今天来读一篇MLSys的文章,作者提出了JIT的APOLLO框架,可以同时考虑 memory- /compute-bound 的算子优化,比XLA,TensorFlow原生要快不少。
JIT(just-in-time):和AOT相对,是指边运行边编译,不能支持某些编译优化方法。

作者来自郑州大学、华为、香港大学
Introduction
这部分说了目前fusion技术面临了三个问题:
- 现有的图编译器只考虑了memory-bound op的优化,对于compute-bound op,只是分发到不同的kernel,不做fusion。因此fusion的搜索空间是不完全的
- 对于循环loop fusion来说:不同层次的编译器之间存才
- stitching融合技术,把没有依赖的不同算子放到同一个kernel来同时计算,提高硬件的并行性。这种技术对于自定义算子的支持非常差
本文提出APOLLO框架,把sub-graph进一步看成很多micro-graph,在这个过程中同时考虑memory- /compute-bound 的算子fusion。划分的规则取消了上游图编译器的依赖,规则符合下游编译器的需要。可以符合一个多面体模型,同时也可以扩大规模。
APOLLO := Automatic Partition-based Operator fusion framework through Layer by Layer Optimization
- 首先,用一个polyhedral loop fusion算法让micro-graph内部的算子fusion,并且让有依赖管的数据在更快的local memory里
- 接下里用一个memory stitching算法让micro-graph之间的算子fusion,弥补前面polyhedral算法的劣势
- 最后,由一个top layer把前两步的结果组合在一起,更好的利用硬件的并行性。
APOLLO可以把每一步中间生成的IR传给下一步。本文的贡献总结为:
- 扩大了fusion 的搜索空间,考虑更多种op
- 通过operator-level优化器反向反馈结果,可以进行更大规模的fusion
- 同时考虑数据的局部性、并行性,效果更好
