语言模型的RLHF(PPO)的基本流程的算法我们在 强化学习和RLHF中的PPO算法 中介绍过了,主要分为三个阶段,下面我们来讲讲Llama 2分别做了哪些创新吧
SFT
data and train
首先,作者和之前的论文保持一致,认为SFT的训练数据数量不是问题,关键是质量。然而,作者还是收集了27650条instruction tuning的数据,emmm,这好像是我见过的最多的。
作者在180条数据上做了仔细检查,比对了human的结果和SFT model生成的结果,发现大致在一个水平。
训练方式就是传统的crossentropy,然后作者只在assistant message上计算梯度
reward model training
首先作者需要human paired data。标注了大概100万条数据
标注过程和后面的过程是绑定的,就是先标注一波,然后做RLHF。下一波标注的时候pair data来自新模型。主要是因为human标注需要时间,以及更高效地利用数据
另外,作者为了让human永远有选项选,提供了四种偏序关系可以选择。

margin
接下来,在训练RewardModel时,作者利用起了之前human标注的多种偏序关系,具体是这样 \[ \mathcal{L} = - \log(\frac{1}{1 + e^{-(r_\text{good} - r_\text{bad})}}) \] 这个loss是一个Bradley-Terry模型crossentropy loss的导出形式,希望好的数据的reward更高
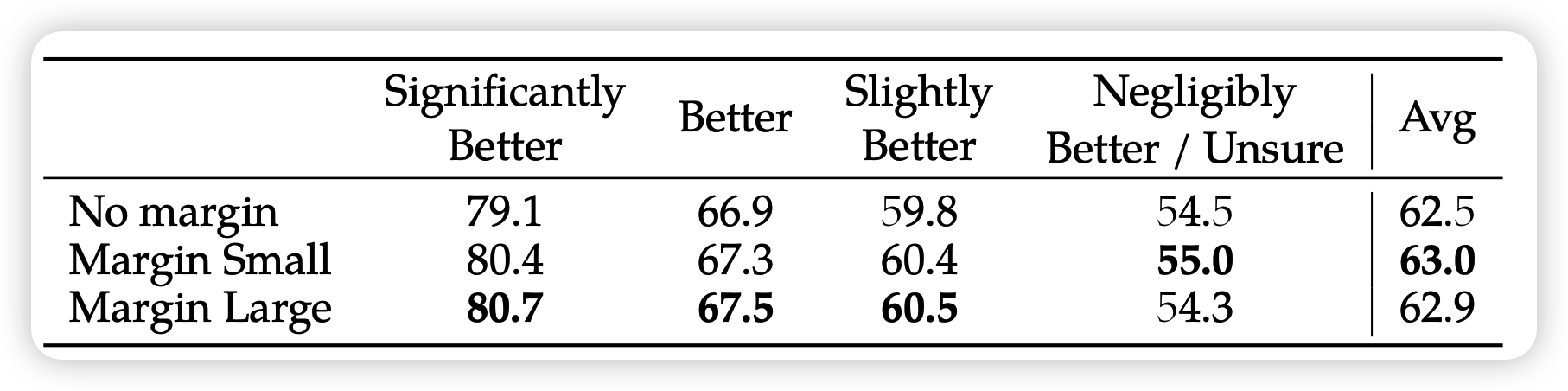
如果已知human的偏序不止一种的话,就可以额外加一点偏差值 \[ \mathcal{L} = - \log(\frac{1}{1 + e^{-(r_\text{good} - r_\text{bad} - \text{margin})}}) \] 就是说,比如significant better,就希望差得更远,通过更大的gradient来保证。作者做了消融实验,看在测试集上reward model的分类acc,发现效果确实更好
