今天来和大家读一篇非常有趣的分析性文章,卷积网络和Vit学的隐层表示有什么区别?模型眼中的世界是一样的吗?

这是一篇NeurIPS 21的文章,作者团队来自Google Brain。这个作者好像是LSTM的作者?
动机
文章主要探索一件事情:CV领域的ViT,其实没有引入卷积网络的归纳偏置:
- ViT没有对临近的图像区域做专门的处理,conv其实是按局部去滑动。
在这种情况下ViT的效果依然很好,那么他们两种网络学到的图像表示有没有什么联系呢?ViT有没有重新学到conv给定的归纳偏置呢?
这个问题是很好的问题,但是所谓的”图像表示之间的关系、相似度“该怎么衡量呢?我们可以实验性的定义”linear probe的结果“代表图像表示的好坏,但相似度又该怎么衡量?毕竟两个模型、甚至一个模型的两次初始化学到的表示空间可能就完全不同,图像表示只有针对不同图像的差值、夹角、模长等可能有意义。
linear probe:锁定整个模型,只是把图像表示拿过来后面跟一个linear层,然后做下游任务,比如分类。这个调节的参数很少,但效果基本远不如full size fine-tune
实验
作者在这里引入了一种非常有趣的衡量方法:CKA, centered kernel alignment
这个方法是这样,对于两个模型,先扔进去m个样本得到m个表示: \[ X \in \mathbb{R}^{m\times p_1} \quad Y \in \mathbb{R}^{m\times p_2} \] 接下来算Gram矩阵 \[ K = XX^T,L = YY^T \] 接下来计算Hilbert-Schmidt independence criterion ,构建出来一个中心矩阵 \[ H = I_m - \frac{1}{m} \vec{1}\vec{1}^T \] 用中心矩阵来做中心化 \[ K' = HKH,L' = HLH \]
\[ HSIC(K,L) = \frac{vec(K') ·vec(L')}{(m-1)^2} \]
