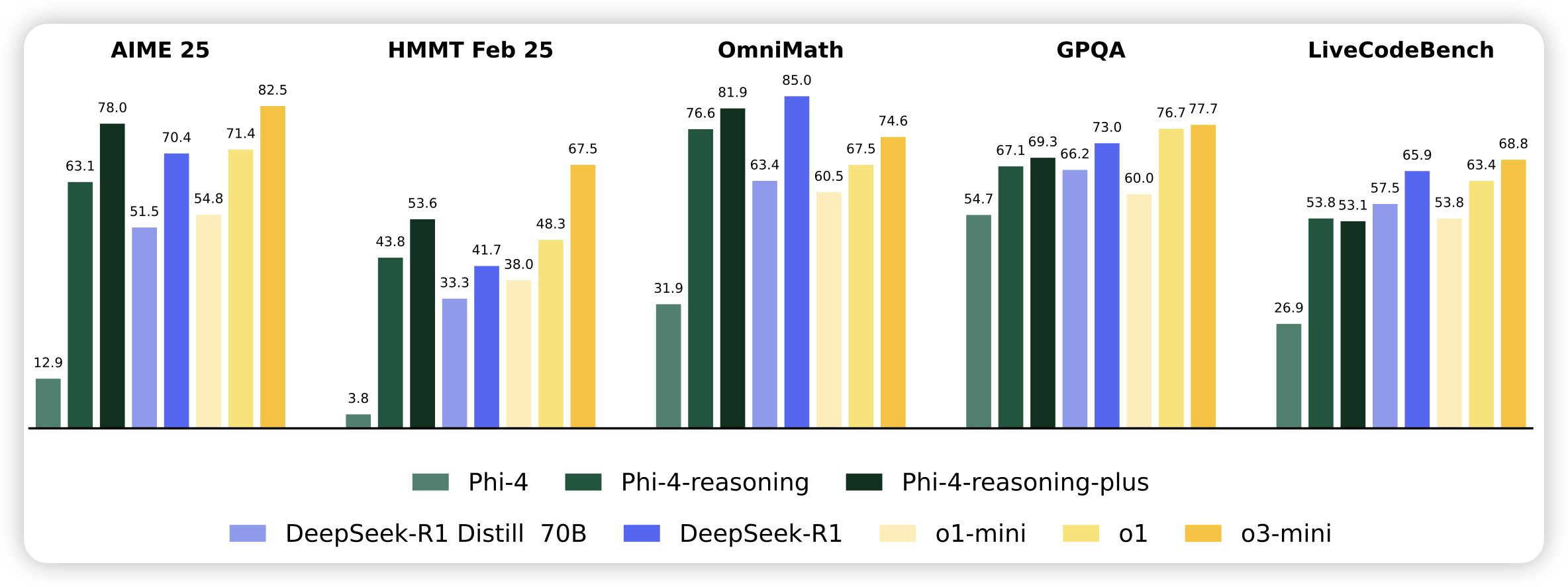
SWE-smith: Scaling Data for Software Engineering Agents
大家都知道swe-bench,是解决真实世界仓库issue的benchmark。但是,有没有对应的训练集/sft数据呢?作者发现,没有。怎么办,作者找了100多个仓库,合成了很多的issue和解决方案。在大规模训练以后,甚至还没有rl,仅仅sft,就刷到了40分。
所以,data is all you need
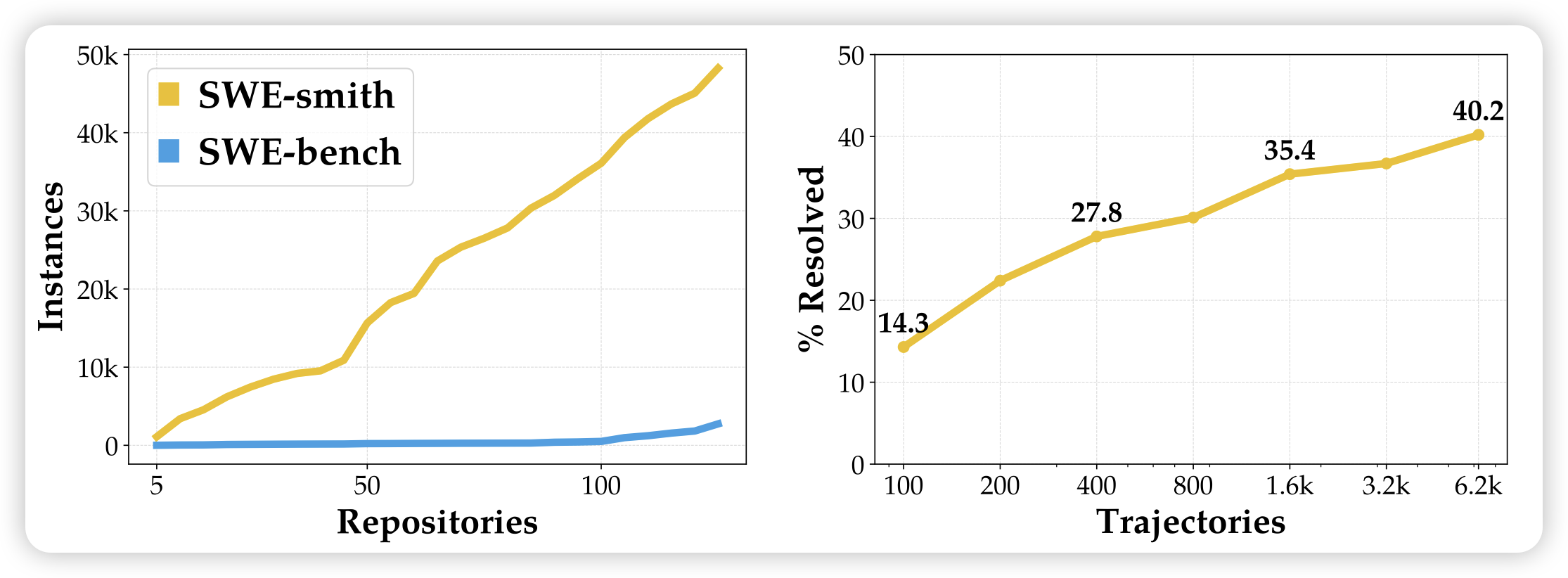
DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
deepseek新出的lean4 证明模型。这里面的优化暂且不提,但主图很有意思:作者发现,v3等强的ai,用word-based的证明方法,实际上已经接近了lean4模型的能力。尤其是reasoning model以后,可能超越了lean语言的证明能力。
如果是这样的话,继续研究lean的意义在哪?是因为更方便去验证证明对不对吗?