- 展现了JIT compilation的水平
ARCHITECTURE OF APOLLO
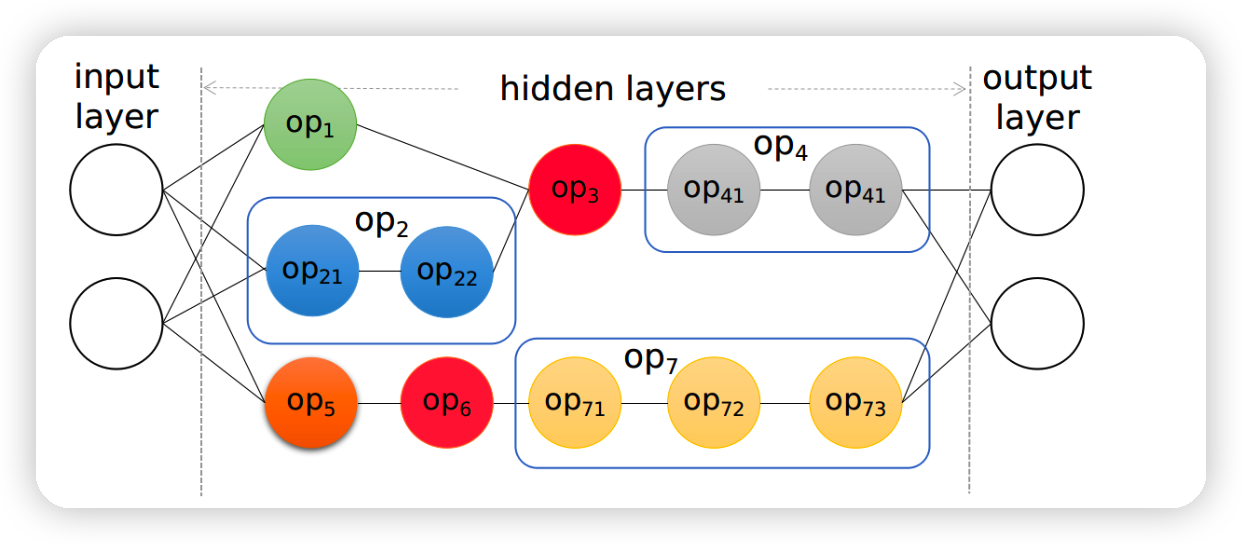
用一个例子来说明apollo结构,上图是一个计算图:
计算图可被分成上下两个子图(相互是可以并行执行的)
Op5,op3是计算瓶颈的节点
Op1,op6是原子的节点
Op2,op4,op7是可再分的节点
对于计算瓶颈节点op5,op3,已有编译器尝尝直接丢给vendor library,并且把,每个子图sub-graph看成孤立的不同部分
Tensor compilers面临上下游需求不同的问题,比如上游编译器希望op7编译成一个kernel,但如果op71是reduce op,下游编译器很难满足这个需求
另一个问题是当batchsize小的时候不能利用好硬件的并行性,现有方法经常把同一个子图中的比如op1,op2放到同一个kernel,这和实际的training scenarios不符合。
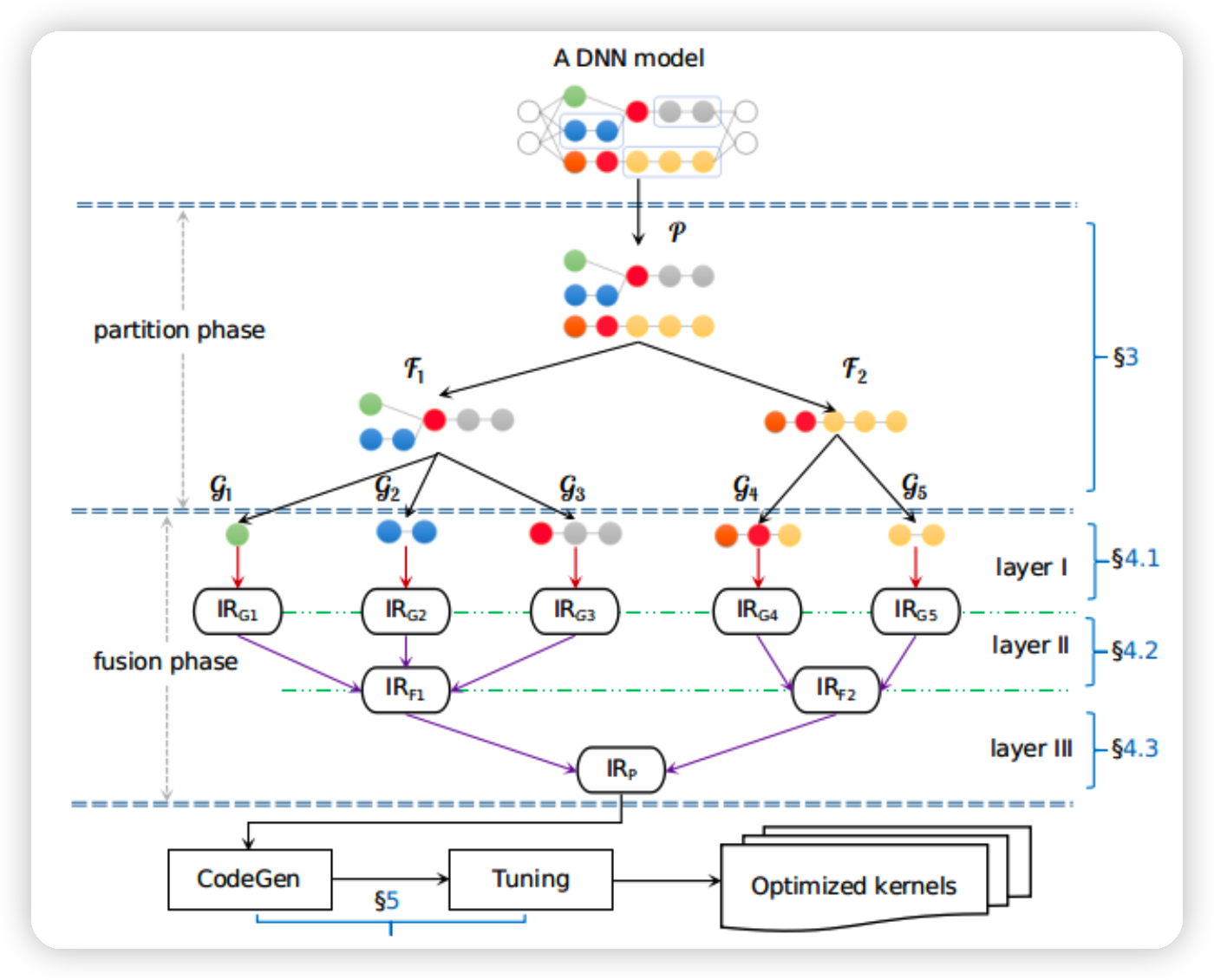