performance
衡量reward model好坏的指标就是测试集分类acc,
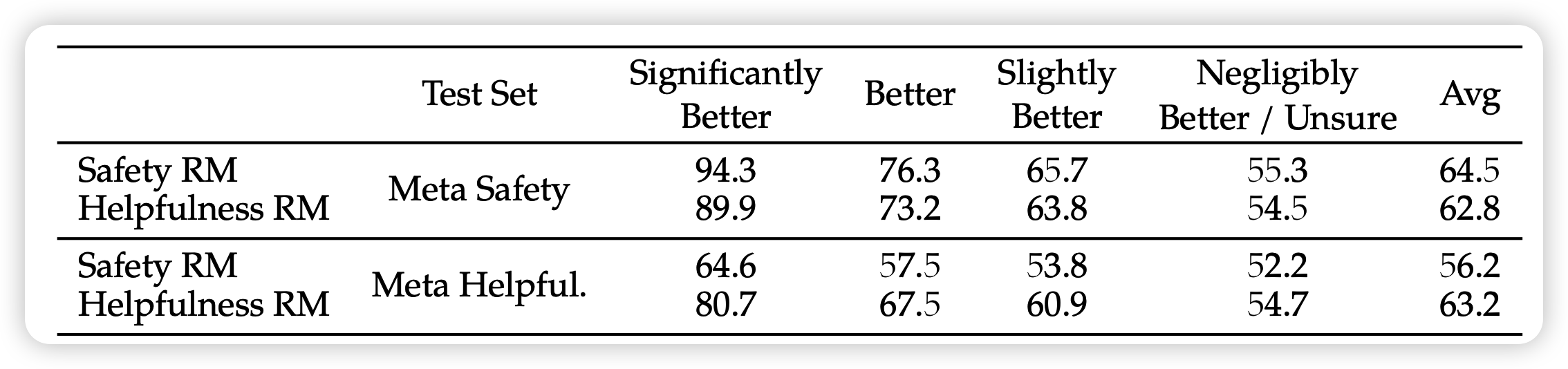
首先报告了在各种偏序关系下测试集上的reward model分类结果,发现区分还是挺明显的。基本上human认为显著区别的,模型都能区分。
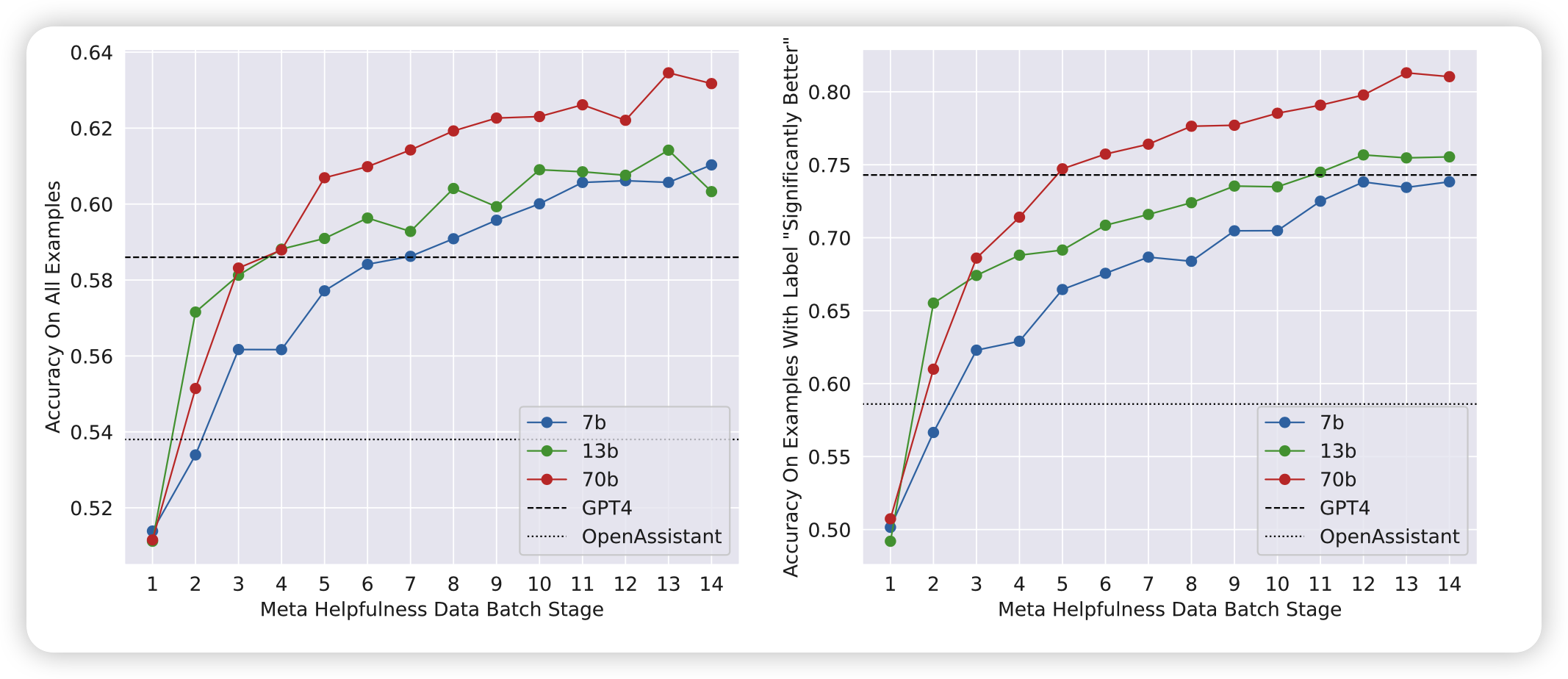
接下来作者做了一个scale实验,发现用更大的模型、更多的训练数据可以训练出更准确reward模型。最重要的是:
仍未观察到收敛现象。也就是说,还能接着提规模涨指标
RL
最后的RL阶段。和前面提到的,由于human标注是一波一波来的,作者也就是一波波训的reward model和RL模型。称之为RLHF-v1到RLHF-v5
主体方法上,作者尝试两种方法
