
最近连续刷到几篇在预训练阶段,改变训练模式,通过thought augment,或者干脆直接就做on-policy rl的工作。这些新的方法,和从2020年开始大家就在做的paraphrase/synthetic有本质区别吗?是比pretrain模式更好的模式吗?当然,这几篇工作在算力等级上存在明显的差距,所以没法直接对比。而且这种级别的设计差异其实也是没法对比的,变量太多,大家一般只能选一种。今天我们只是来浅浅了解一下几种工作都是如何开展的吧
参考文献:
Motivation, and the Strong Baseline
语言是人类智慧的结晶,高质量的语料往往简洁而充满智慧。LLM的训练方式是直接预测整个语料,并行地去“看到前文,预测下一个token”。这会带来两个问题:
- 预训练语料是无状态、无目的、任意口吻的。但大家在使用LLM时往往是有目的的、希望模型用比较helpful/hramless的方式说话。这里其实带来了训练测试不一致,导致从gpt1到chatgpt,花了5年才发现“rlhf”做对齐,才让模型的知识和推理能力更好地服务于真实世界。
- 已有的语料往往是人类思考的结果,而不是过程。而且在很多情况下,还会有高度的抽象。这种情况下,语料里面预测每个token的难度,实际上差距非常大,有的token简单、有的token困难。让模型硬学着去预测一些困难但有价值(valuable and hard-to-learn)的数据,模型就不得不倒向memorization,丢失了泛化性,没有利用好高质量训练数据本身的价值。显然,我们希望模型从语料中学到的不是背诵,而是领悟背后那深刻的思想。
为了解决train on raw corpus的问题,大家一般用的方法是paraphrase:找到另一个更大的模型(或者是GPT这种distiallation teacher),让它直接把语料重写成没有语病、更流畅、包含更多解释的形式,然后目标模型在重写后的语料上训练。这种方法简单好用,但很多人也会把它叫做蒸馏。是因为这个过程中,主要需要靠一个正常情况下都比自己更强的模型来重写数据,所以并不是语料变好了,而是“偷学”了强模型的知识。其直接论据是,用更小的模型重写数据做预训练,效果好像就不那么好了。据了解,某些团队pretrain的收益主要来自于强大的distillation teacher的 1T token level paraphrase。