本文提出的APOLLO框架如下:
首先把图分成不同子图sub-graph,子图之间没有数据依赖(\(\mathcal{F}_1,\mathcal{F}_2\))
接下来,用一系列基于规则的方法把每个子图分出不同micro-graph(\(\mathcal{G}_1,\mathcal{G}_2...\))
对于每个micro-graph,进行fusion生成IR,用的方法是polyhedral loop fusion heuristic
把上一层的结果传给下一层,layer 2 对结果进行grouping,同时根据reducing op进行fusion
最终layer 3接受上一层输入,进行子图之间的并行性的优化
polyhedral model
好多篇里都说了这个polyhedral,到底是咋回事呢?这里拓展一下。
大概就是一个多重循环,里面的所有可能的取值(i,j,k)可以用一个矩阵来表示: \[ A_{3,3} \left( \begin{array}{} i \\ j \\ k \end{array} \right) \geq \left( \begin{array}{} a \\ b \\ c \end{array} \right) \] 之类的,总之这种方程在高位空间就是一个多面体,可以认为循环都是在多面体内执行。有什么作用呢?
- 循环间的数据依赖大概看成是多面体内内部有一些”线“,如果是水平的、垂直的,那么就不会有冲突,只有“斜线“会带来冲突,但如果我们对这个多面体进行仿射变换,就可以把斜线都变成直线了。
- 我们希望循环内可以更多利用cache,同样利用仿射,可以把空间距离近的取值让时间距离也拉进。
大概就是这个原理,因为有了数学的表示,所有优化也就比较简单。
PARTITION PHASE
这一部分谈怎么变成micro-graph
作者首先使用几条规则把图优化成符合多面体模型的图

接下来,要找出计算图中除了用户定义的op和control flow ops以外的op,变成一些子图。
Opening Compound Operators
再接下来,作者把compound op拆解,比如说logsoftmax: \[
S(t_i) = t_i -\ln \sum_{j=1}^N e^{t_j}
