今天openAI发布了GPT-4。直接把PaLM卷到开放API了,相信google是真的被卷麻了。
GPT4附赠了一个98页的报告(没有论文),报告前面是性能和应用报告,中间是一些附录,最后是技术报告。我就按顺序来给大家讲讲,先讲应用报告。相信很多公众号大概都吹了一波GPT4,我希望我的讲解可以更深入一些,把问题、难点和领域更多地呈现给大家。

作者团队来自openAI,比较神奇的是前面没写作者。报告里把贡献名单放到了最后,足足有3页,按照职能划分。一般的电影里的名单都很长,但大家都不会看完,但这次大家都看得很仔细,试图通过人员分布来发现openAI技术投入的侧重点。值得深思

Introduction
整个应用报告部分其实没有什么技术,有点像是发布会吹牛逼部分的文字版,带有非常多的实验与结果。总体而言,GPT4比GPT3的区别可以总结为以下几点:
- GPT4支持KOSMOS类的图片输入
- GPT4有更好的多语言能力
- GPT4比GPT3.5有更好的事实能力,并且极大地提高了”安全性“
- 在简单问题上,GPT4和GPT3.5区别不大,只有问题复杂性达到一定地步以后,才能拉开差距
除此之外,关于,模型细节,报告没有任何提供细节,只说了这样一段话:
This report focuses on the capabilities, limitations, and safety properties of GPT-4. GPT-4 is a Transformer-style model [33] pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers. The model was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [34]. Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
我为大家提取一下关键点:
