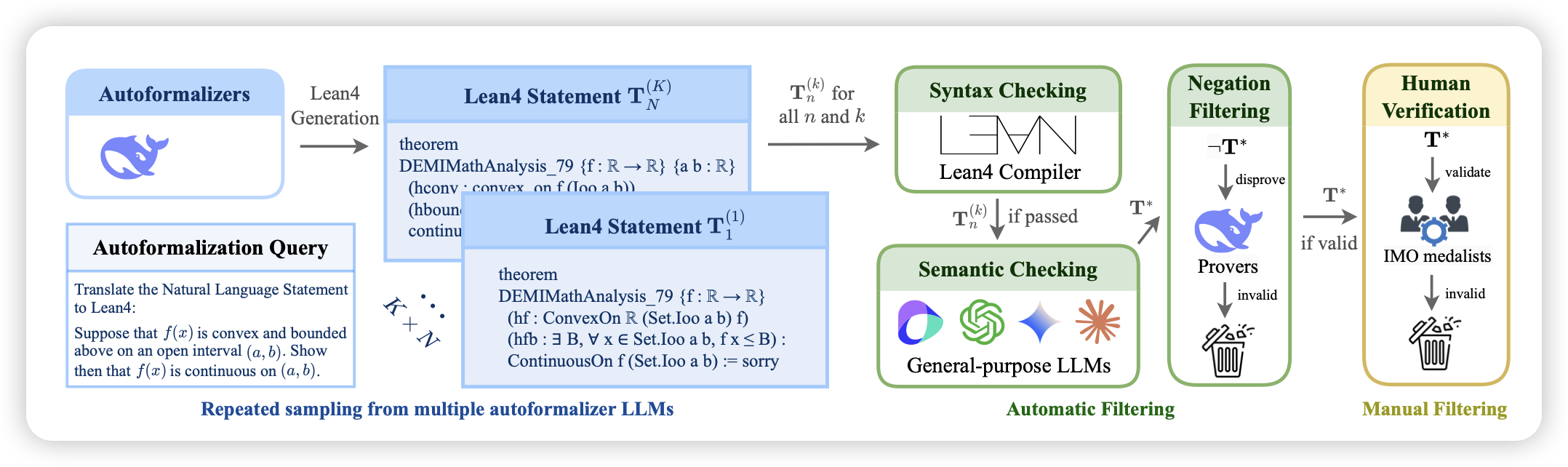
一个lean4数学证明的数据集,前几天deepseek刚出了lean4的模型,当时他们没有测试集,这次就搞了个几千题的测试集出来。
有一篇generative-rm的工作,最近勃发出来很多类似的工作
一个lean4数学证明的数据集,前几天deepseek刚出了lean4的模型,当时他们没有测试集,这次就搞了个几千题的测试集出来。