The Unreasonable Effectiveness of Scaling Agents for Computer Use
一篇比较有意思的cua工作:作者让模型在测试时,直接做多个traj,然后用一个投票机制选出来一个看起来最靠谱的提交。用这种方法,把osworld分数刷到了70分
这个方法有一个问题是,一个测试需要固定初始化方案,多次初始化。这可能是一个新的刷分赛道?
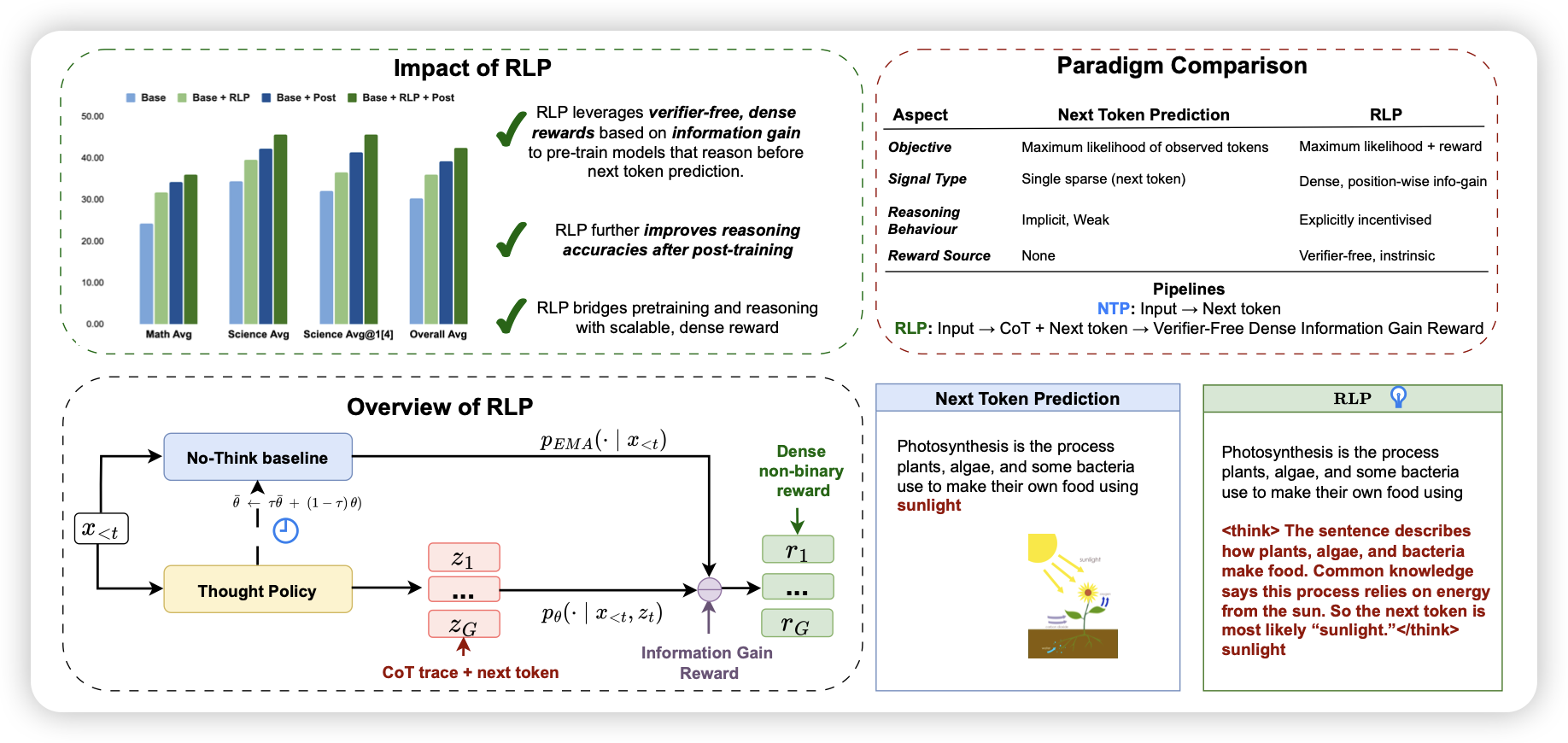
RLP: Reinforcement as a Pretraining Objective
yejin choi参与的工作。前几天我正好做了一篇"rl pretrain"方向的阅读笔记,这篇也可以算做这个方向的一个尝试。作者认为,正常的pretrain过程中,如果考虑long-cot,那么可以认为cot是一种“信息增益”的过程,如果能降低后文的ppl,就是有益的。作者反过来,直接把ppl作为cot的奖励,让模型在预训练数据上无监督地一直过数据。