有了HSIC算子以后,对两个矩阵用HSIC算子做cosine就行了 \[ CKA(K,L) = \frac{HSIC(K,L)}{\sqrt{HSIC(K,K) · HSIC(L,L)}} \] 这个变换
- 对于两个矩阵分开的正交变换具有不变性
- 对于矩阵表示的模长好像也是无所谓的
- 我理解CKA值越大,好像代表两个矩阵通过的变换距离的模比较小?
作者有了CKA方法以后,都是用一个minibatch来模拟真实的CKA结果
两个模型表示的区别
接下来作者先看了模型自己层和自己层的表示的CKA对比
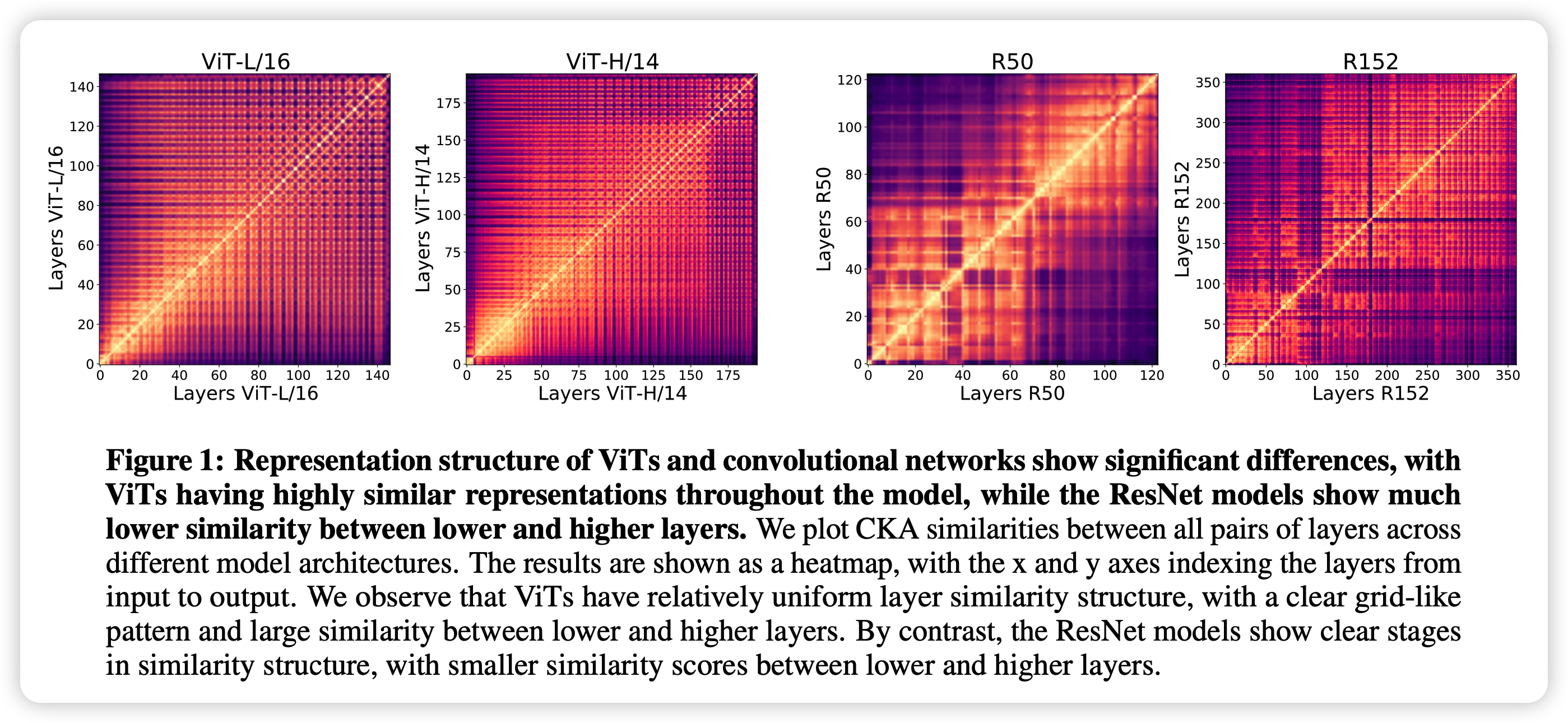
就是说单拿出某一层的表示和另一层的表示,当做两组表示计算CKA。这个值高(亮)就代表两个层出来的表示具有更强的相关性
可以发现:
- 对于ViT,图像基本是一样的,也就是每一层学到的表示都很像,随着层数距离变大,表示慢慢均匀地变不像,但总体相似度还是挺高的
- ResNet有明显的两个块,底层和上层学的表示差距很大
接下来作者做跨模型对比,把两个模型不同层的表示做CKA,得到下面的结果