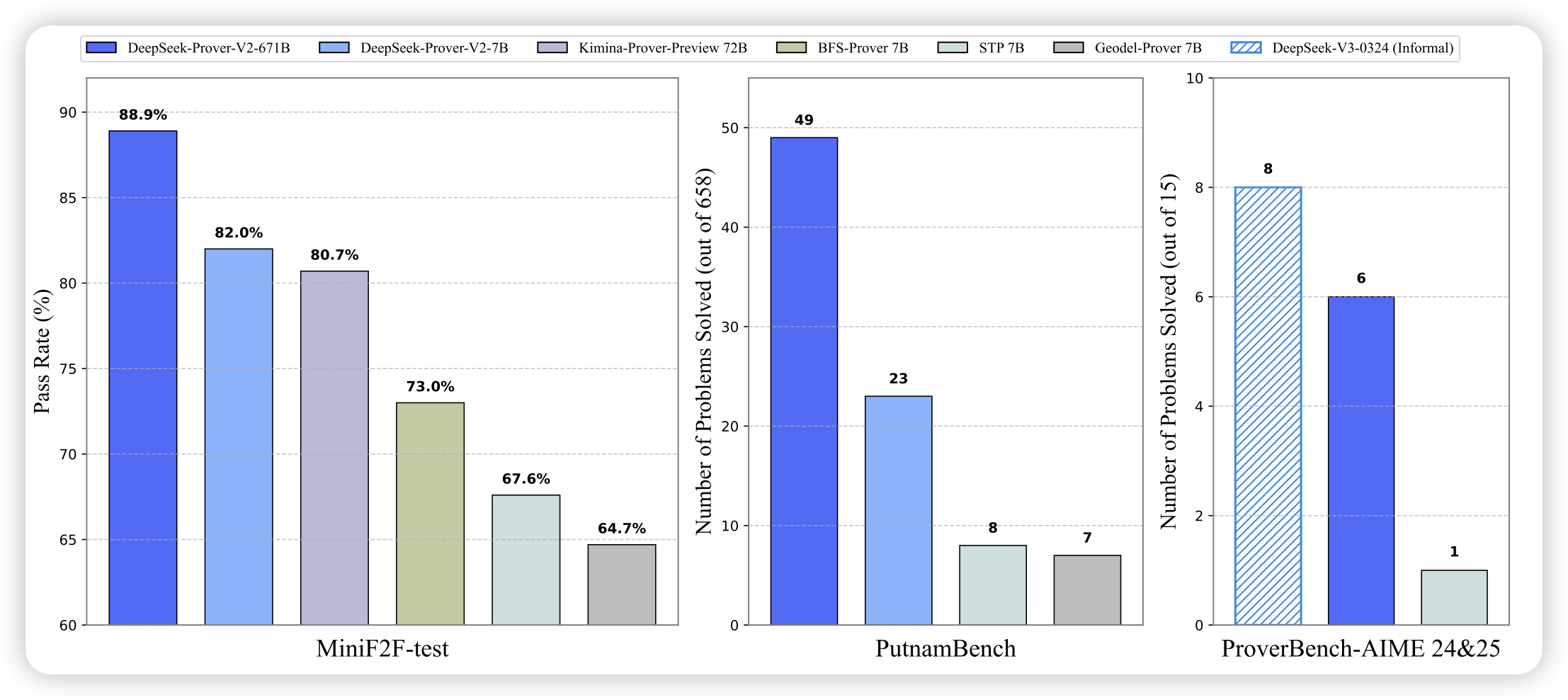
Phi-4-reasoning Technical Report
phi系列的reasoning产品来了。作者发现根据题目的难度选择蒸馏什么数据对o1-sft作用很大,然后通过进一步做一点rl效果会更好
用o3-mini蒸数据的力量