这篇工作是Diffusion Model关注度高起来的第二篇重要文献。在此之前,DDPM证明Diffusion model可以生成diversity,但score上,比起“专门造假”的GAN还是略显不足,但OpenAI这片新作,证明了Diffusion model有实力生成比GAN优秀的结果。

作者在Introduction部分先分析了之前GAN比Diffusion Model好的两个原因:
- GAN使用的模型结构被探索的更完善,这点可能会随着Diffusion Model的关注度提升而解决。作者在本篇工作探索了UNet结构的几种改进对DDPM的影响
- GAN更好的满足忠诚度。因此作者想要trade-off dpm的diversity和忠诚度,这也是本文的中心思想。
在Background部分作者描述了一下DDPM的思路,这里就略过了。
Improvements
作者这里的说的是使用iDDPM的方法,学习采样时的方差: \[ \Sigma_\theta(x_t,t) = \exp(v \log \beta_t + (1-v)\log \hat{\beta}_t) \]
\[ \hat{\beta_t} := \frac{1 - \overline{\alpha}_{t-1}}{1 - \overline{\alpha}_{t}} \beta_t \\ \]
v是学习的参数\(M*N*T\)
当然,我们之前讲的论文已经证明这也是负优化了
Analytic-DPM笔记另一方面,DDIM可以加速DDPM采样。(这个也提到可以被Analytic-DPM平替)
同时,作者也讲了一些metric的改进,这些就是纯图像领域FID的内容,我也不太了解,就跳了。
Architecture Improvements
这一部分,作者讲了讨论了几种架构型对DDPM的形象,寻找最适合DDPM的模型。
首先作者提到UNet结构可以在实质上增强Diffusion model的能力,探索了:

Classifier Guidance
这一部分其实就是之前提到的,作者在这里指明了对应的DDPM和DDIM的算法

上面两种算法的进阶形式的推导主要是先用贝叶斯分离(\(x与y\)) \[ p_{\theta,\phi}(x_t | x_{t+1},y) = Z p_\theta(x_t | x_{t+1}) p_\phi(y | x_t) \] 左侧进行泰勒展开,取一阶形式进行化简,剔除,最终得到:
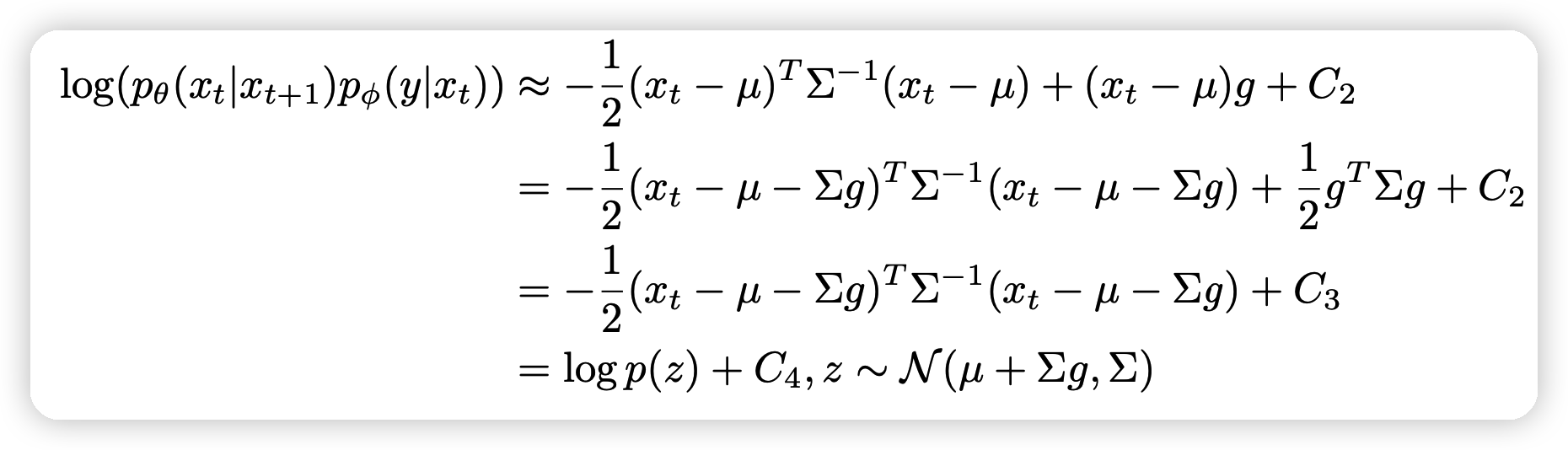
最终,作者探索了这几个改进对DDPM的影响
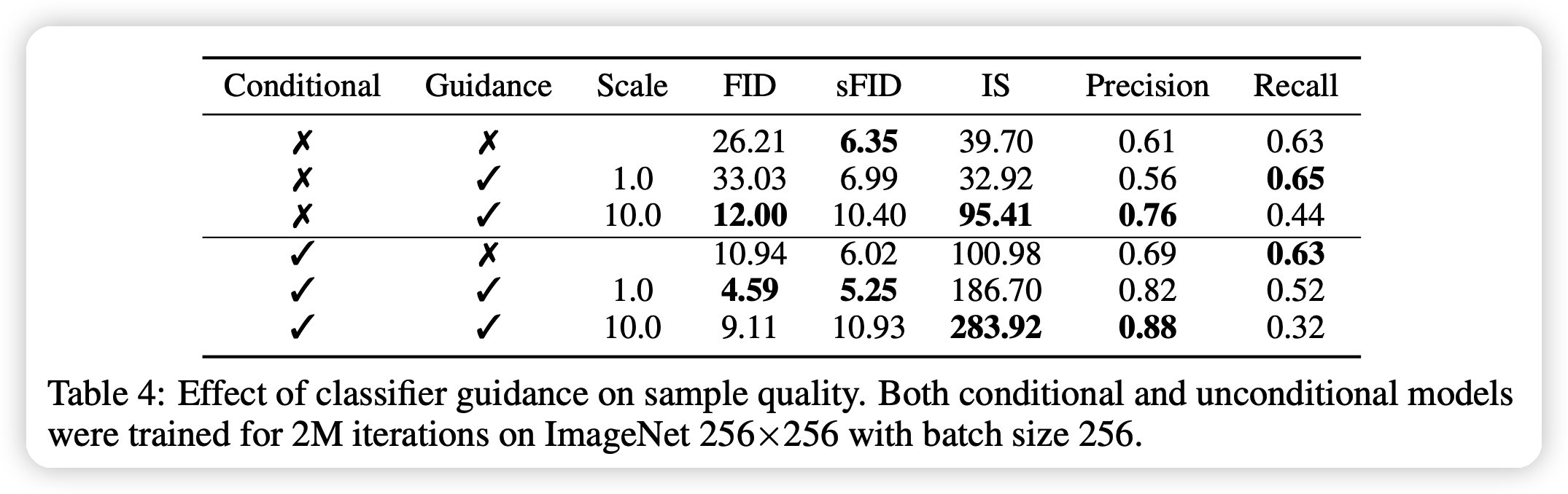
可以看到,合适的scale系数s和guidance可以极大程度提升DDPM的效果。
同时,最佳的ADM模型战胜了之前GAN的SOTA: BIGGAN.
这篇文章最主要的贡献就是提出了所谓classifier guidance的方法,以及证明了DPM是有超过GAN的潜力。