\] 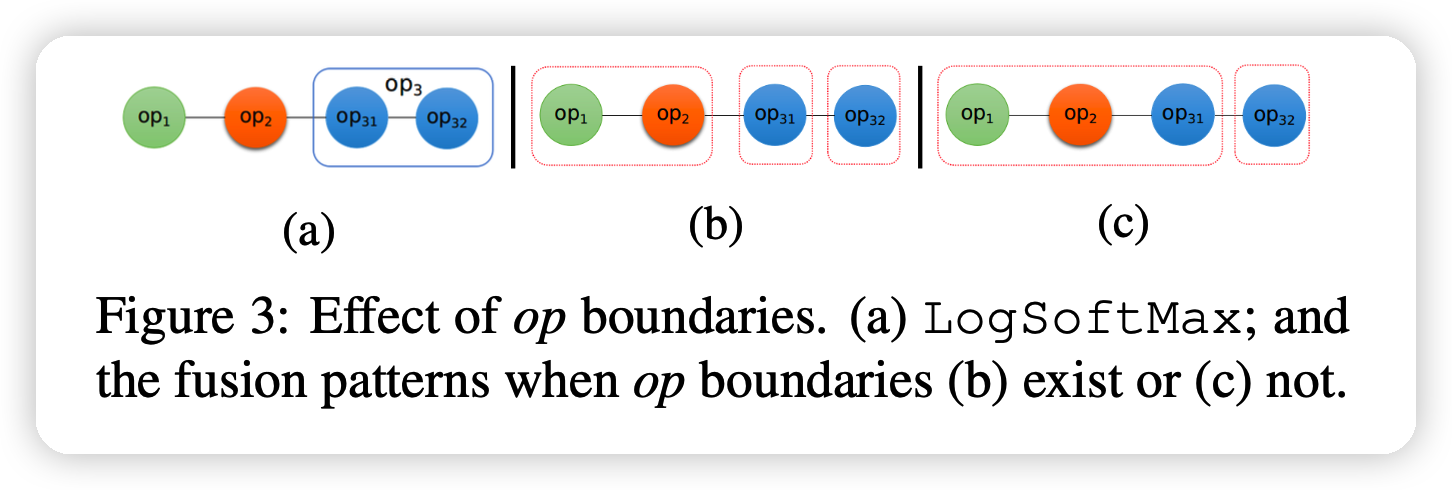
其对应蓝色的两个op:减法,和一个循环计算的op,这两个op有数据依赖。
如果把op3拆开分析,就能把op31和前面的op1,op2融合到一起,,增大fusion的搜索空间,这就是拆解compound op的好处。
Aggregating Primitive Operators
这一部分要分解出很多micro-graph
首先把primitive op看做micro-graph,然后用aggregation rules去逐步扩大micro-graph。规则大概是下面这样定义的几条:
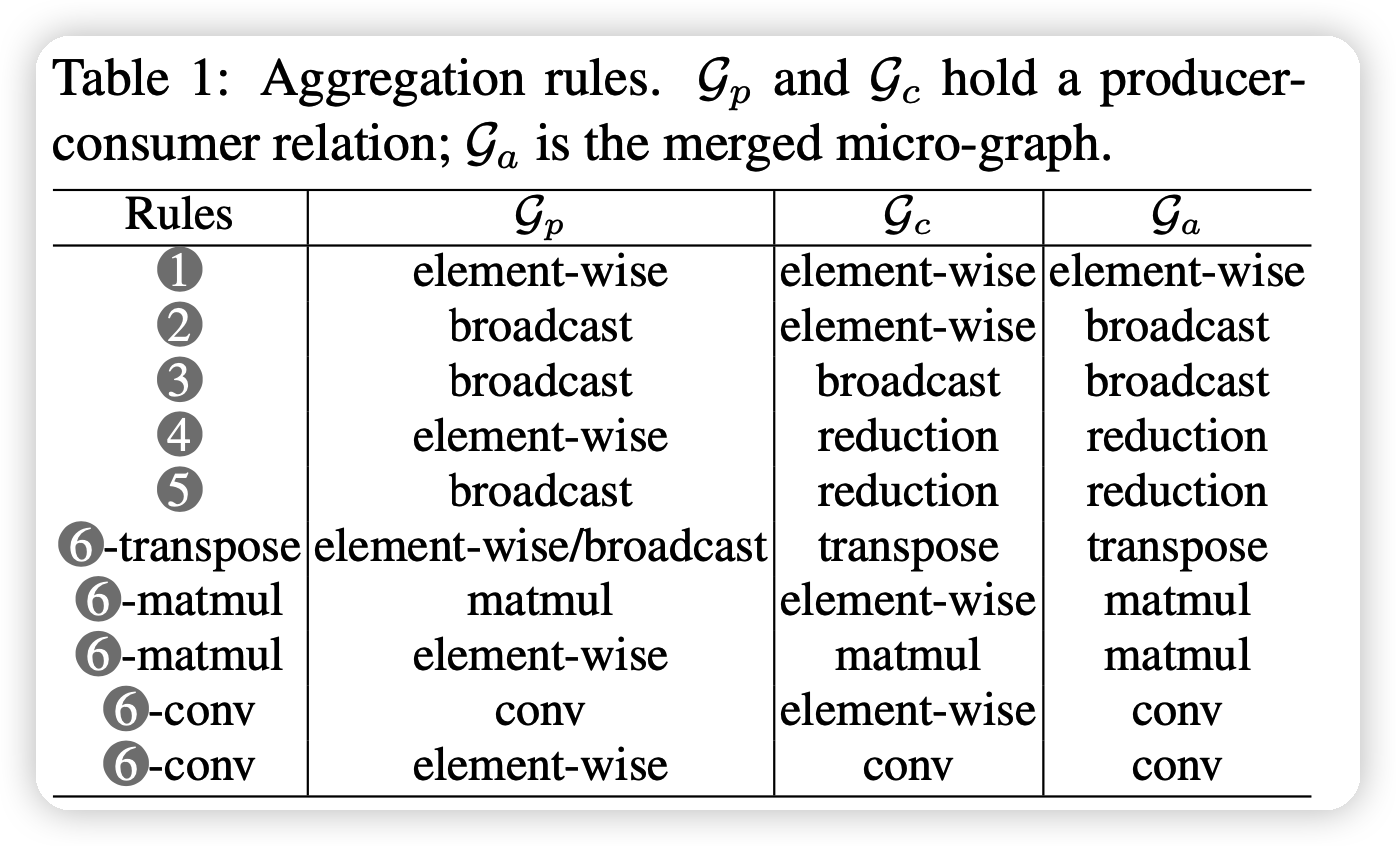
规则不用覆盖所有op,因为有些op本身就不需要fuse。
FUSION PHASE
fusion的阶段符合自底向上的顺序
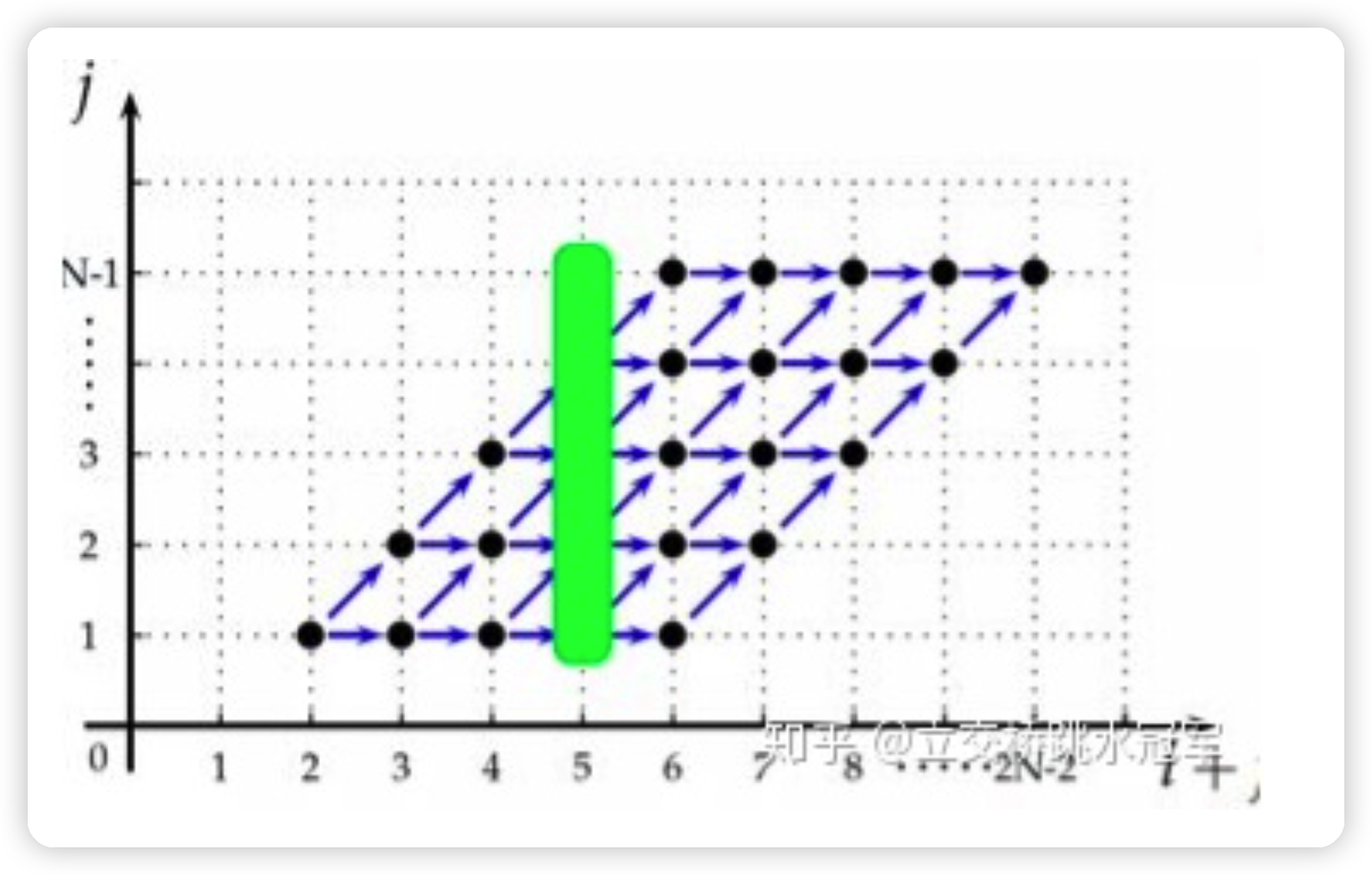
Layer I: Polyhedral Loop Fusion