rejection sampling
这是一个看起来很稳定的算法,和之前讲到的 RRHF阅读笔记 非常像
每个iter中,先对每一个prompt采样K个样本,然后用打分模型打一波分,找到最好的样本,然后按照SFT的方式计算crossentropy loss。
为了训练的稳定,选取最好样本时是从前面的所有iter里,而不是当前iter里选最好样本(所以其实是K*iter选1)。其实就是退化版的RRHF,不过省下了非常多的训练资源
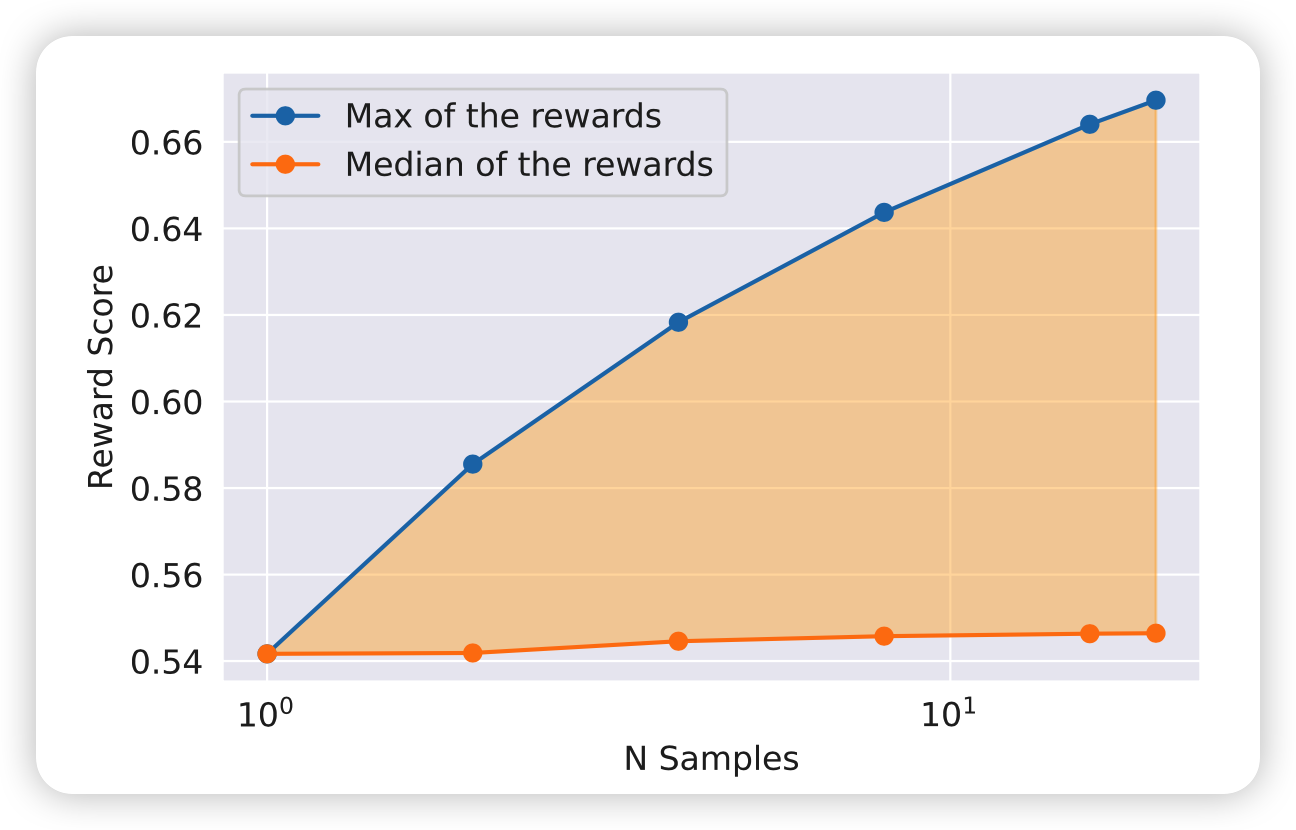
作者实验了一下,用最开始的SFT对应prompt多次sample样本,对应的最高score持续提升,这就是这个算法的优化空间。
同时,这个算法的效果和sample样本时选取的算法也是高度相关的,更高的diversity更可能找到更好的样本,但是数据少时表现更不稳定。
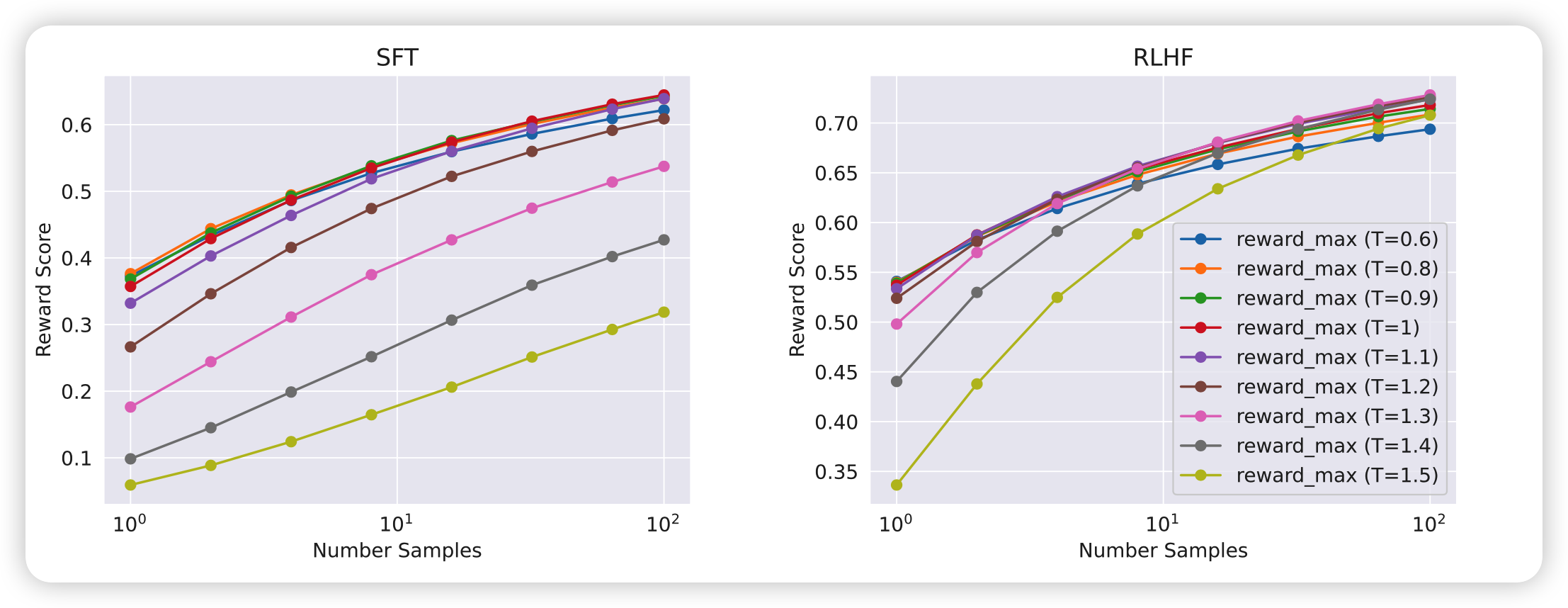