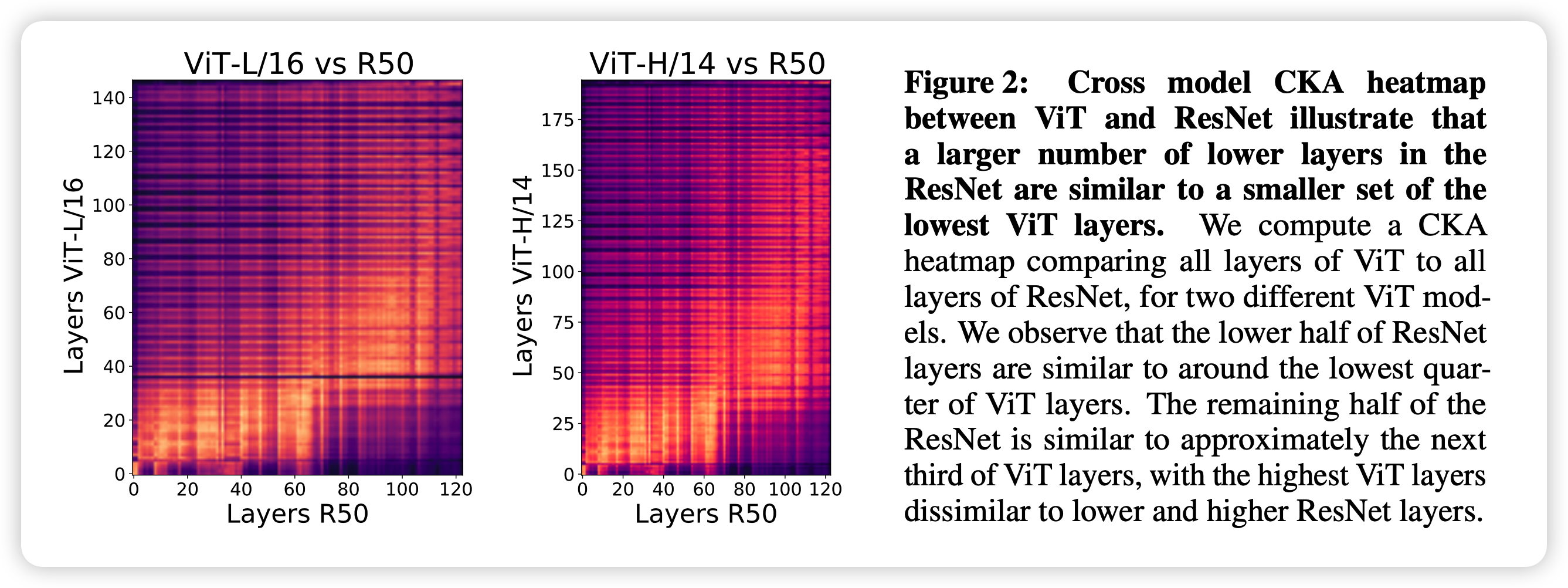
- ViT前1/4的层表示和ResNet前1/2的表示接近
- ViT中1/3的表示和ResNet后1/2表示接近
- ViT后1/3的表示和ResNet任何地方都不同。作者认为这些层可能主要在优化CLS的表示,毕竟ViT是有监督的训练
总结一下,作者得到了以下结论:
- ViT下层和ResNet下层表示有较大区别
- ViT表示在层间有很强的继承关系
- ViT的上层表示和ResNet有很大区别
全局与局部信息
接下来作者想要探索ViT是不是重新发现了conv的局部性归纳偏置,具体作者这么算的:
transformer layer里面要先算key * query,作者直接把5000条数据里的query矩阵乘积算出来,就是模型希望去询问的东西,由于self attention,其实最后就是这些query互相乘。然后作者算两个query的像素距离。