这一部分讲了micro-graph内部是如何做fusion的。方法很多,很复杂,这里就不细讲了,感觉只有看代码才能深入了解,大概逻辑就是像下图这样:

Layer II: Memory Stitching
这一部分是说如何把fusion后的micro-graph再fusion,再组装回sub-graph
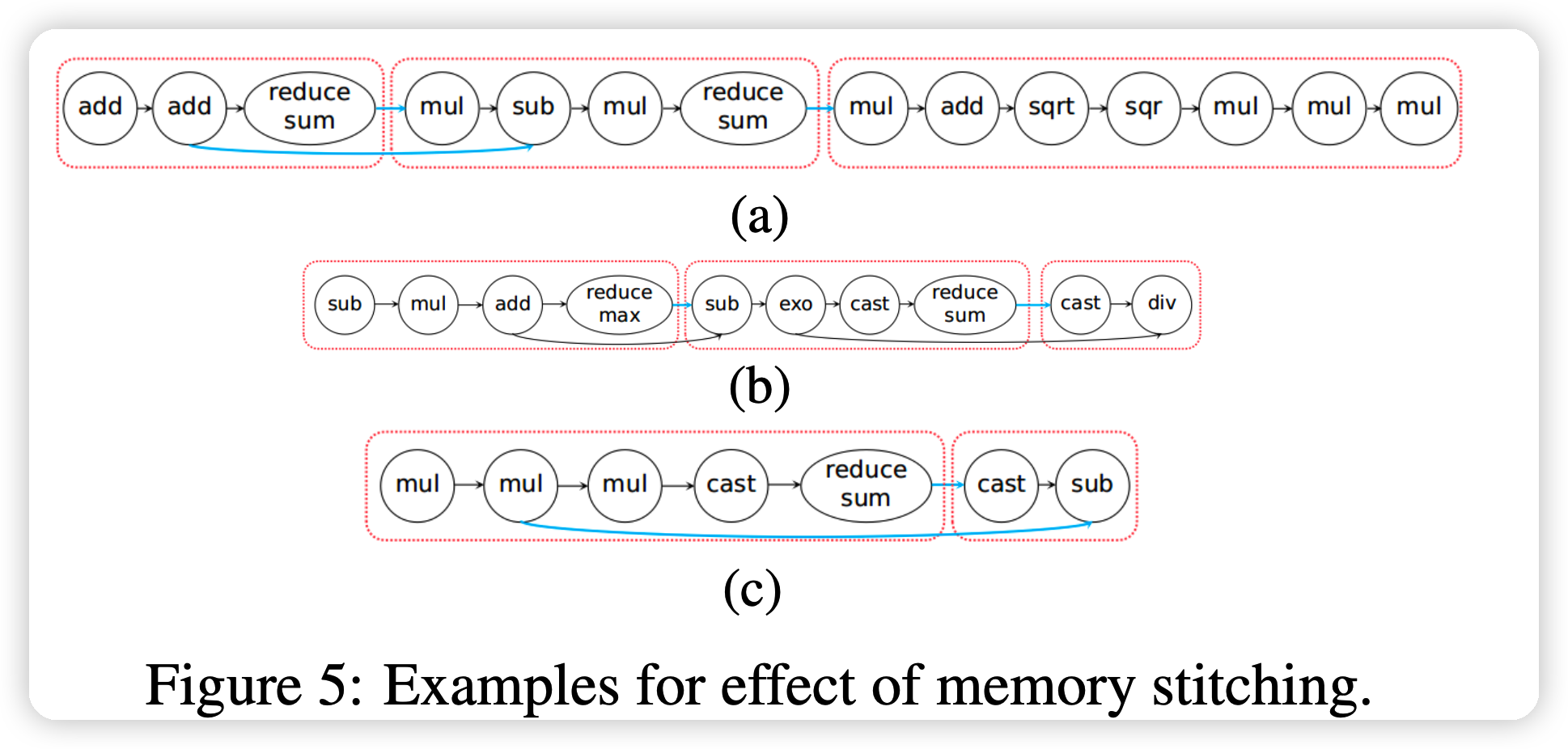
大概思路就是如果一个micro-graph是一个reduce型的micro-graph,那么它也许可以和后面你的micro-graph的中间变量排布在一起,用到更快的local memory。
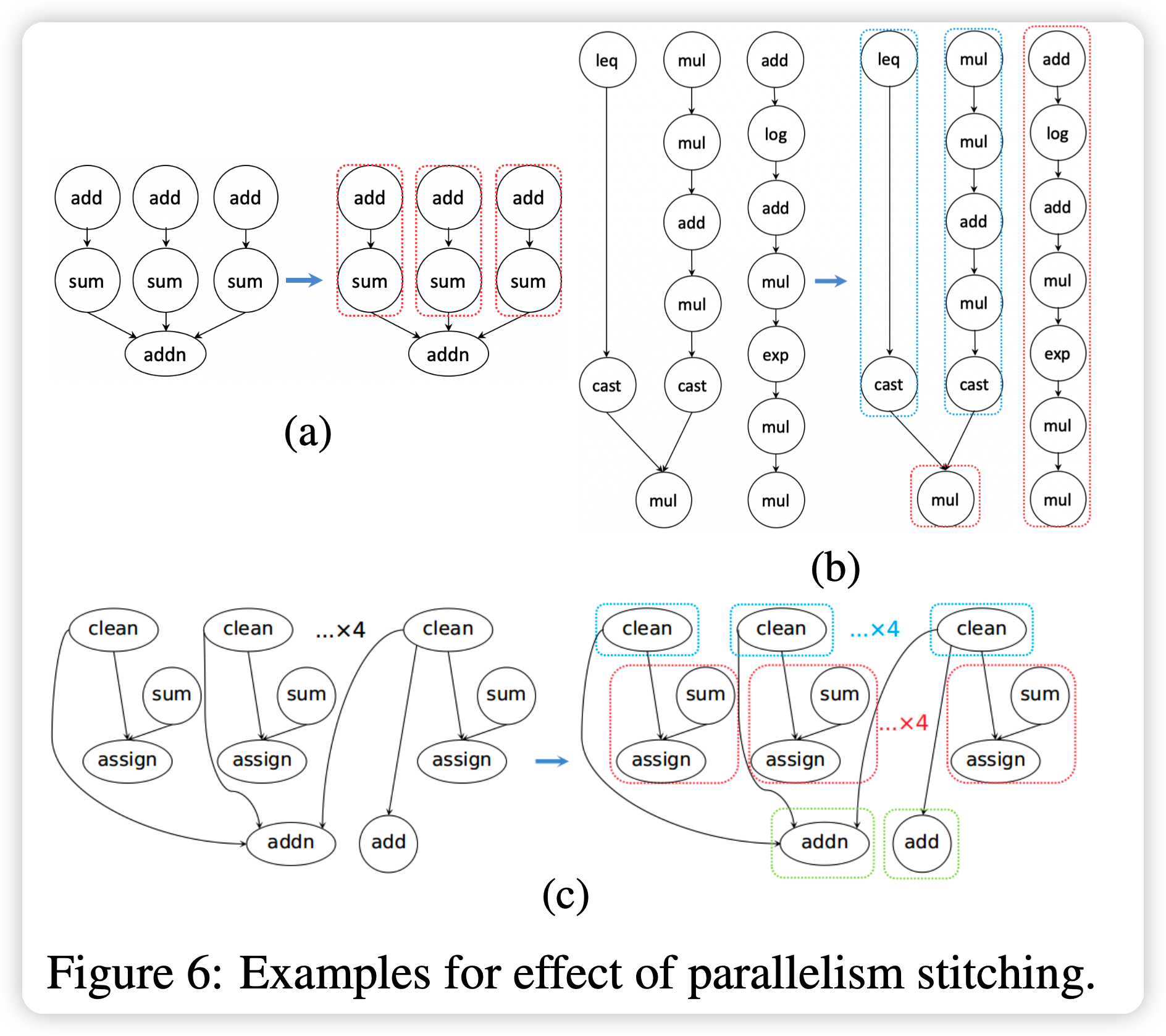
Layer III: Parallelism Stitching
这一部分考虑子图之间的并行性,作者观察到并行性大多存在于:
- branches of a multi-head/-tail op
- 两个子图没有数据的依赖关系。这种可以合并成上面那种