不过最近有些新的工作,尤其是在o1领域的,发现似乎paraphrase模型太强了也不行?但这还不太solid,并且和主线关系不大,以后有机会再探讨
除了paraphrase,另一套方案叫做synthetic。这仍然要找一个teacher model来,但不是重写,而是直接从无到有地开始写文档,然后让目标模型学习。这种方法实操的难度更大,因为很容易就会让产生的数据dieversity受限、或者风格收敛,进而导致模型训练崩溃(前几年有些研究,管这个叫“疯牛病”)。预训练崩溃是一个很痛苦、很丢人的事情,所以这么干的人并不多。
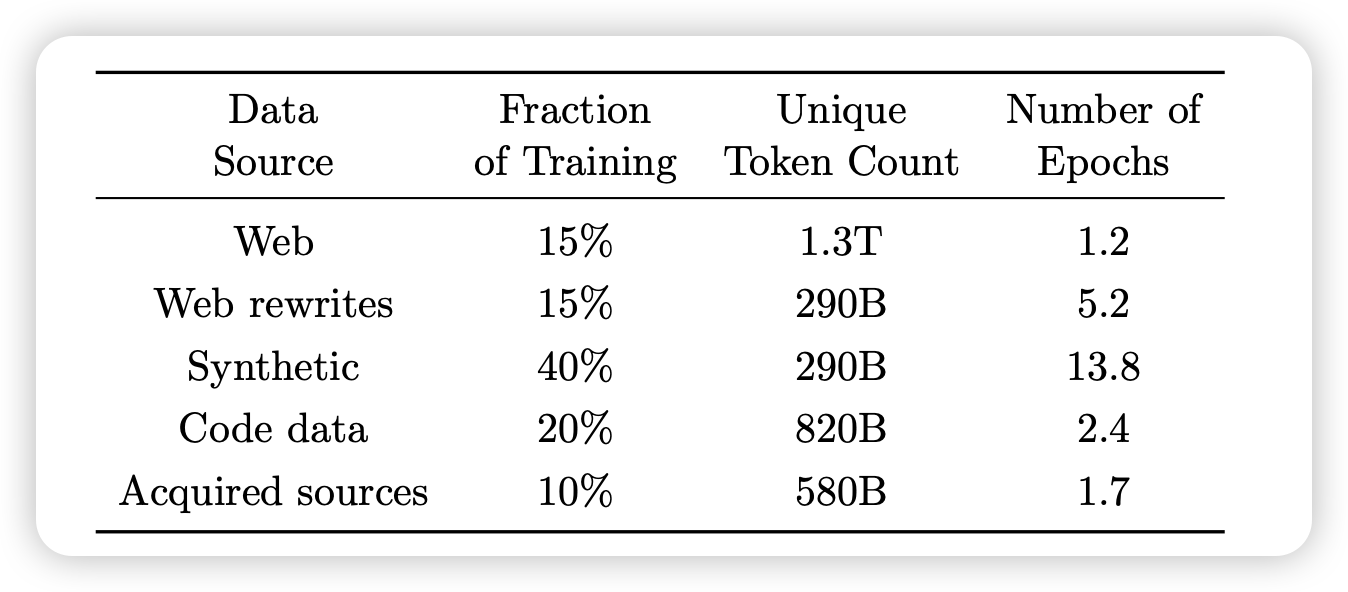
Phi系列模型,是这个领域中做的比较极端的例子:它作为一个14B的模型,却足足找 GPT4 写了300B token。而从他的recipe来看(注意每个数据源,都需要用 unique-token $\times$ epoch做计算),40%来自于合成数据,15%来自于praphrase,(20% code是保住code能力必须的东西),而原始互联网语料只剩下了15%. 从结果来说,phi-4很强,作为一个2024年底放出来的开源模型工作,现在都到2025年下半年了,同参数量的新出的模型,仍然不太敢把phi4作为baseline去对比。很多时候,一个简单的招数,在花了很多钱以后,还是很好用的。
phi4给出了做合成数据时的四个原则,我原封不动地贴在这里。知易行难,真把合成数据走好,是一个很困难的事情
-
Diversity: The data should comprehensively cover subtopics and skills within each domain. This requires curating diverse seeds from organic sources.
-
Nuance and Complexity: Effective training requires nuanced, non-trivial examples that reflect the complexity and the richness of the domain. Data must go beyond basics to include edge cases and advanced examples.
-
