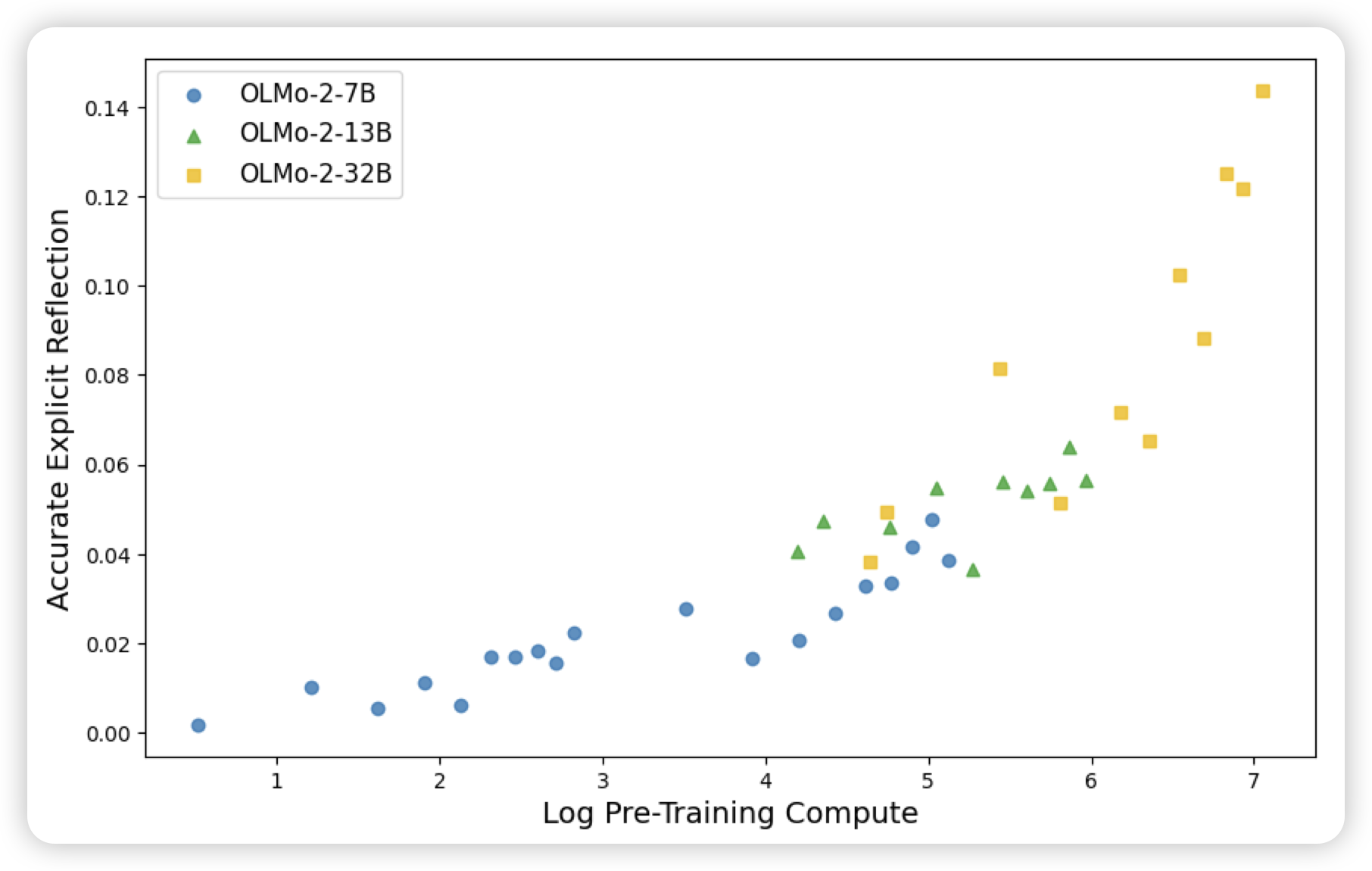
Rethinking Reflection in Pre-Training
之前一直有人说r1里面的aha moment是基模deepseek v3就有的,今天有人真试了一下。作者选择了不同训练周期里面的预训练模型,看看能否在给出错误cot前缀的情况下说出来“I got wrong”等词汇并最终把题目答对。