作者做了实验(注意左右两图的纵坐标不一样),和上面一样看多次采样的最高reward。发现这个最佳温度是在变化的,因此作者是每个iter都分别找最佳温度,再sample。
PPO
作者没怎么使用经典的PPO算法,可能是因为训练不稳定?
只在最后一次迭代,也就是RLHF-V5之前用了一下。
流程是这样:训出来RLHF-V4以后,先用PPO增强一波,得到V4-PPO,然后用V4-PPO做rejection sample训练,得出来RLHF-V5
performance
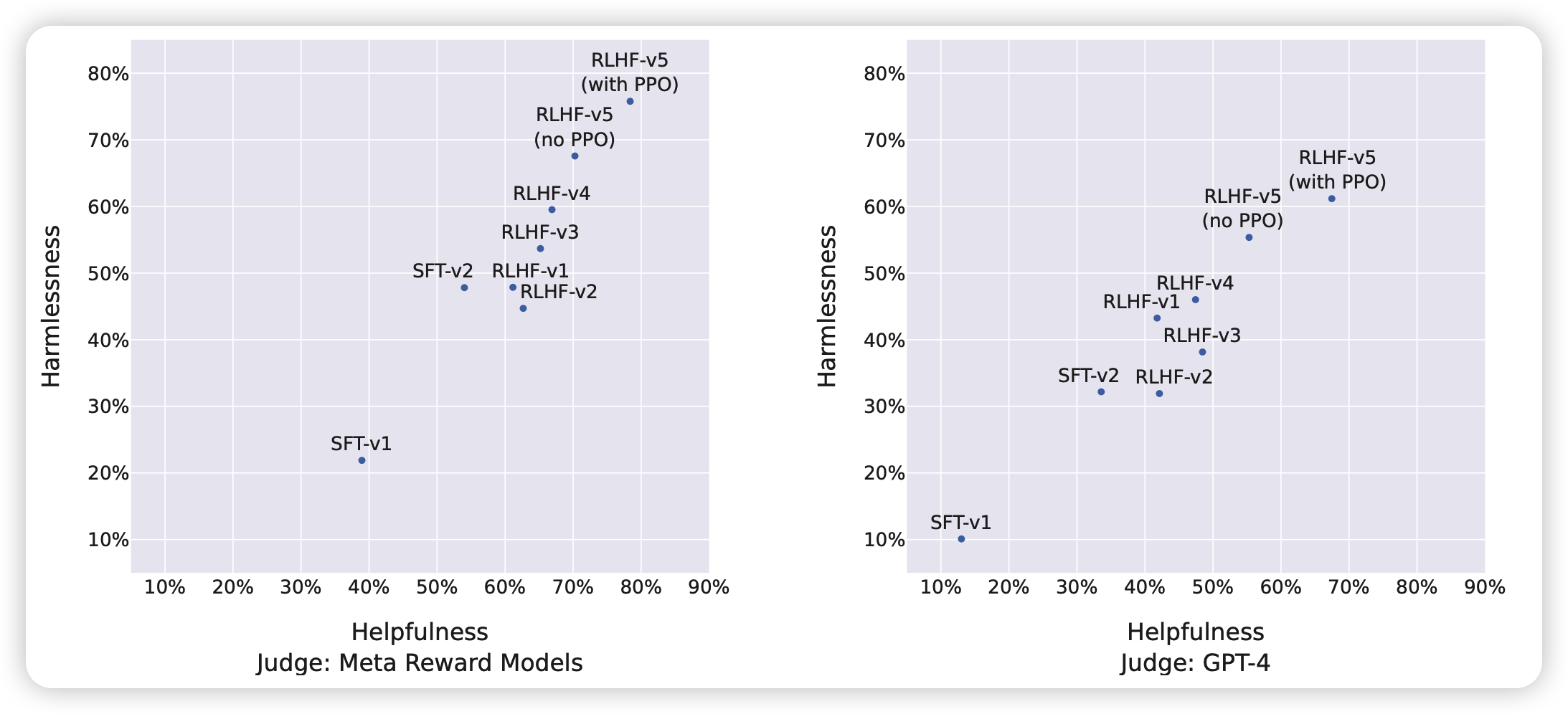
作者首先报告了RLHF的平均水平,这个图坐标是指:战胜ChatGPT-0301的百分比。两个轴分别是帮助性和无害性数据的结果
50%就是说和ChatGPT差不多
可以看出来,效果不错,每轮都在加强。
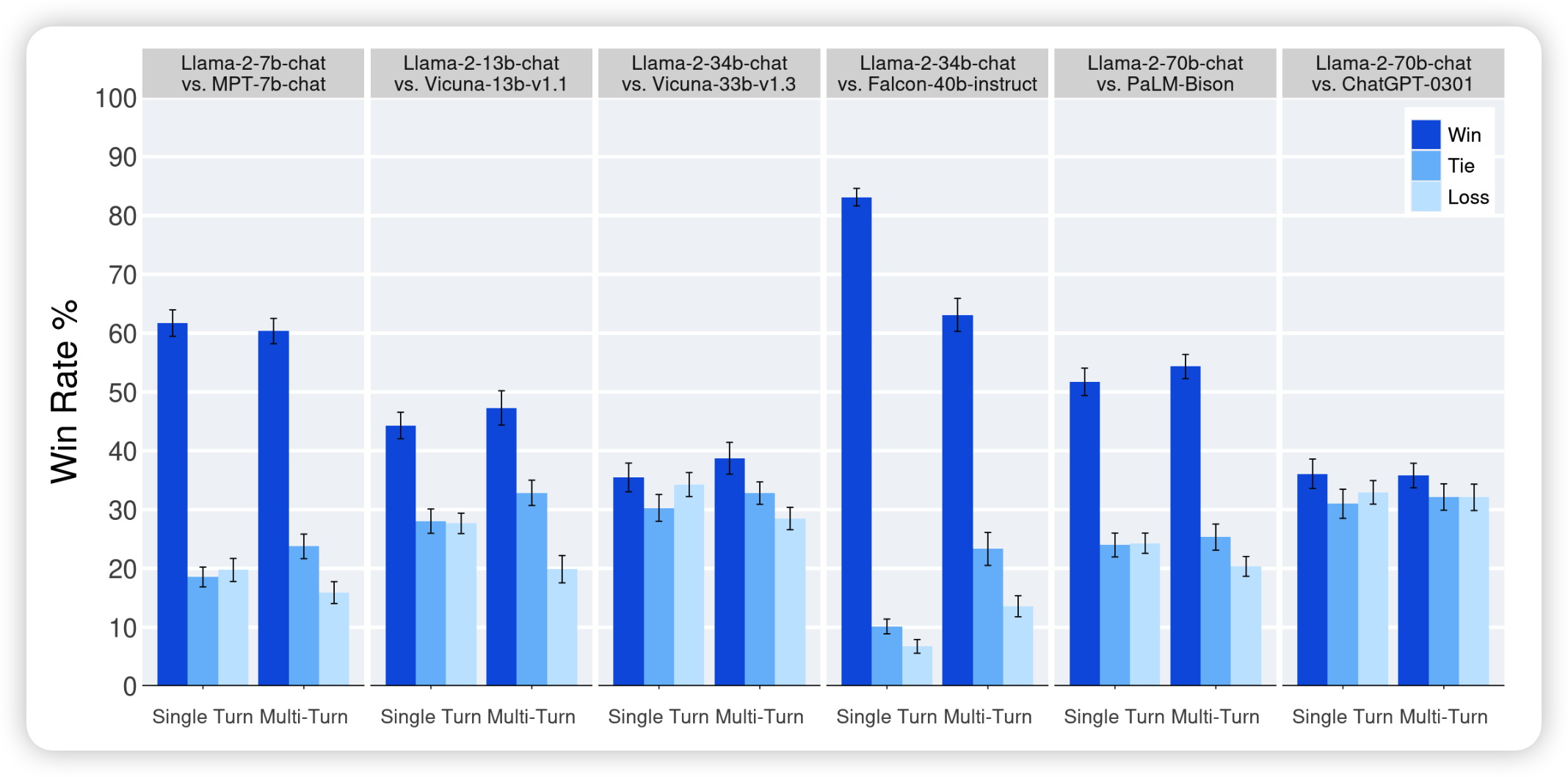
