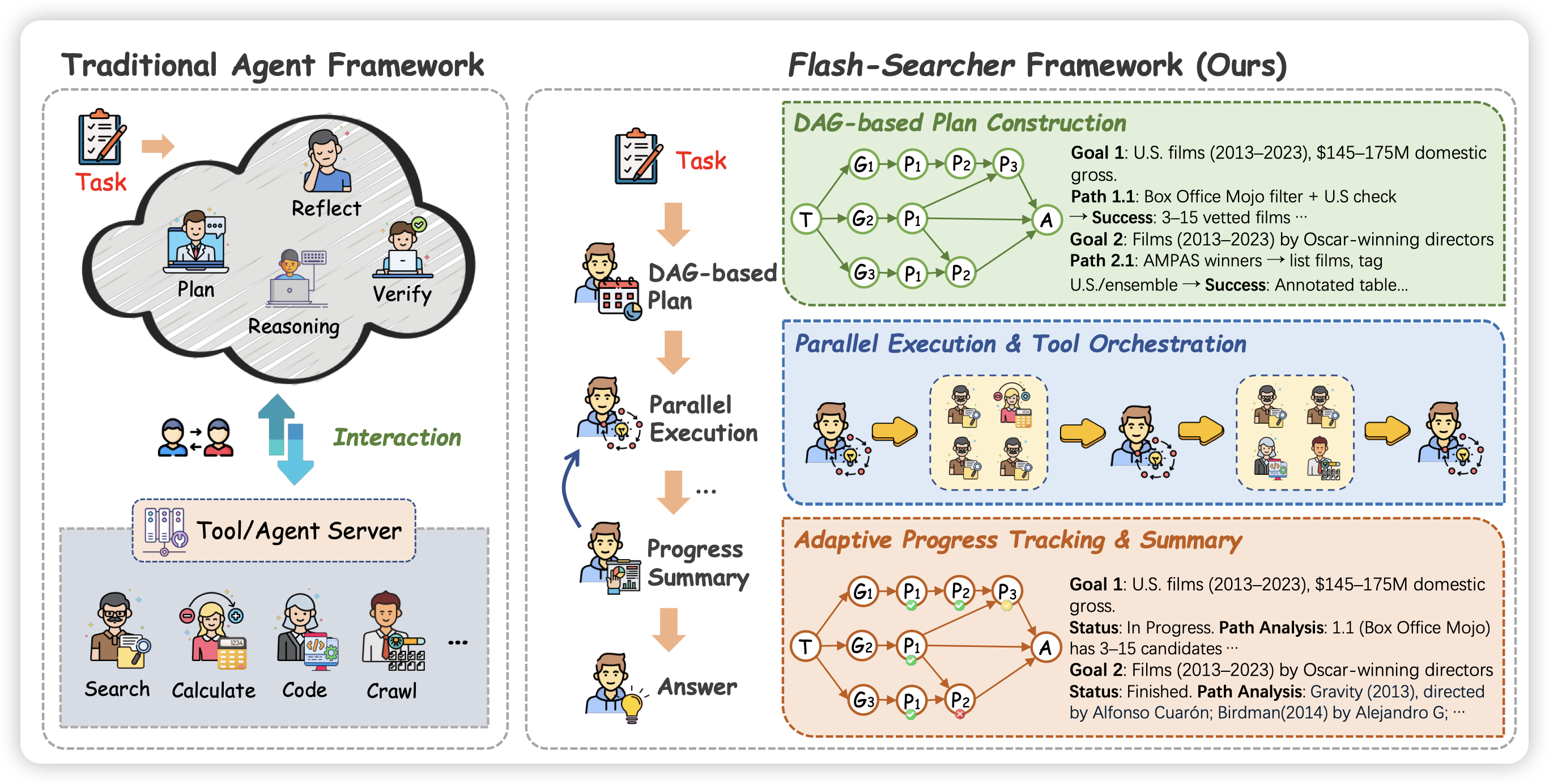
Flash-Searcher: Fast and Effective Web Agents via DAG-Based Parallel Execution
oppo的工作,之前他们做了一大堆agent评测工作,今天出了个method。作者提了一个叫做dag-parallel的概念,通过让search agent在运行时变成multi agent,区分不同role,每个人来做自己的子任务这种形式,来把browsecomp刷到了70分
agent framework加一分,native agent也得发力了
Where LLM Agents Fail and How They can Learn From Failures
这篇文章研究的问题很基础,但是我很喜欢他们的发力点。作者发现,目前世界上有很多agent benchmark,能测分数,但是不太好看出来模型为什么会失败,每次都要肉眼看数据。而且其实很多agent的错误,都是早期的某个小的“root cause”累积出来的
作者通过看了很多traj给failure mode做了一个分类,然后做了一个新benchmark,里面包含了人工标注的各种模型的failure traj以及原因。最后作者发现,如果对policy agent给出犯错原因,而不只是对错的feedback,agent可以立即把很大程度的错误修改掉
