今天更新博客的第一篇论文阅读笔记,是prefix tuning作者
Xiang Lisa Li的新作。尝试在可控文本生成领域中引入在图像领域很火的
diffusion model 的方法。这篇文章不是第一篇文本做 diffusion
model的(大家都从ViT尝到甜头了,领域迁移非常快…),但是第一篇引入连续
diffusion model做文本的。
这篇文章需要比较多的前置知识,我打算分两期介绍。这是第一期,介绍 diffusion model。因此准确来说,这篇博客应该是
Denoising Diffusion Probabilistic Model
的论文阅读笔记
Diffusion model 总体
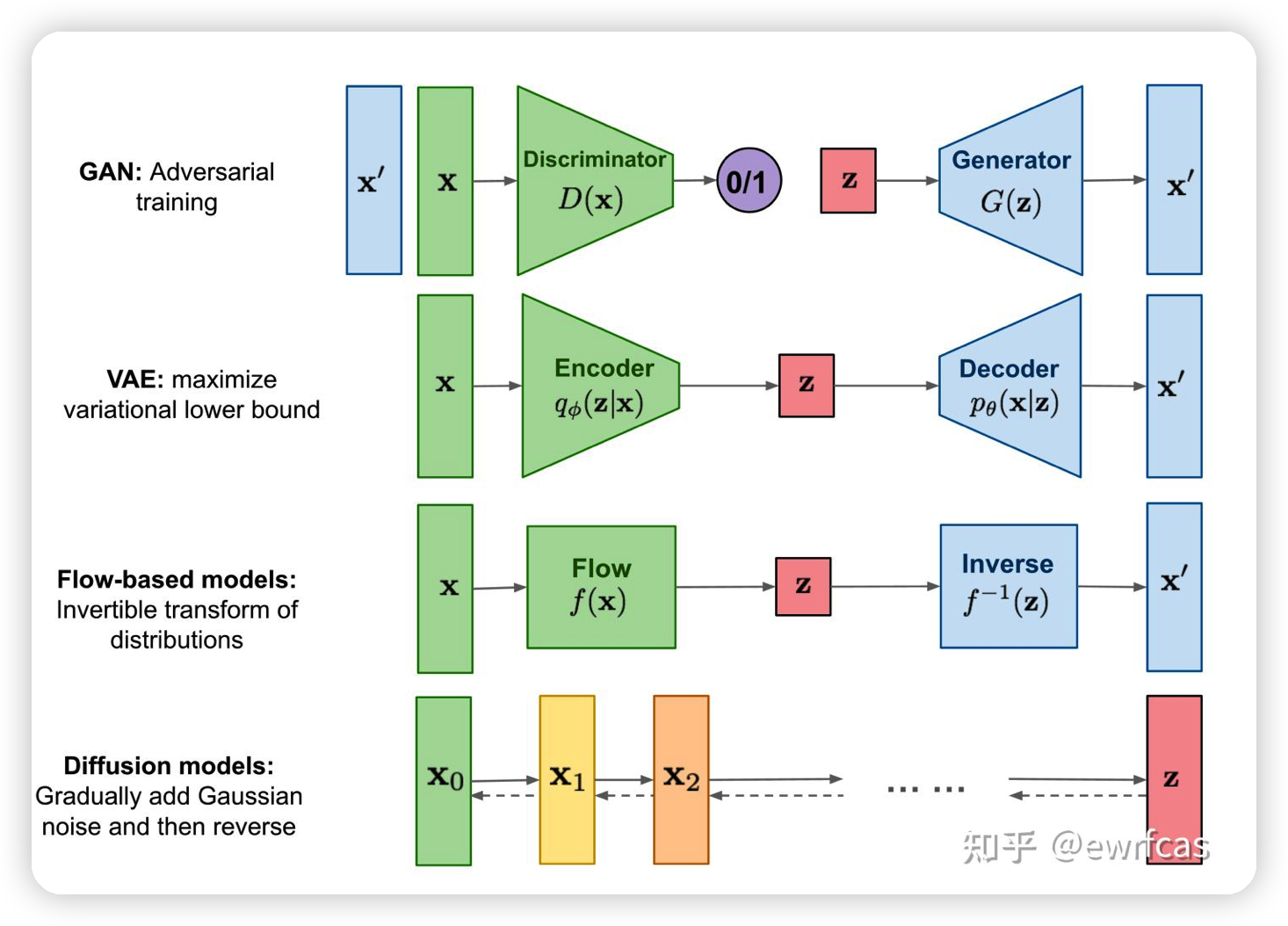
上面图中的几兄弟在paraphrase等可控文本生成任务中用的都挺多,我后面有机会可能都会讲讲,最起码 flow-based models我这几天应该会安排一篇。
扩散模型的思路是有点类似VAE,但又不太一样。效果是不是最好不知道,但它在上面几兄弟中是最新的。它定义了两个过程:扩散过程和去噪过程。前者是把一个对象通过逐步添加高斯噪声,最后变成一个完全随机的分布。后者则是通过一个训练好的去噪模型把一个随机变量逐渐去噪,最后返回到原对象。最近比较火的图像生成模型大体上都是用了 diffusion model的思路。
虽然diffusion model提出的比较早(2020年),但是火起来好像也就是2022年。文本领域的diffusion model更是刚刚起步,还有很多可以提升的空间。
Diffusion model的原理
它的原理很简单,但公式的推导过程却比较复杂。基本用到了以下几方面的知识:
马尔科夫链
贝叶斯公式
参数重整化:把一个\(x \in N(\mu,\sigma)\)的分布变成\(z \in N(0,1), x = \sigma z + \mu\).这么做的原因是我们在采样x的时候往往还会和别的过程同步进行,需要一起算loss,\(\mu,\sigma\)是模型的输出,如果直接采样的话,loss就会被detach。通过重整化,我们把z视为常量,可以让导数图正确传播。
KL散度。经典的分布差异的表示,之前在
Learning Disentangled Textual Representations via Statistical Measures of Similarity
- 分享过MI熵、KL散度、维因斯坦距离、fisher-rao距离、Sinkhorn Divergence、Jeffrey Divergence等方法,这里不再赘述
- 需要注意,这里用到了高斯分布下kl散度的化简方法(显然这个散度不对称):
\[ KL(P_1,P_2) = \log(\frac{\sigma_2}{\sigma_1}) + \frac{\sigma_1^2 + (\mu_1 - \mu_2)^2}{2\sigma_2^2} - 0.5 \]
中间推导全部略过,从结果来看:
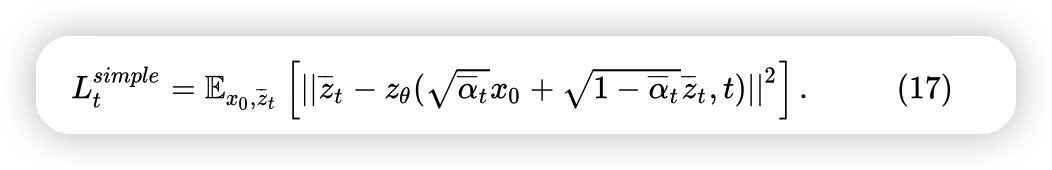
这个告诉我们,只要随机选取一个时间t,选取一个随机数,我们就能对参数模型 \[ z_\theta(\text{某一个输入}x_t,\text{时间t}) = \text{x对应的输出}x_{t-1} \] 进行优化。最终训练过程如图:

这里有几个细节,需要注意一下:
- 对于每次采样,它不是把\(t=0,1,...\)全部采样一遍算loss,而是取一个随机的t。原因是这样可以”稳定训练过程“
- 在infer过程中,最后一次的随机变量z=0,也就是说去噪的最后一步不能添加噪声。
- 公式里面的 \(\alpha_t = 1 - \beta_t, \overline{\alpha_t} = \prod_{i \leq t}\alpha_i\).其中\(\beta_t\)要递增的选取,并且趋近于1,这样才能保证多次加噪完的\(x_T\)会变成一个随机分布 \(X_T \in N(0,1)\)
Diffusion model 的分析
我们来对比一下 diffusion model 和VAE。可以看出:
- VAE需要一个专门的先验网络来对x生成随机变量z,在infer时扔掉这个网络;而扩散模型的加噪过程是确定的、无参的,不需要一个专门的加噪网络。
- diffusion model 每一步的隐变量都和原来的\(X_0\)是同一维度的,同时需要多步采样(可能多达1000步)才能把完全随机变量恢复到原来的 \(X_0\)
个人总结了一下,diffusion model 有以下的优点:
- 由于去噪的过程是多步的,我们可以在这个多步的过程中实现更好的、更粒度的控制
- 效果会比传统VAE更好。
- 它可以更好的handle从类似于”半抽象“的过程恢复,不需要要求去噪的起点一定是随机噪声
但是,他也有以下的缺点:
- 太慢了,1000步?而且作者说步数少了训练会出问题?今年好多论文都是
- 怎么提升采样效率
- 通过降低图像尺寸改善速度
- 训练过程不稳定,估计不好训。这个对于实际开题的问题很大,毕竟不是每个人都是deep mind调参神(
- 噪声的隐空间不编码任何有效信息,只是单纯的噪声。
个人点评
从NLP的角度出发,diffusion model首先需要handle 词语 -> word embedding 的问题。
- 一个显然的方法是借鉴VQVAE的思路,把中间变量clap成最接近的word embedding。可能带来的新问题是:直接转变噪声过程,会导致扩散模型那个不等式不再成立??这个可能得实际训训看结果怎么样
这个扩散模型有点问题:只能从随机噪声变成一个”有某种控制信息下的一段文本“。但我们很多需求是平行预料的,比如 style transfer,这就回到了刚才说的缺点,我们得想办法在隐空间中编码信息:比如语义信息等。
- 我似乎看到今年CVPR有类似的工作?
https://arxiv.org/pdf/2111.15640.pdf
- DALLE-2 里面有个 CLIP-Image encoder也是在干这件事?我应该会在近期读一下dalle-2的论文,写一个阅读笔记,那篇里面再聊吧
慢的问题,可能在NLP更严重。大概率,diffusion model里面的原子模块得用 transformer,两两叠加是不是直接凉凉……
我在思考能不能在长文本中引入 diffusion model,这个好像会对每一句都搞得不错,和 plan 生成、文本检索一起叠buff,可能能整个大的……这个可能也得后面再试。