除了机器自评以外,作者在直接让human实验,每个模型的规模级别,都和同规模的类似模型进行了比较。可以看到
- 基本都是赢了
- 不过在vicuna 33b上,似乎差不太多?
- 70b基本和chatGPT一样
我非常好奇的是,有没有更详细的PPO和rejection sample的对比实验,比如PPO+SFT-V1,不过作者没有报告
Ghost attention(GAtt)
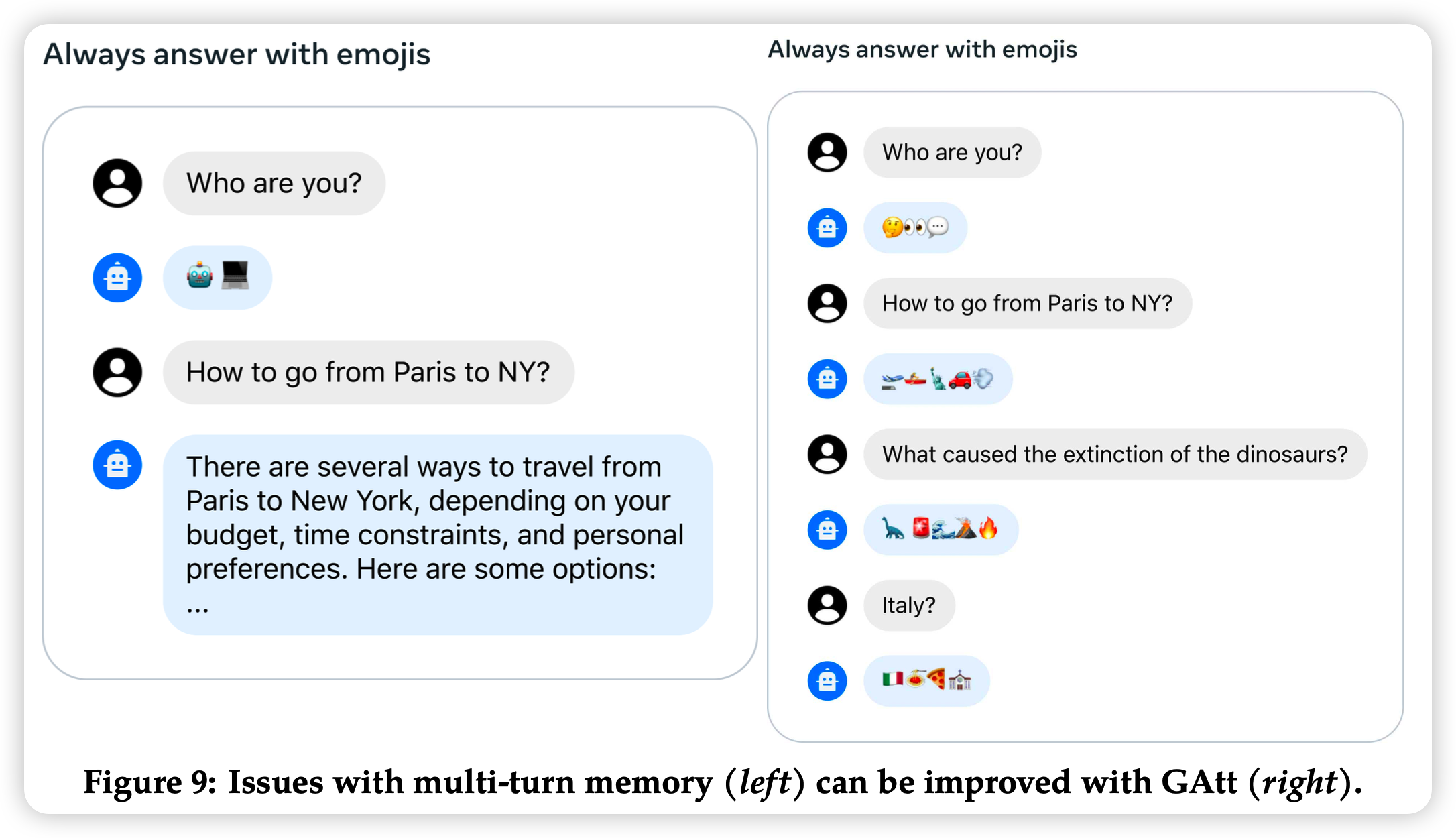
最后还有一个创新点,就是封面那个图。在多轮对话中,模型经常在后面的轮数就忘了最前面的全局prompt
解决方法也很简单:作者把最前面的system message在每个user message前面都复制了一份。作者手动创造了一些好这么做的prompt比如“answer only with emojis”, "act as Napoleon"。然后在SFT query随机中掺杂上这些需求,然后让模型生成这些数据