- transofmer-based,但没说一定是transformer结构。
关于这一点,如果读了最近很多论文linearAttn等等,就会发现什么都能和transformer-based扯上关系,连CNN四舍五入也算transformer。所以这个说了等于没说,也不知道openAI做了什么优化使得大模型训练表现得稳定而且优异。
- 基础模型按照auto-regressive方式训练:嗯,唯一的关键点就是,一次生成一个token
这一点上,虽然报告没说,但我们得知GPT4 的sequence-length打到了32768,比之前3.5提高了4倍。在这一点上,如何节省显存,如何构造寻找真正符合长度的、好的训练数据,都是很难、很值得研究的方向。
- 没提训练数据的任何信息,也没提代码数据的来源
- 没提模型规模,和模型结构
- pretrain结束以后,使用了RLHF。但RLHF的过程、数据规模没提
模型规模一直是大家期待的一个点,之前有人说大到1000B,也有人说小到10B,结果最后一点没提。
Predictable Scaling
power-law
这一部分很有意思,作者提到经典的大模型训练很难调参,因为经典的一次run就已经开销非常大了。GPT4开发出了一种基于power-law的方法可以在低至10000倍的训练时间下,就很吻合地预测出最终在下游任务上的表现。使用如下公式: \[ L(C) = a C^b + c \] 对于复杂的pass@k之类的指标,使用更复杂的拟合等式: \[ \mathbb{E}_p[\log (\text{pass-rate}(C))] = a * C^{-k} \]
大概是用前面ckpt的测试结果拟合a、b、c,不知道之前大家有没有做个这件事情。
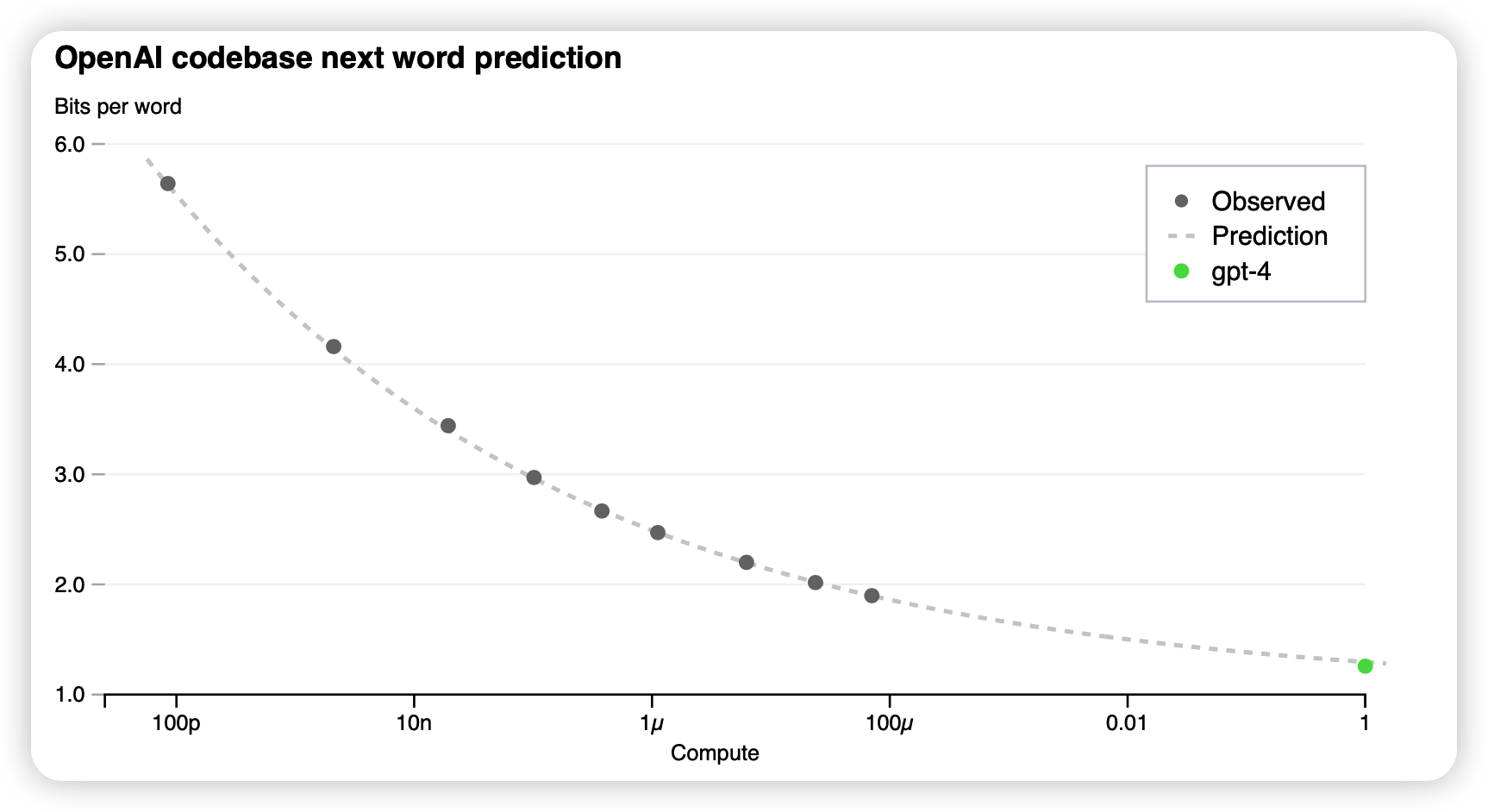
我相信openAI内部一定是尝试了transformer的各种变体,对于各个任务做了这么一个工作流,然后每个变体都试了试,拟合一个最终loss,最后决定了具体使用怎样的模型结构、训练超参。