就如果两个图片patch离的近,他们的query像素距离也近,说明模型学到了local信息
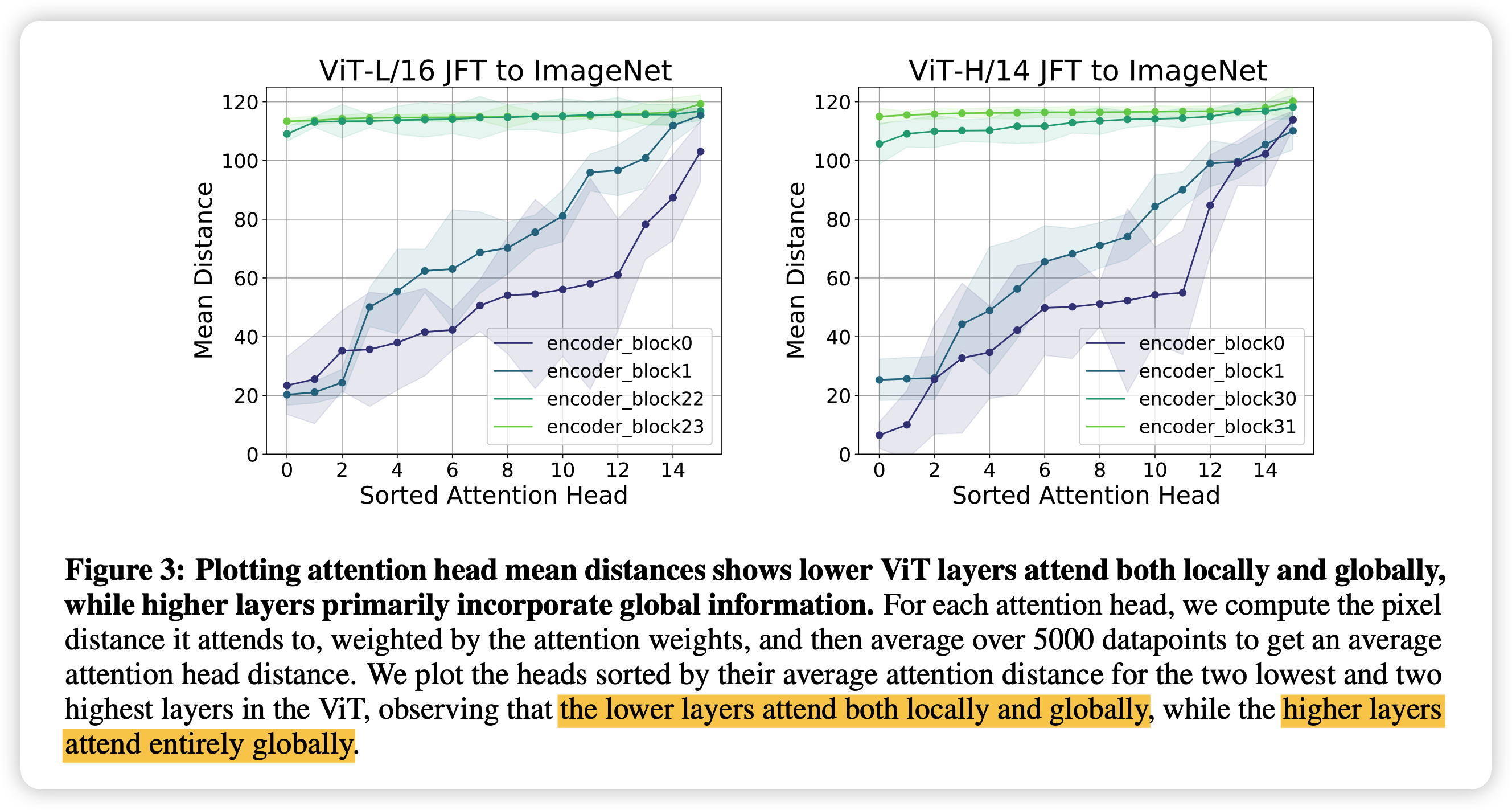
作者发现,对于低层,确实距离近的patch, query也相似。但对于高层的block,这个相似性就消失了。对比之下,conv在底层由于实现,只能关注更局部的feature.
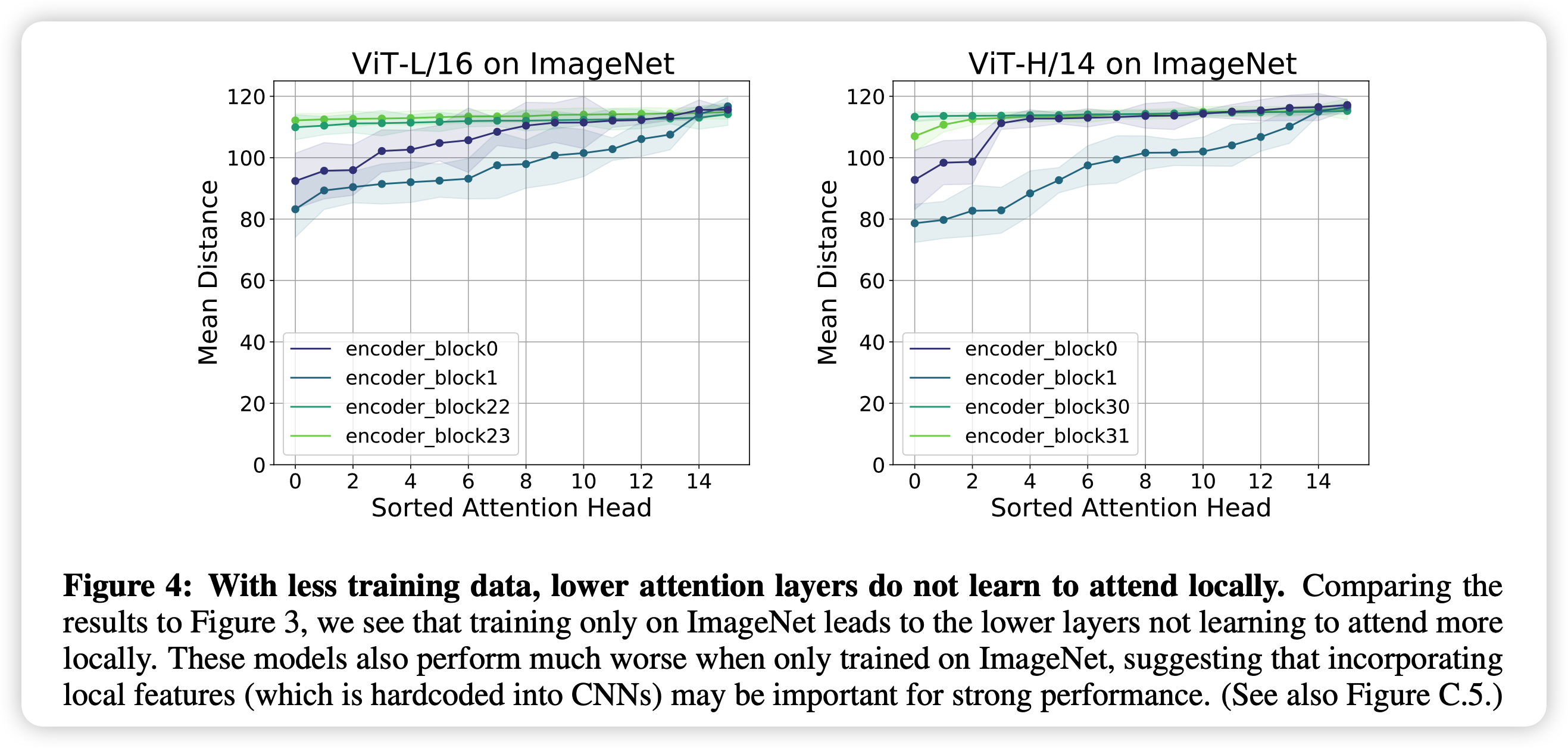
接下来,作者做了更有趣的实验,作者只在imageNet上炼了一个ViT(小的pretrain dataset),发现这种重新发现的局部性原理竟然消失了,说明ViT其实需要从非常多的数据中总结出这种规律。
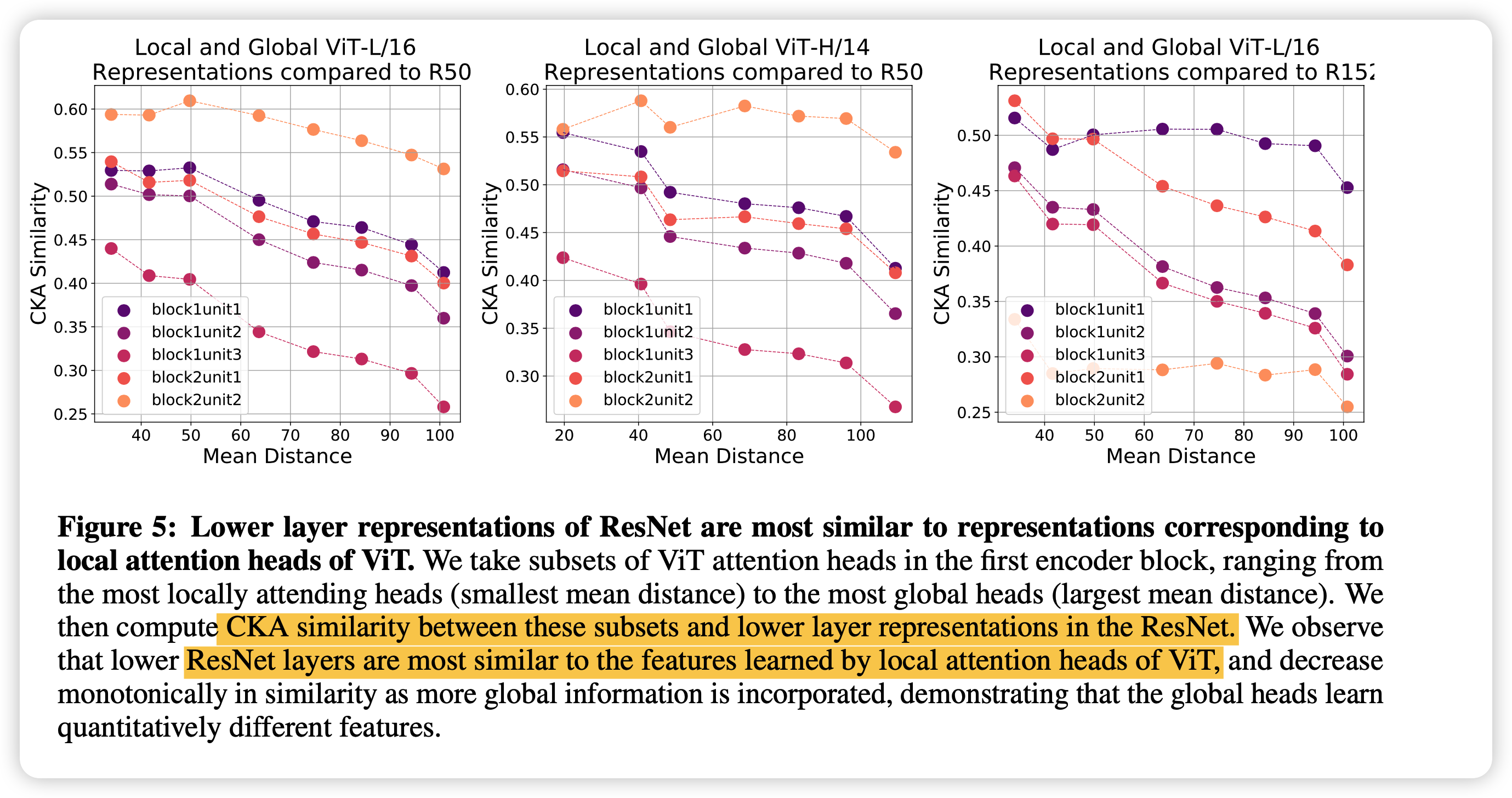
ViT这种局部性学到的feature和conv的一样吗?接下来,作者试了局部性最好的head和ResNet里面做CKA,发现结论是肯定的。
skip connection
