Qwen3-Omni Technical Report
作者用一个模型,同时支持了text、图片理解、视频理解、音频理解四种能力。核心是在vlm的基础上,又添加了audio token
开源,就是源神

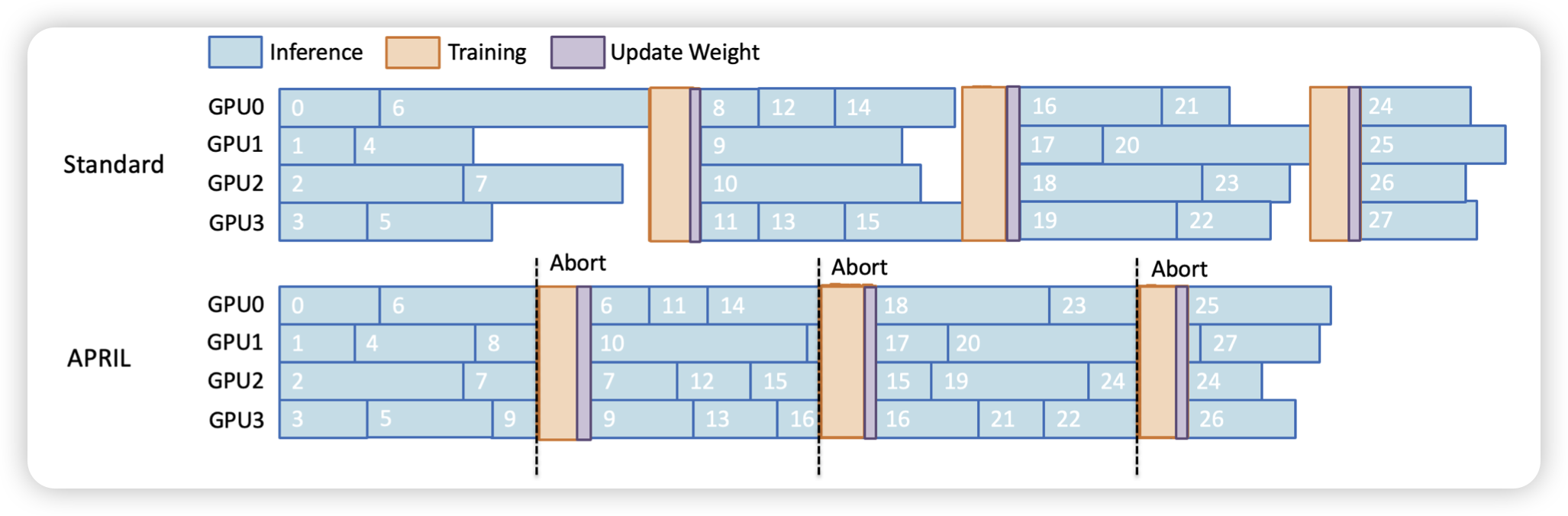
APRIL: Active Partial Rollouts in Reinforcement Learning to tame long-tail generation
这是一篇rl过程中的rollout加速的工作。作者主要的发现是:在rollout过程中,每个step的rollout显卡利用率都是会越来越低,因为80%的traj会在20%时间结束。如果这个时候,让dataloader立即load下一条数据呢?作者发现这样单位时间,可以多roll 44%的数据
代价是一部分数据,会由之前的参数得到,而不是最新的参数。这样会牺牲一部分rl性能
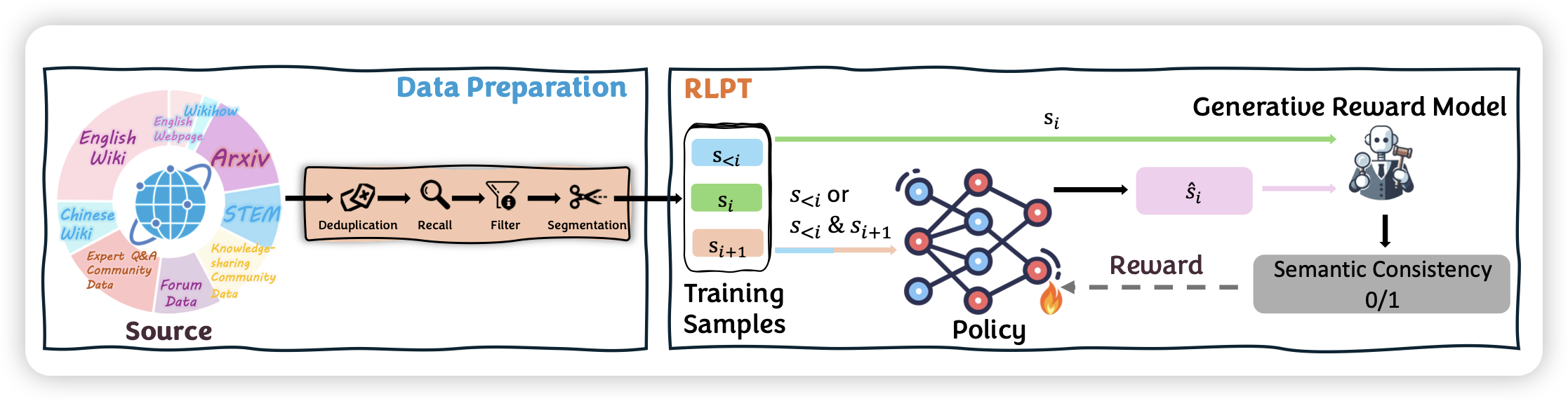
Reinforcement Learning on Pre-Training Data