另外,这个拟合结果这么好,足以说明transformer真的是非常符合power-law的,以及现在的所有模型还都没有撞到性能墙,可以继续扩大规模、扩大epoch地训练下去。
Inverse Scaling Prize
这一部分,作者还额外提到了一个任务类型:探索一个随着模型大小增长,表现越来越差的任务。
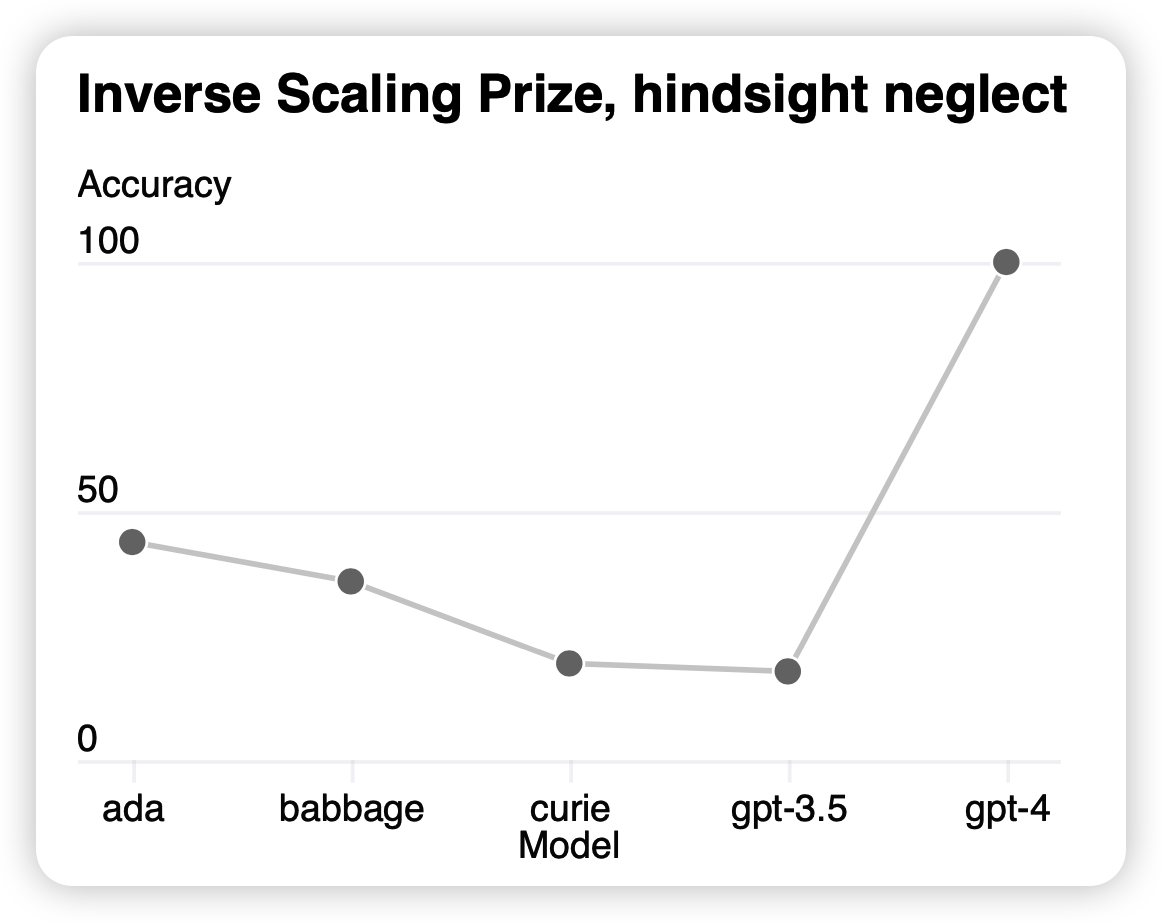
之前有一类工作专门找到了这样的数据集,作者提到:GPT4在这里表现出了相反的情况,效果打到了100%。这里我想提两个关键点
- 首先这个”相反趋势“不是首创的,我记得之前PaLM里面好像就提过这个事情,说到了"U型"的趋势
- 最起码在这里的语境下,表明GPT4不是一个”小模型“,之前10B的论断可能不太准确。
capability
这一部分,作者系统性地吹了一波GPT4的表现,我就找一些比较好的实验来说一下吧。
exam result & academic benchmark
这里包含三个实验,
- 作者首先在比较有名的人类考试里召集实验者和GPT4,GPT3.5进行了笔试,发现GPT4基本可以排在前10%,而3.5只能排在后10%。
- 后者,academic benchmark就是指传统的score。作者发现GPT4在几条样本few-shot的情况下,基本可以战胜所有对任务做了额外优化的训练方法
- 对于RLHF的性能,由于训练是human,评测也只能human。作者说基于GPT4的RLHF比ChatGPT的版本,人类有70%的概率觉得更好。

多语言
为了评测多语言性能,作者把认可度比较高的MMLU多类别选择题数据集翻译成了26种语言,并且输入给GPT4进行学习。发现在这些语言上做的都非常好。
这其实是一个很神奇的地方,我们虽然不知道数据集情况,但可以想见某些小语种的数据一定不是很多。但模型随着某种语言(英语)的学习,竟然就能表现出很好的泛化到多语言的能力。这是不是说明人类的语言内在的相关性其实是很好把握的?