接下来作者衡量了skip connection对ViT这种学习的影响,定义了一个量 \[ \frac{||z_i||}{||f(z_i)||} \] 代表从skip connection出来的表示的模长除以long-branch算子出来的表示的模长。假如这个值很大,说明long-branch算子的影响很小,结果以skip-connection继承之前的东西为主
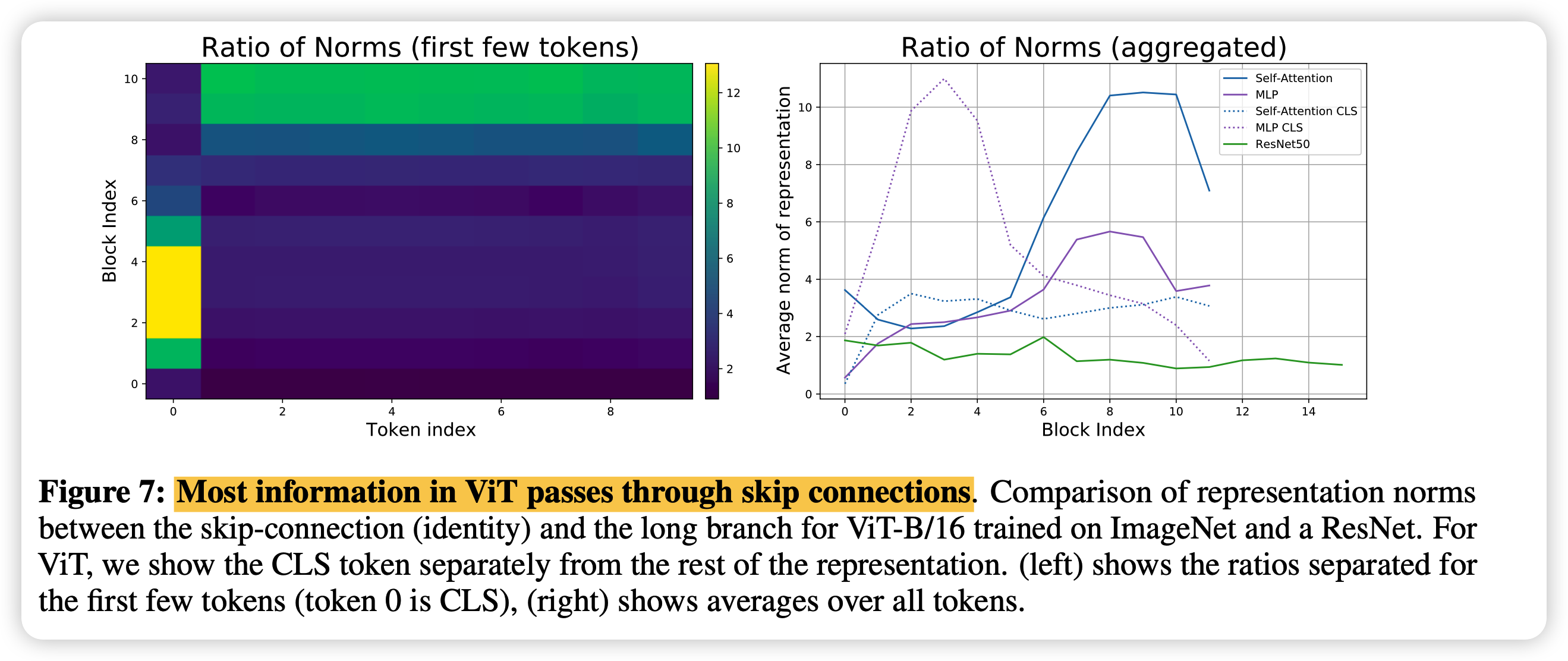
作者发现CLS token(token 0)和其他token不一样:
- CLS在前面基本都是继承,直到后面才开始使用long-branch里面的东西
- 正常token都比较接近,前面要看互相的关系,到后面以继承为主
右边的图对比了ResNet,可以发现conv就比较平均,每一层都在看互相的量

接下来,作者尝试在ViT某一层去掉skip connection,发现ViT马上出现了这种明显的分块。也就是说,ViT的这种不同层表示之间的CKA相关性,基本就是由skip-connection带来的。