Accuracy: Code should execute correctly, proofs should be valid, and explanations should adhere to established knowledge, etc.
-
Chain-of-Thought: Data should encourage systematic reasoning, teaching the model various approaches to the problems in a step-by-step manner. This fosters coherent outputs for complex tasks.
当然,phi4 还做了很多别的创新,具体可以参考tech report。这里我们只说和主线相关的内容
New Paradigm?
时间来到2025年,gpt5都出来了,大家有新的招数吗?还真有,而且仅仅这一周我就看到了两个工作。第一个工作来自于亚研院。其实这个工作在6月份就有个前文(Reinforcement Pre-Training),但内容和一会要讲的另一篇类似,咱们先按下不表

这篇工作中,作者同样讲到了valuable but hard-to-learn的问题,并提出自己的想法:能不能在parapharse和synthetic中找到一个中间模式——在原始数据中,让另一个模型写一个explain放在后面,然后带着原始语料一起用crossentropy loss训?这个方法叫做thought-augment,作者举了一个很好的例子,我把它放在了文章的首图。
这个过程和paraphrase改格式目的不太一样,主要希望distillation teacher对数据添加更多的解释和推理,使得student model可以把一些有价值的、高难度的数据更好地学会。我们可以从两个不同的视角来理解这个过程:
-
蒸馏视角:对于小模型,永远无法学会复杂的语料,所以pretrain的过程中,很大一部分算力都是在浪费,并让模型退化成了memorization模式。但给了explain以后,小模型也可以开始学会了,这个过程让pretrain质变了。
-
训练效率视角:从这个视角里,我们认为模型的预训练是一直尝试在领悟数据的含义,并在scale够大后,仍然是可以把数据学会的,只是训练效率很低,可能前5T token都是在浪费。如果可以“让语料和自己双向奔赴”,那么是不是1T token就可以学得很好了呢?如果从这个视角理解,可能teacher model不需要真的比student大很多,甚至是一个更小的、或者上一代的自己也可以