另一个思考的层面是,这个实验没有做GPT3.5以及PaLM等的版本,不知道这种“对于多语言的理解泛化能力”是不是和in-context learning能力类似,是随着模型基础性能的提升才“突然地”激增出来的。这也是值得我们探索的问题。

这里可以看出一个趋势,对于大模型来说,传统的academic score其实并不能说明什么,大家已经刷的很高了,而且score高和human prefer其实没有很大的相关性。最后主试验还是要通过”在human exam上比较排名“的方式,某种程度上已经说明了评测领域的不足和缺陷。
想必openAI也注意到了这一点,专门提到他们开源了所有测试的代码(OpenAI Evals),已经GPT4在每条数据上的结果,来帮助大家对自己的模型进行评测,后续也会完善这个框架。估计评测的问题应该会吸引更多的关注吧。
图像
这就是作者的另一个卖点,输入图像。其实用Autoregressive做图像输入,openAI早有先见。最开始的DALL.E 1,就是把pixel表示直接通过Autoregressive输出来实现图像生成的。
作者虽然没有提具体的细节,但现在主流的方法PaLM-E等都是用一个专门的图像编码器来编码图像,然后作为"token embedding"注入到sequence里面去的,不知道openAI是不是在自己DALL.E 2那个不开源的超级text2image数据集上整了个新的图像编码器。但看起来能力确实很强。

不只是输入,在这里我还是觉得以后可以像versatile diffusion一样做出图像模态的输出来,直接套一个类似DALL.E 2的unCLIP prior模型大概就能有模有样。我甚至怀疑,他们已经做了,只是效果不尽如人意,或者“存在潜在的偏见和风险”,所以没有放出来。
另一方面,关于这种图像输入的模式,不知道是谁先发明的。虽然Kosmos说他们是 the first step,但我们从GPT4技术报告可以看到:其实GPT4早在去年8月份就已经训练完成了。
走向多模态、通用性,才是未来大模型的发展方向呀。
limitation
这一部分,作者分析了事实性错误、幻觉现象、偏见、危险内容等等信息,大致得出了两个结论:
- GPT4的安全性比GPT3.5大大提升
- 但是GPT4也没有“很安全”,大家谨慎使用