这篇工作和我的本科毕设基本一模一样…但是我的ppl baseline不是ema版本
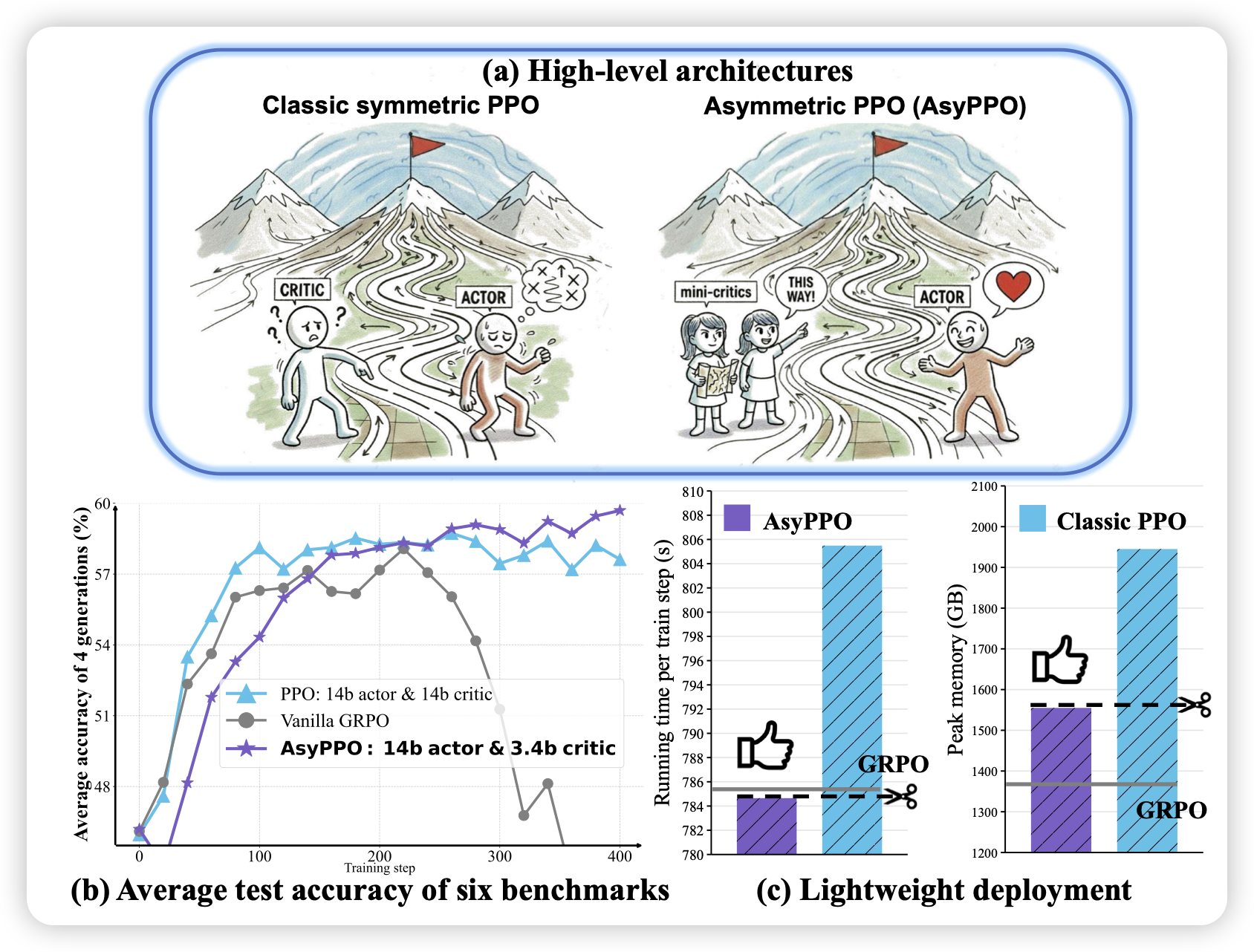
Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning
actor-critic模式,从最开始就认为是actor和critic应该是同等算力的。但在long-cot场景中,作者发现,由于reward很稀疏,value model效果不好,现在的grpo等算法甚至直接丢弃了critic,转而用group_adv来作为rl_baseline。那么,critic真的没有用了吗?作者实验了用一个参数小很多的critic组来作为rl value model,发现这样是效果还不错的
我之前好像确实没看过有人用不同型号模型做actor-critic的…那反过来想,如果critic比policy大10倍,能更好的预测到value解决reward稀疏问题吗?