Rethinking Thinking Tokens: LLMs as Improvement Operators
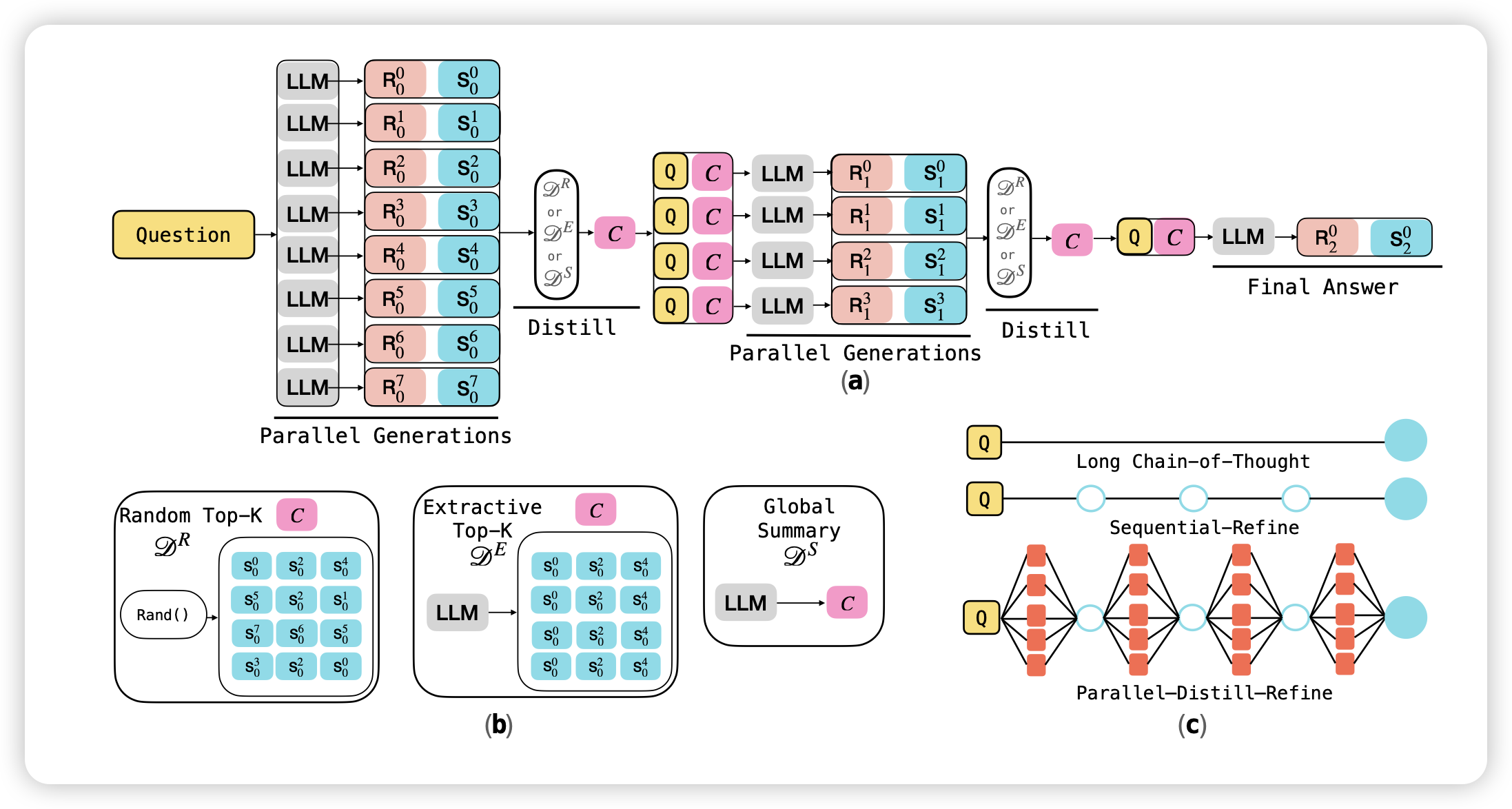
昨天讲了一篇parallel的search agent,今天meta出了一篇单轮的parallel cot工作,做的比较原生,让模型每隔一个chunk,就生成多个token,然后用某个算法(可以是类似beam search的非ai过程)抽取出推理结果,然后接着推理…用这种方案最终得到答案。用这套方案,能得到更好的token efficiency(总共生成x token时,模型的表现为y,由此画出来的折线图)
meta好像有个组一直在研究decoding algorithm,是不是他们最近转型了
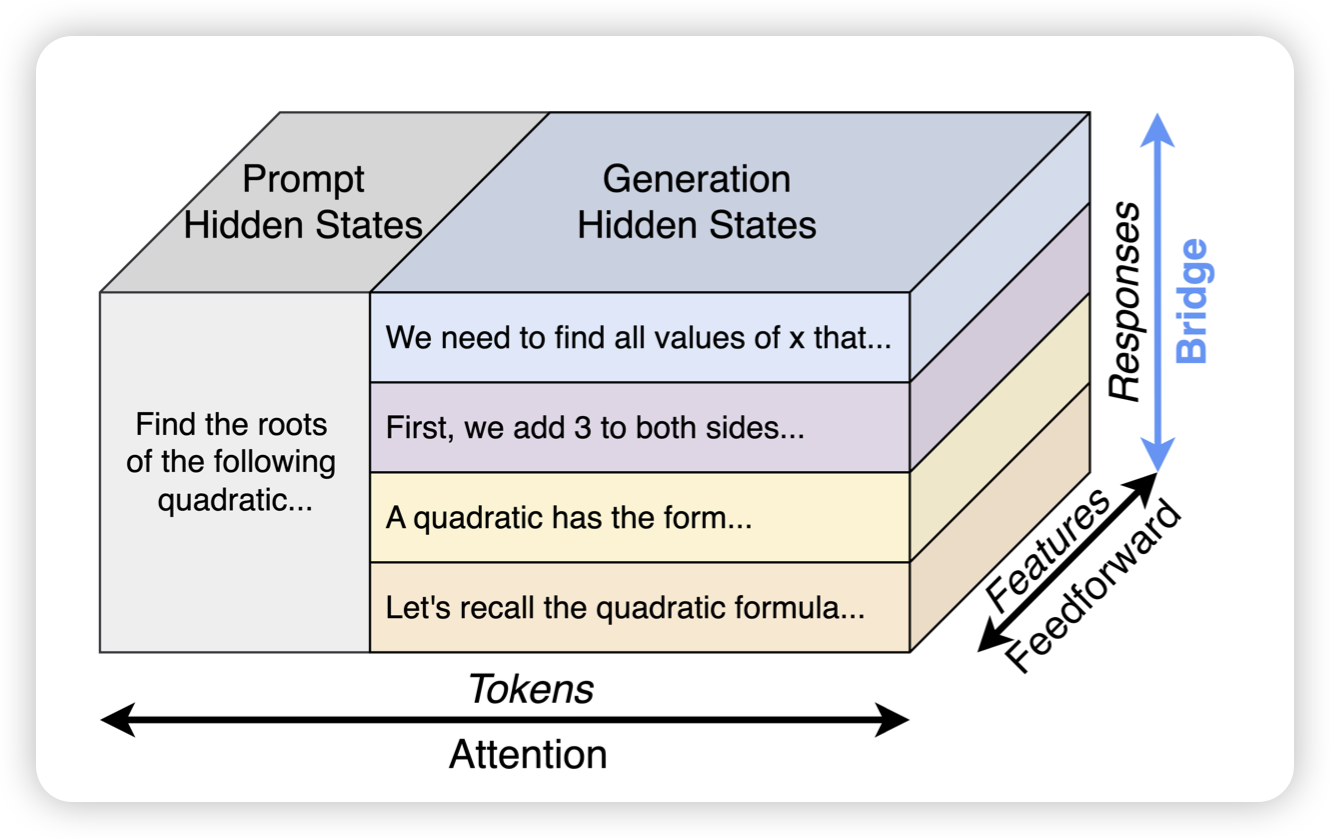
Generalized Parallel Scaling with Interdependent Generations
同样是meta,同样是parallel cot,这篇工作要更加底层。作者在想,能不能在模型层,就让模型知道自己是在进行parallel decoding,也就是说,每个回合的n路生成n个token以后,下一轮能不能直接把n个token的hidden state share一下,这样额外加一点点参数,让模型通过训练来表现更好?
这篇工作的解决思路和前面那篇就不一样,感觉是两个视角。
另外我之前推荐过google的工作:DynScaling: Efficient Verifier-free Inference Scaling via Dynamic and Integrated Sampling,这篇工作则更偏向外层一些,让模型先生成一些回答,然后拼回context再生成,最后用bandit问题的算法来挑选…感觉在parallel cot这块,现在是百花齐放,有点当年tree-of-thought的感觉