空间位置信息
作者继续探索了ViT在高层还能不能保持图像之间的空间关系,毕竟上层基本都是看全局信息
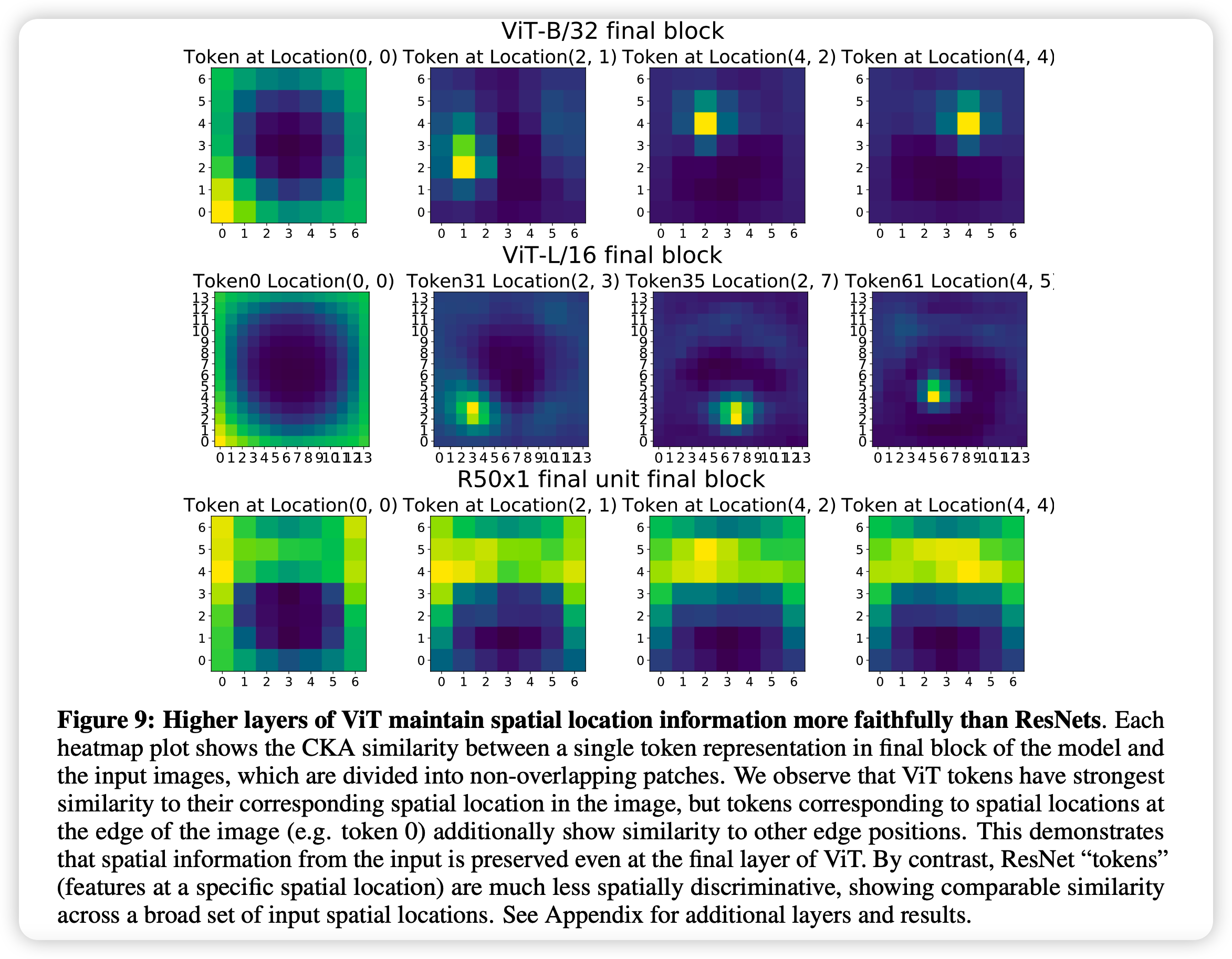
对比之下可以看出,ViT在高层对于空间关系的保持性比ResNet好很多。作者提出一个猜测:
- ResNet训练任务是用average pooling,而ViT是用CLS分类头。显然前者需要高层的表示比较接近
作者做了个对比实验,训练了用average pooling的ViT
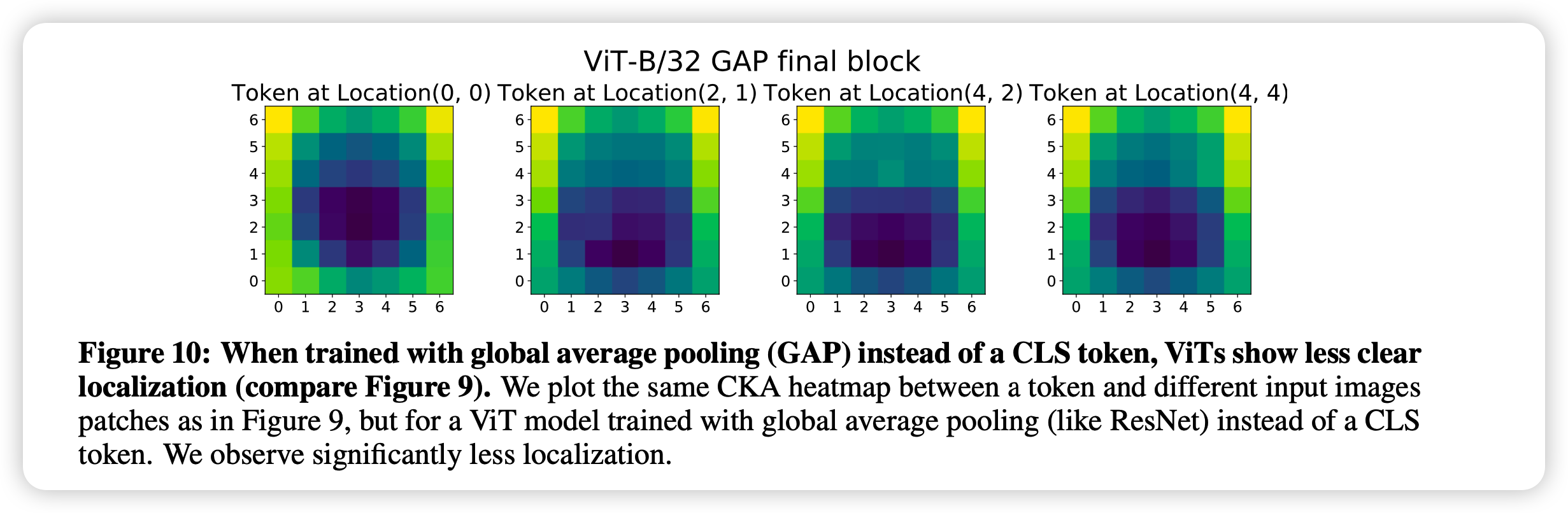
一下子,ViT也不行了,这佐证上述猜测。
接下来作者又探索了使用别的token能不能做linear probe。
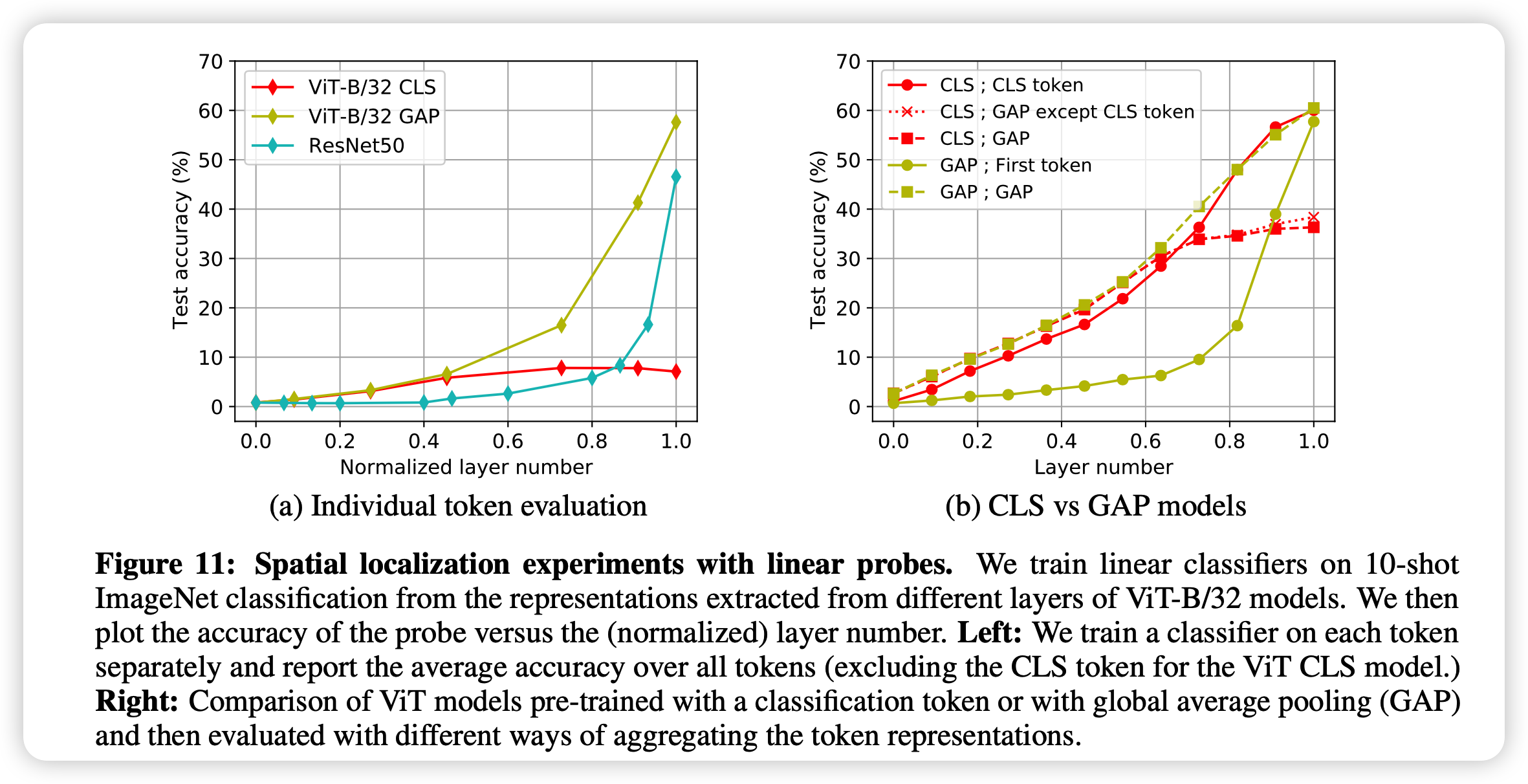
左图作者试着用不同比例的token一起做linear probe,右边是单独ViT的对比
可以看出来,用CLS做训练的ViT下游任务一但没有CLS token,就寄了