这篇论文名字挺有趣的,有点像是pengfei老师前几天那个在sft上做重要性采样的工作,但其实讲的不是这个故事,而是直接改变了训练范式。正常的pretrain是给出一个语料,然后让模型做一次forward一次backward,训练模型去说一模一样的东西。如果用rl的视角看待,那就是:能不能给出前半段,让模型接着生成,如果和后半段接近,就给reward奖励。变成了multi-forward的形式
聪明的小伙伴马上发现,如何定义“接近”会成为这个系统的瓶颈。但作者认为,只要够scale,不准确也无所谓
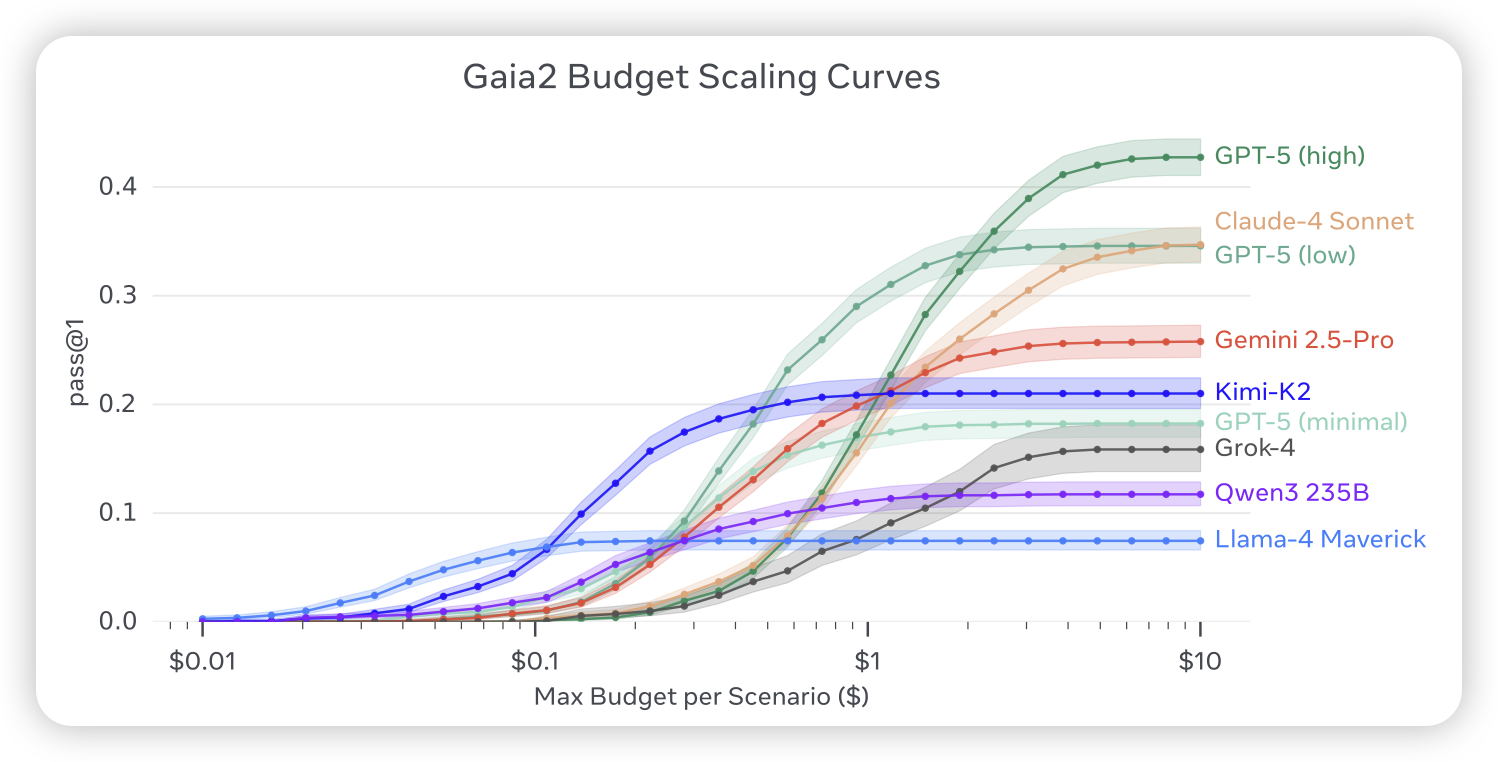
ARE: scaling up agent environments and evaluations
gaia很火,是现在大家基本都会刷的benchmark,今天作者更新到了gaia2。作者这次还开源了agent测试环境给大家,里面有一些mock的app/mcp,可以让模型随意调用。然后题目也从原来的search-based,多了一些execution-based的题目
gaia1被大家刷到快80了…