作者把这件事情默默用在了iter train过程中,就是说在RL用的prompt里掺杂了这些东西,然后每轮对话都加,但是reward model训练没用上,所以不影响reward model的训练稳定性。
测试时没有这个trick,只在system prompt加一次,看能不能维持住

可以发现,不加GAtt,基本上两轮以后前面的prompt已经忘完了,加上以后就一直不忘。
另外,作者在附录里提到一个有趣的事情:
ChatGPT对system prompt也很看重,如果不加system prompt,对比Llama2的win rate就会从44%暴跌到36%
难道说,MOE真的重出江湖?
我的思考
- RLHF部分的探索非常详尽,很久没看到做这么多实验的论文了。够solid
- 看Llama2的总体情况,scaling trend依旧存在,这就给更大更强的Llama3 留出空间了,不知道什么时候能推出
另外,听说OpenAI打算开源一个叫G3PO的模型,不知道啥时候出来...
里面提到的rejection sample非常新颖。其实最近有一些工作就是想用类似SFT的方式来做RL,其实本质上都是对Reward model的对抗训练,差不太多:PRO、RRHF等等。
这里我抛出来一个问题:既然RLHF是在显式地对抗reward model,那我们能不能在运行时进行对抗呢?
human preference虽然不会变,但是还有很多preference和下游绑定的任务。其实这就是LLM搜索类的算法:ToT里面引入了一些这种in-context对抗的特性,后面我们会进一步指出和解决这个问题。
- 类似RRHF和rejection sample,是在多个样本中learning from best of N,那么显然这个方法的效率取决于最优score寻找的过程,相同搜索资源下,最优score越高,用这类算法的效果就越好。那么,这是不是也预示着我们需要一个更好的搜索算法呢?
- 虽然叫"开源",但其实Llama 2不是完全开源的……pretrain数据和SFT数据就没给