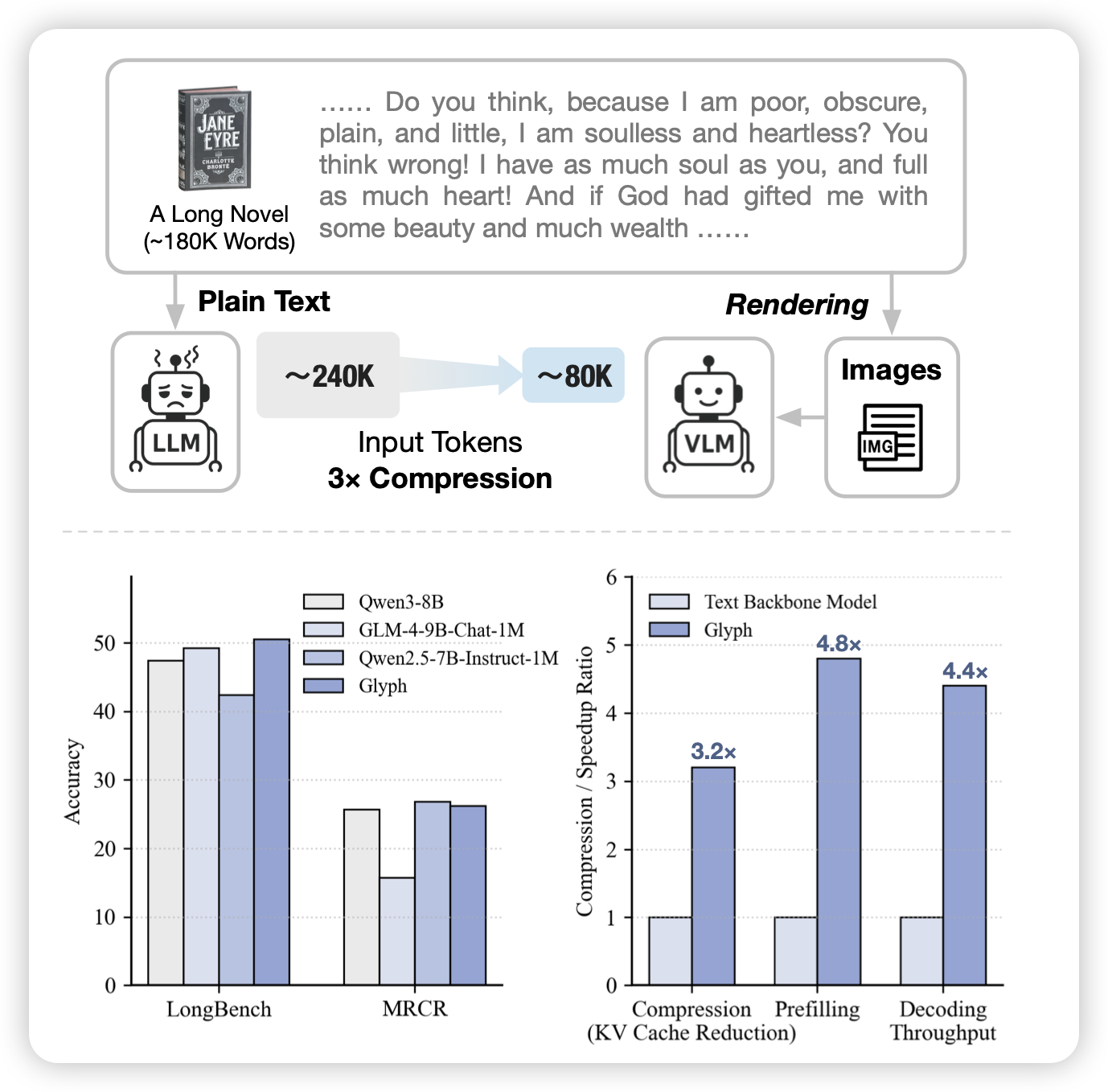
Glyph: Scaling Context Windows via Visual-Text Compression
如果大家不知道这篇工作在研究什么,直接去看deepseek-ocr就行...作者发现可以把长文里面的一堆字直接放在一张图片里,然后用vlm读图的方式来压缩context。这主要是因为,一个1920x1080的图片一般能放下成千上万的字,但是vlm encode完一般也就几千token,这里就直接压缩了好几倍
这么小众的赛道还有抢发的。不过好像ai lab去年就做过一次这个事情了?