上面这种图我不是想说score的高低,我只是想吐槽:什么时候chatgpt都有v2,v2,v3,v4了,我怎么我感觉我火星了……
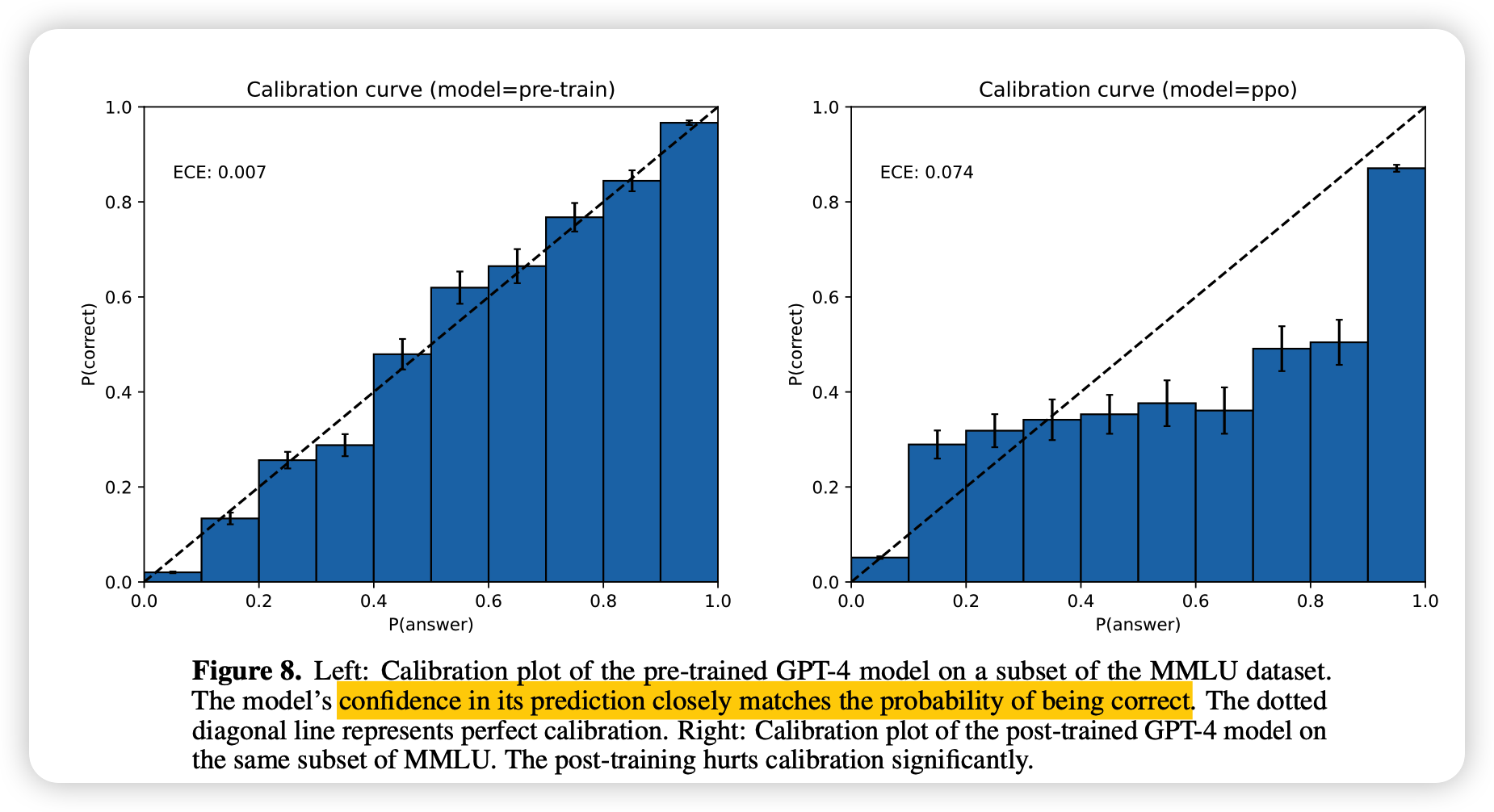
作者在MMLU做了一个很有意思的自检测实验:
模型自己认为置信度高的回答,很可能最终的置信度就是真的很高。
这个结论比较符合之前的研究结果。某种意义上,这说明模型自身对于所谓“安全性”是有一定认知的。但作者走的更进一步,也检测了RLHF后的模型,发现这种偏序关系基本消失了。
我认为,也许RLHF或者类似的方法,更重要的是通过模型参数一些小小的迭代,激发出来模型对于自身输出回答的可靠性的认知。所以RLHF模型自己丧失了偏序能力。这也许侧面说明,我们有可能通过更简单的方法,比如prompt等,达到RLHF的效果(当然,RLHF的单步RL假设已经够简单了……
最后作者总结了文章的贡献,并且很自信的说了一句:
Though there remains much work to be done, GPT-4 represents a significant step towards broadly useful and safely deployed AI systems.
我的思考
一篇看下来,感觉最大的震撼是:openAI的一切基本都是自己的,而且所有层面都是领先的
- 自己提出的Autoregressive训练方法
- 自己研发的高效训练平台
- 自己制作的闭源数据集
- 自己创造的评测框架
- 自己聘用的人工评测、安全性评估专家团队
回过头想想,之前GPT1被BERT迎头痛击以后,openAI还是没有放弃Autoregressive,一直在迭代版本,不知道积累了多少idea和失败的实验经验,几年下来,已经和我们形成了技术壁垒了。98页的报告其实说了很多,但也什么都没说。我们想要赶上,最起码得在最少一个层面做出自己的突破呀。
当然,我们也有一些自己的优势,比如最起码,我们不用饱受“安全性、偏见”的困扰。也许对我们来说,只用技术报告最后一句话的前半句更合适一些:
There remains much work to be done
是机遇,也是挑战,可能挑战更多一些。与君共勉。
以上内容由GPT4生成(bushi