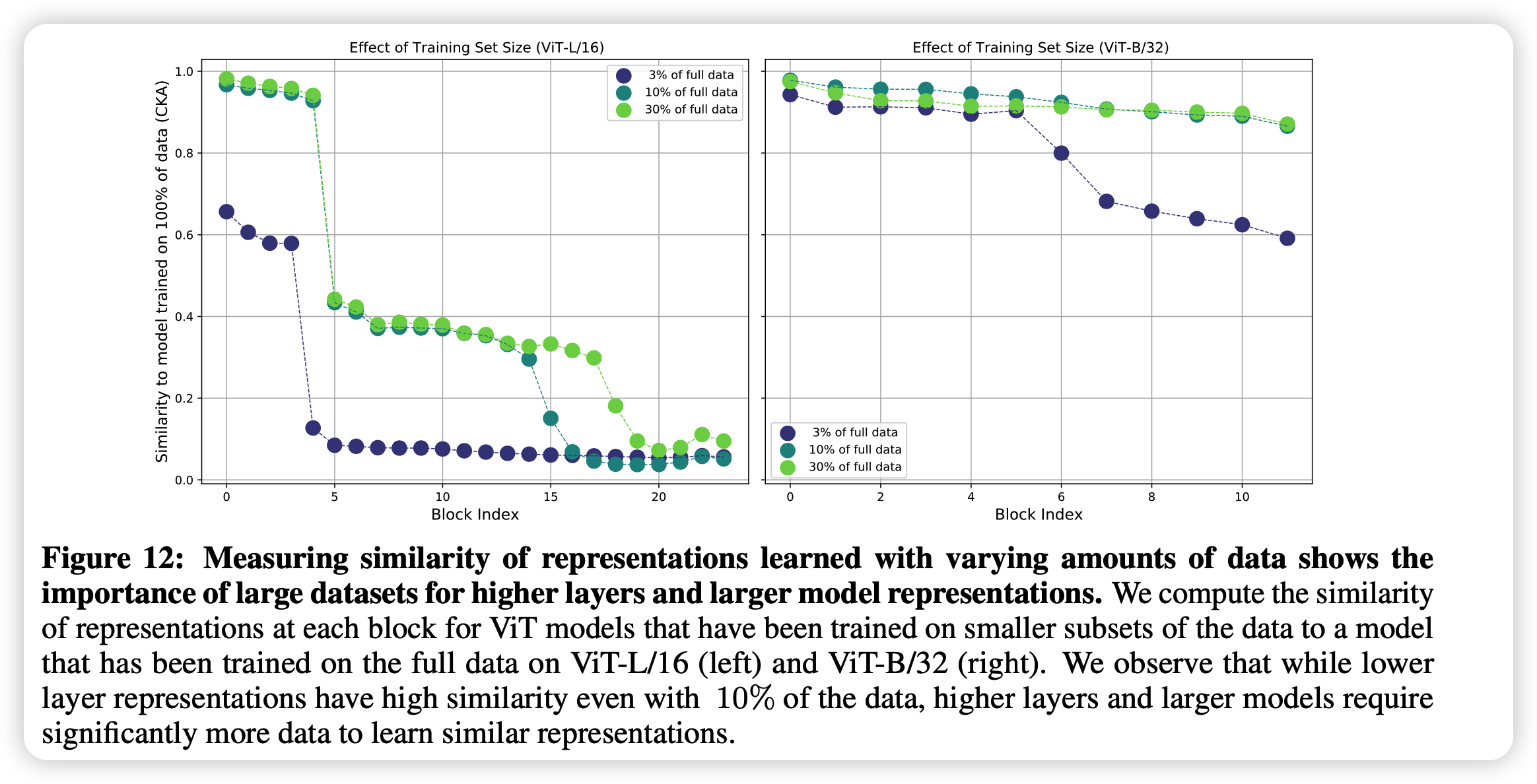
最后,作者做了一个数据规模实验:
首先试了在不同训练数据规模下,用不同层的表示做实验。发现即使只有3%的数据,在低层的时候学到的表示也差不多了。只是在高层的表示需要更多的数据来学习
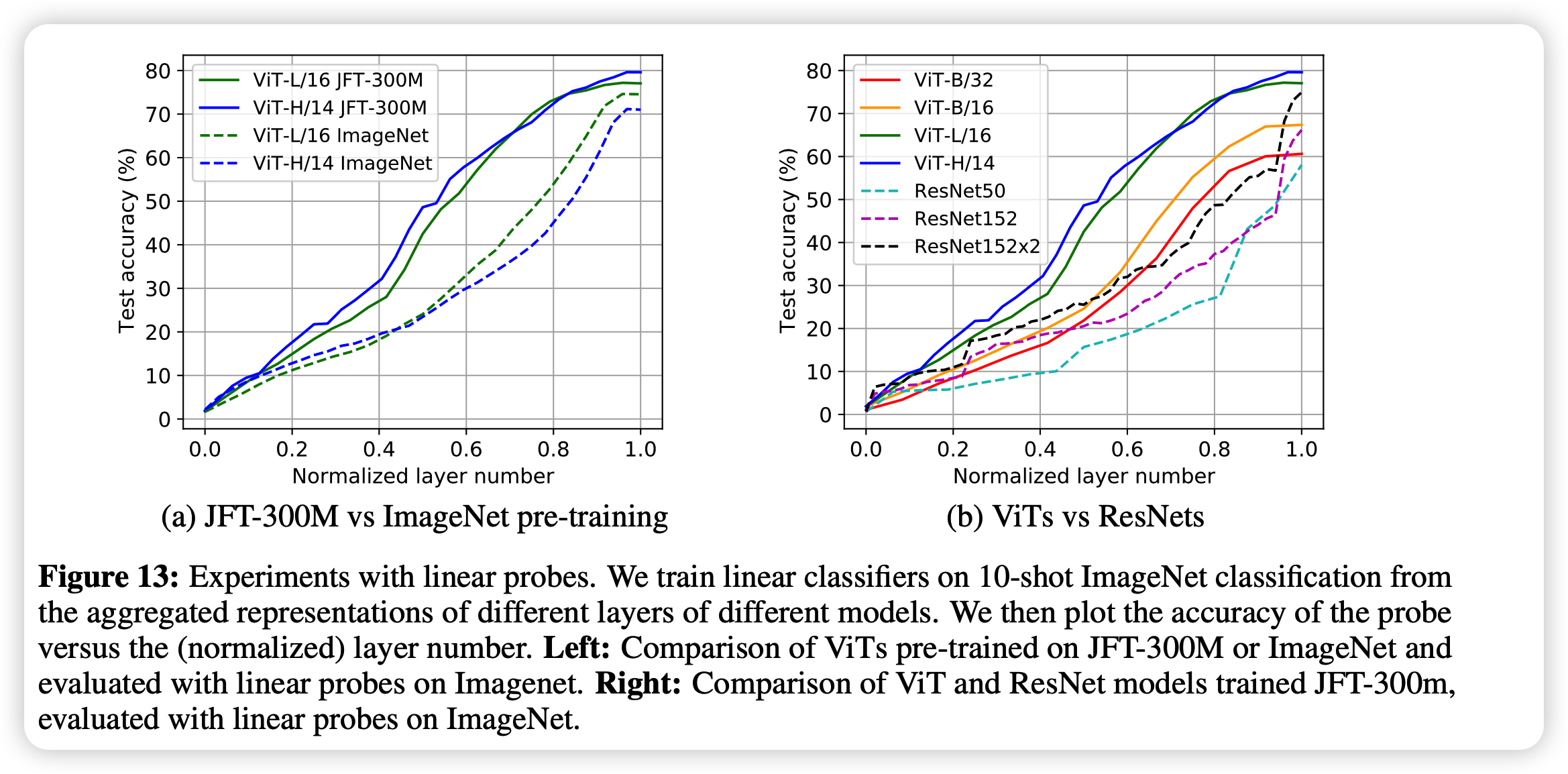
后面,作者常规地试了试数据规模和迁移能力的实验,得到了多就是好的常规结论
思考
- 这篇文章是一个经典的分析性文章。作者的实验设置值得学习,尤其是很多对比实验的思路,self compare,cross compare的实验设计
- 有没有人试过MAE和普通ViT的对比呢?感觉这种自回归的方式很可能更接近ResNet?
- 进一步,这种思路是不是也可以对比NLP这边encoder based和encoder-decoder based模型得到的表示
- 在新的模型结构出来以后,比起直接在下游任务用起来,这种对模型表示的探索也许更值得学习