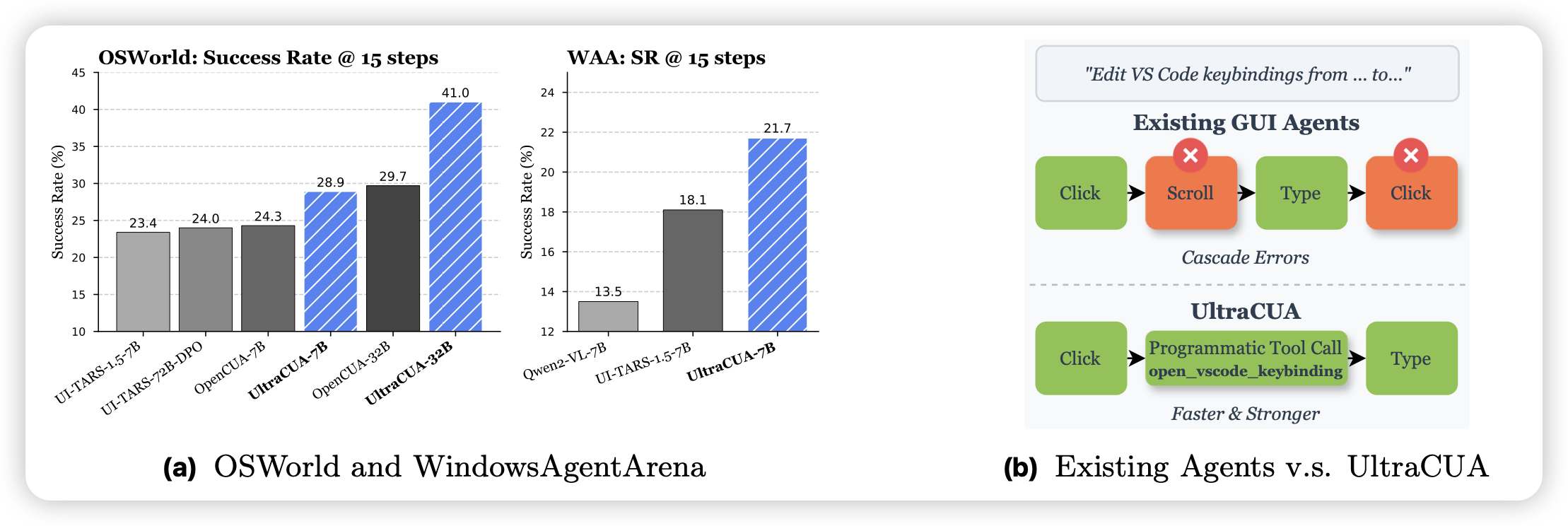
UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action
Apple出的一篇gui agent工作,作者在osworld上接入了一些code接口,让模型同时用gui和api完成任务,用这个方法把osworld/windowsagentarena进一步增强
从glm开始,最近看到挺多篇gui + code的工作...以及Apple为什么不测macosfrena
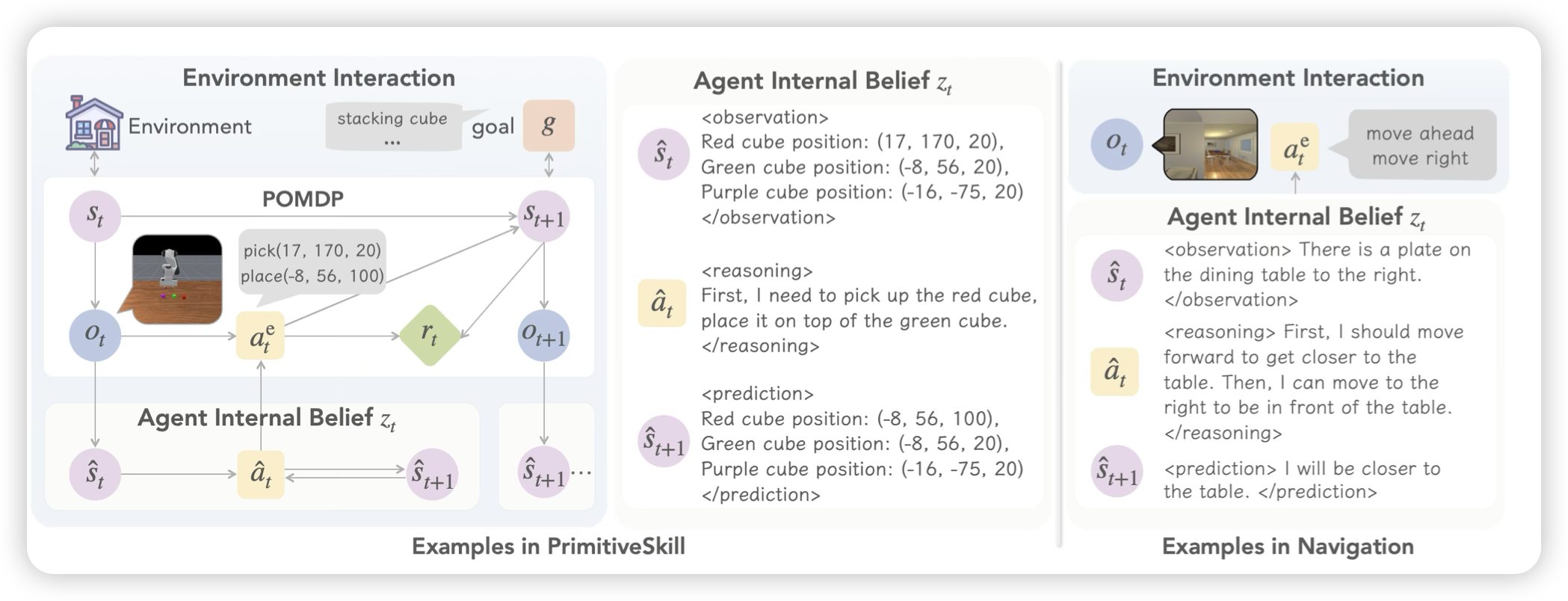
VAGEN: Reinforcing World Model Reasoning for Multi-Turn VLM Agents
这篇工作的作者列表挺重量级的Li Fei-Fei, Yejin Choi, Manling Li,故事讲的挺大的,但是其实做的东西就是把vlm agent做预测拆分。作者认为如果把传统agent的输出改成 obs + think + prediction的模式,其实是学习让模型称为world model。但聪明的小伙伴会说,我直接用一个think字段,也可以说这些,表示能力还更强?所以作者的区别在于,找了几个场景,上面恰好可以给obs和prediction字段单独做reward,发现把world model loss和正常的gae reward放在一起,比直接训rl效果更好。