作者大概考虑了怎么优化 multi-head/-tail op,作者用一个cost模型逐步的选取并行效果最好的节点加入。
PUTTING IT ALL TOGETHER
- Auto-Tuning: APOLLO解决了scalability的问题,并且由于peicewise编译速度不慢,因此支持auto-tuning
- Piecewise Compilation:每一层的各个节点之间的编译是并行的,只需要在层交换的时候做一次不同
- Code Generation:生成A100 cuda代码。
Result
大概就是说APOLLO处的代码效果更好
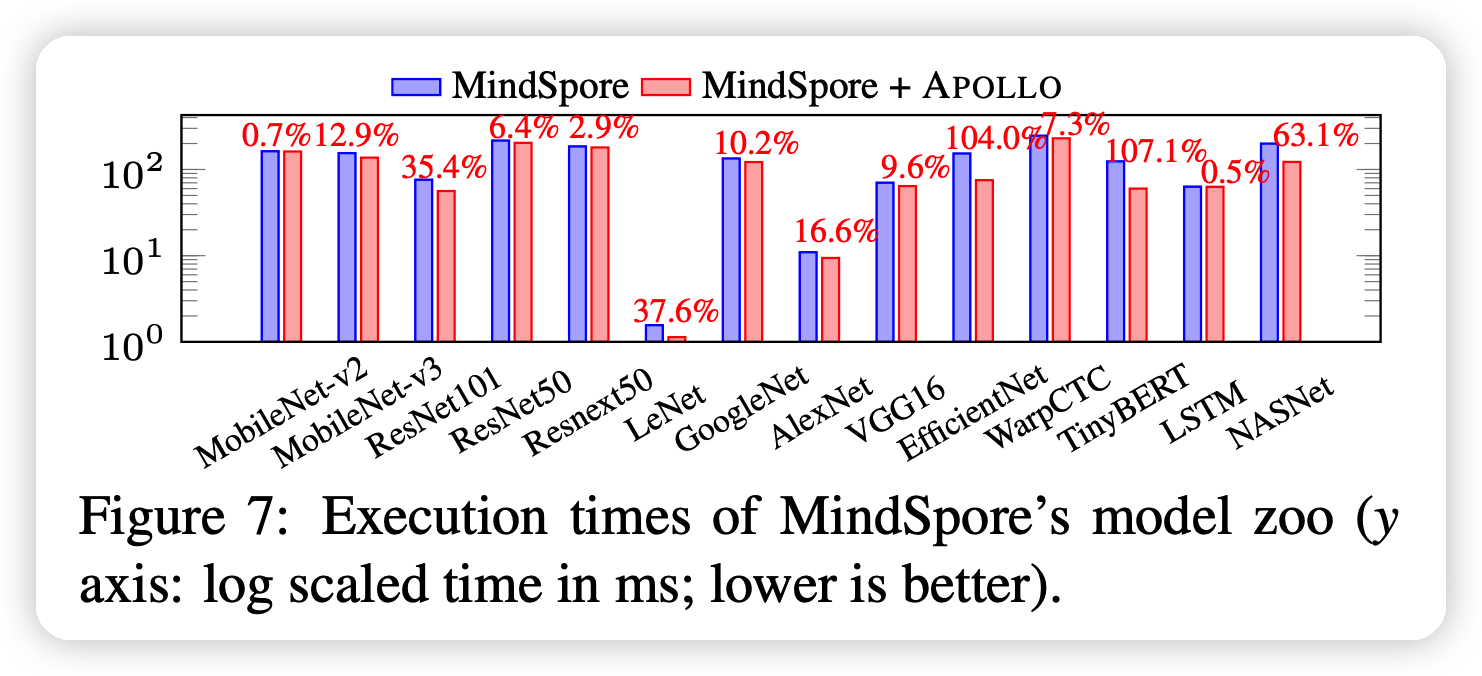
mindspore:是华为的开源AI框架,APOLLO可以试做是在优化mindspore的编译
结论
- polyhedral优化的扩展性是一个NP问题,因此很难大范围的应用。本文通过把图拆解成子图,每一部分分别做,一定程度上解决了这个问题。
- 目前的规则很简单,不一定适合其他的、未来的算子
- 本文使用的costmodel很简单,只是单纯的在并行和同步之间做权衡