结论是:即使最小的7B模型,都是有这个能力的
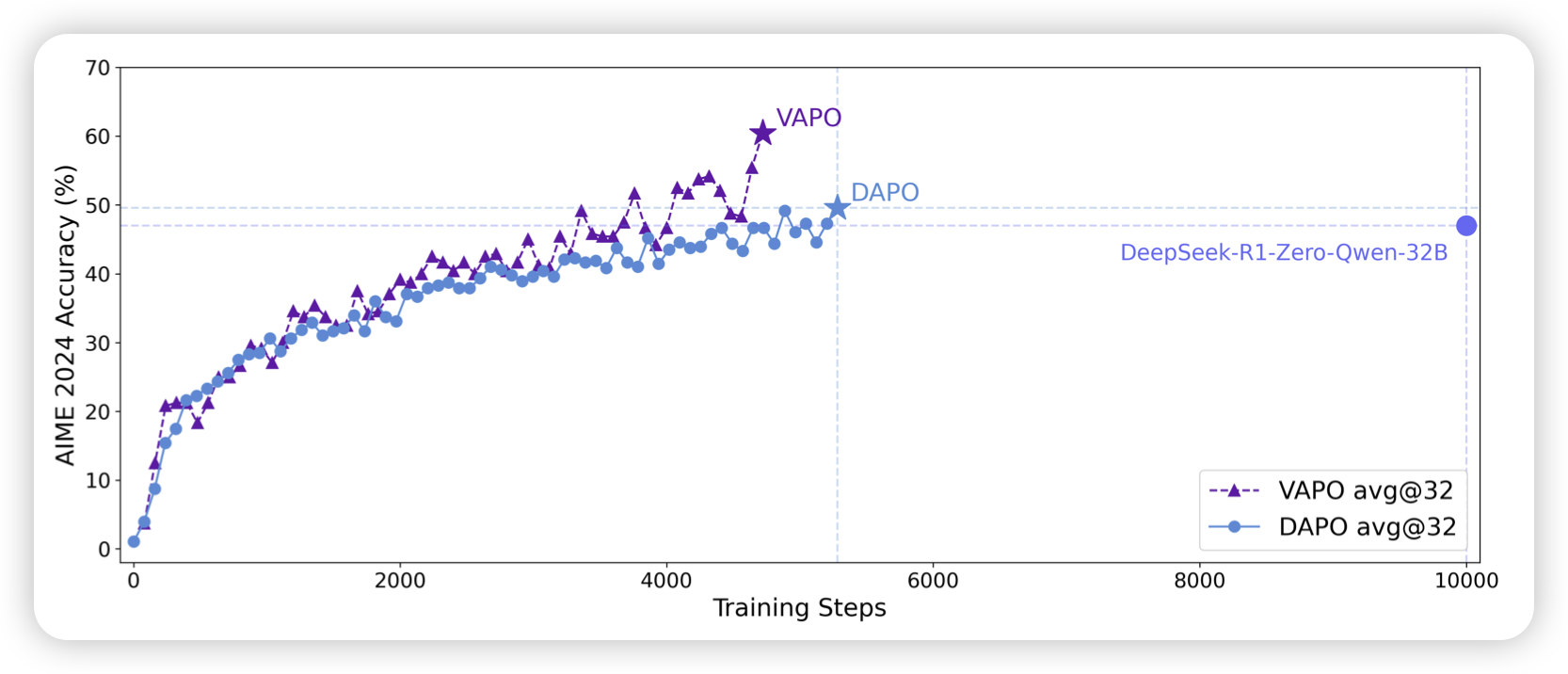
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
前几天字节出了个dapo,今天出了个VAPO,是个value-based rl算法。