其实如果用这种data-centric的眼光审视任何一个benchmark,都能很快刷上去。
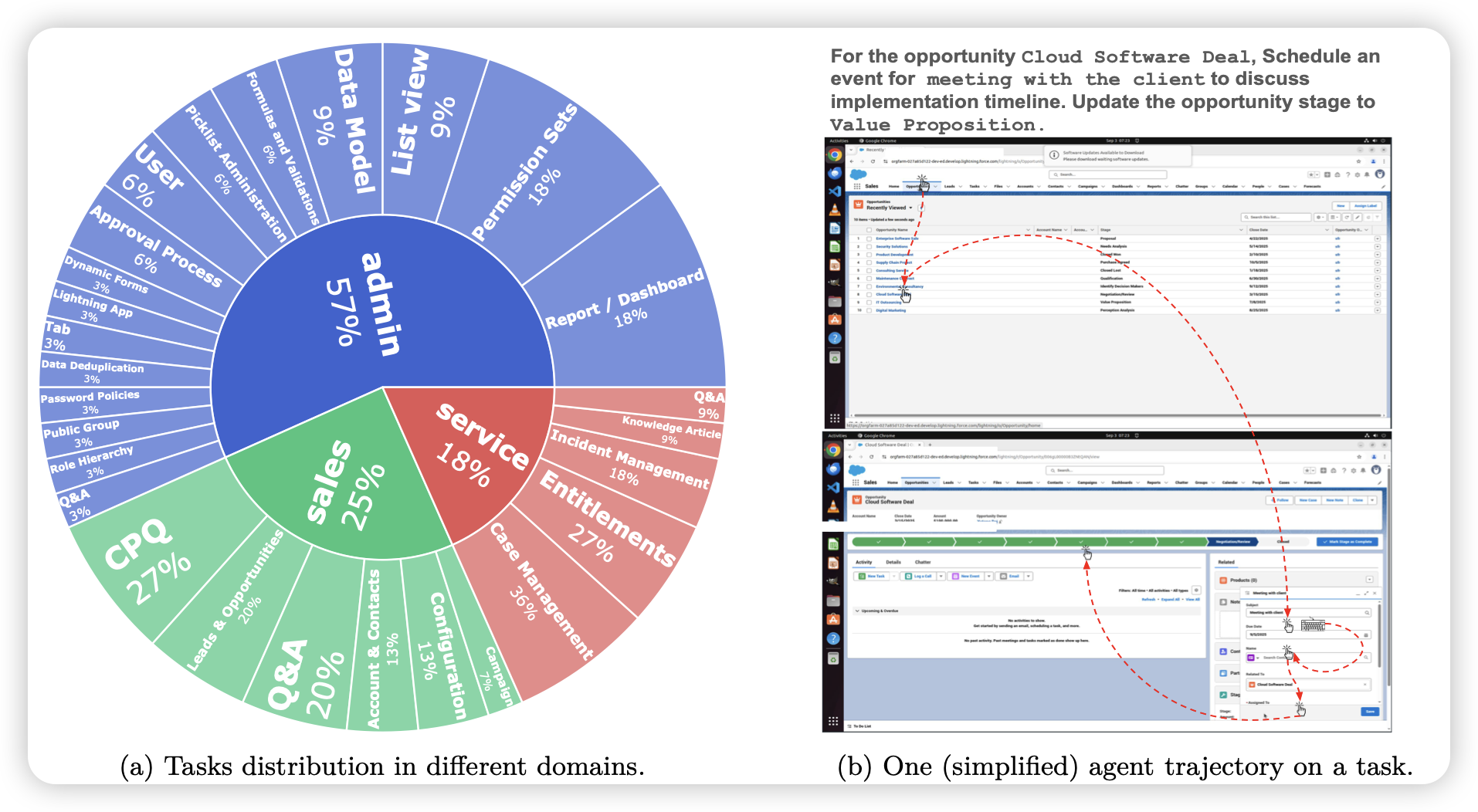
SCUBA: Salesforce Computer Use Benchmark
在OSWorld之后,其实也出了不少osworld-like benchmark:考验cua的某个方面,给了func-verifier,几百题这个规模。但今天saleforce的这篇确实算是质量高的,作者瞄准的是enterprise-task,可以func-verifier。还有个叫做demonstration-augmented setting,让模型先看人类的演示再做题(在这个情况下,一般模型水平会提升50%左右)。
这个角度有点像前几天openai的GDPval了,在benchmark上先做到最专业,再看模型能力。想要让(cu)agent做到真实世界服务,可能确实得这么干
另外现在gaia出2了,swebench出pro了…现在osworld刷到60分了,大家都期待osworld2什么时候出,结果出了个osworld-verified