“提高训练效率”并不是一个听起来没什么创新性的东西。恰恰相反,我觉得提升已有、已经work的方法的训练效率,比创新方法更重要。真实世界里,绝大多数情况下,都是在优化已有的东西。因为新东西大概率不会更好,或者仅仅在reported domain里更好
作者没有对比paraphrase baseline,而是对比了原始语料pretrain的baseline,作者用qwen 7B来给100B token语料进行thought-augment,原始语料横跨reason和knowledge两个domain。然后来训练8B model。
做了两个setting:
- scratch:从随机初始化开始训练。这里又可以进一步区分,是语料瓶颈(10epoch),还是算力瓶颈 (最终也在第一个epoch内)。实际的预训练基本都是第二种,因为通过paraphrase,你可以得到无穷无尽的、不一样的文本
- mid-train:直接找一个挺强的baseline拿过来接着训。这个主要是为了观察这种模式的收益,是否会随着模型能力增强而递减
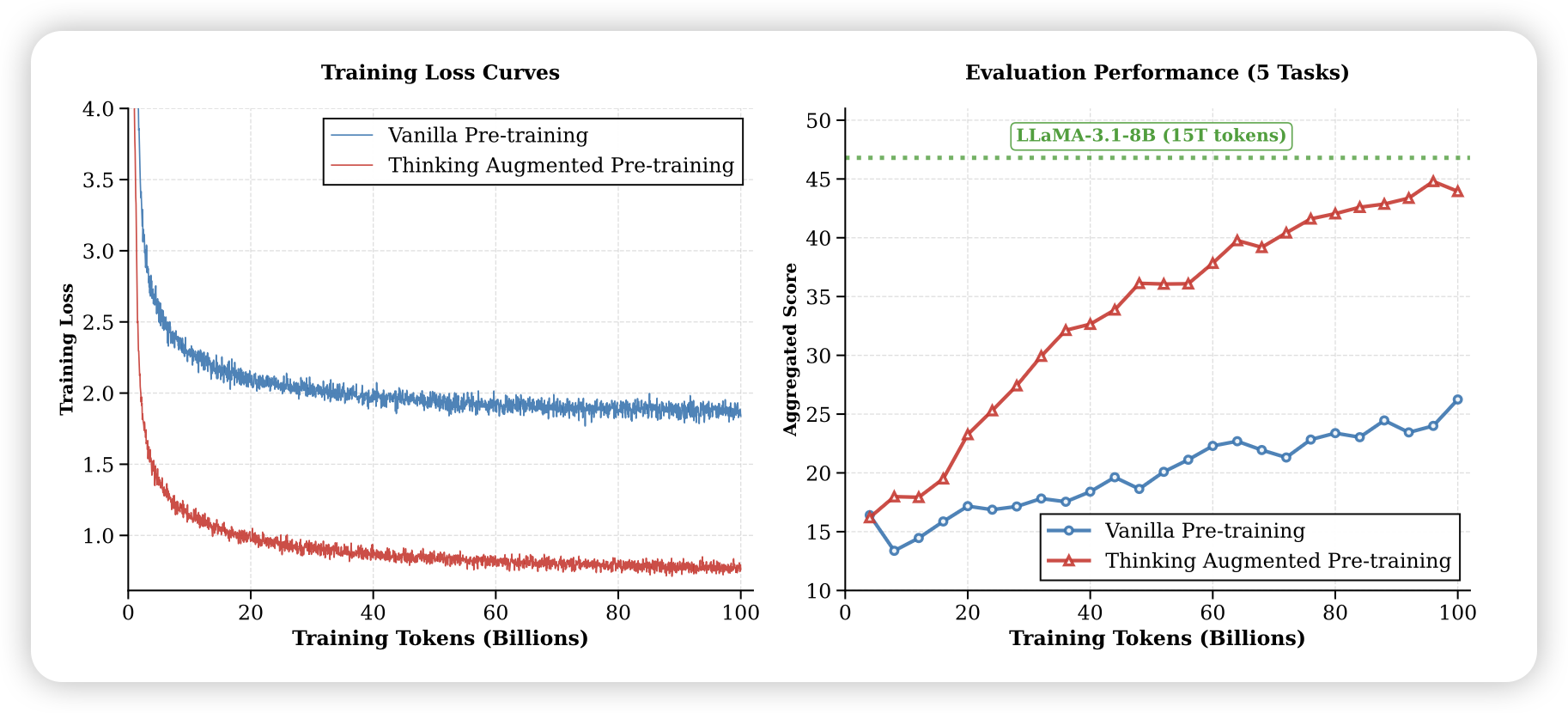
⬆️在scratch setting上可以发现,think-augment训练的loss明显更低,不过这里因为训练集同时有原始语料和explain语料,后者一般ppl都会低很多,所以不太可比。同时在下游任务上,think-augment模式的reward上升非常快,基本有两个数量级的训练效率差异。
⬇️对于midtrain setting中,收益就会相对减少,这主要是因为baseline non-training的分数就已经比较高了
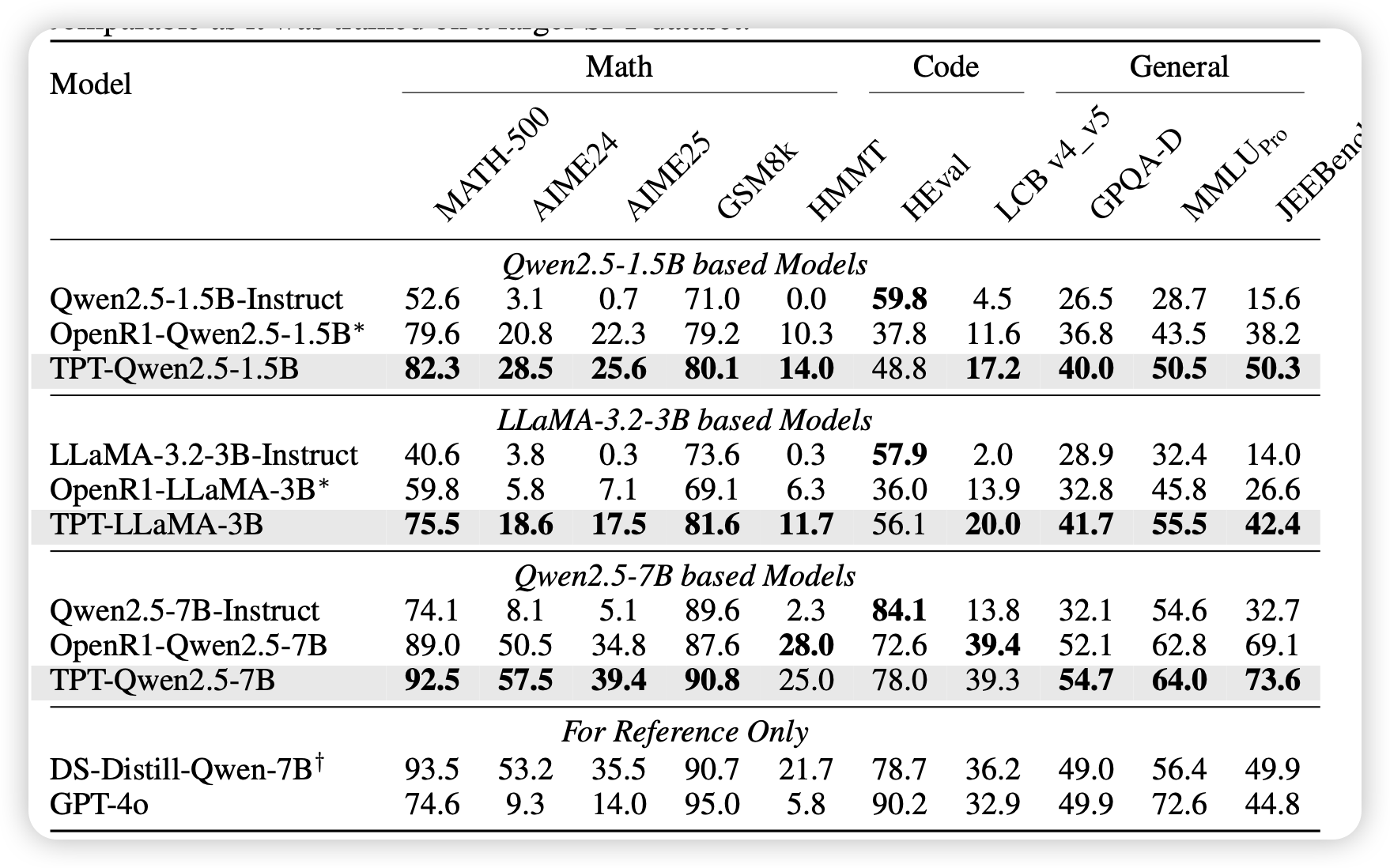
作者还发现了一些有意思的现象:作者统计了不同数据源中,think-augment部分的长度,发现在更加reason-intensive的领域上,就会更长。从另一个视角来看,这其实是通过数据的形式,对训练集的固有熵做对抗,理论上还可以在pretrain阶段,就激发模型在难的问题上多想、再简单问题上保持高效。
总体而言,这篇工作可以看作是在o1时代的paraphrase的工作,更关注reasoning、重写的方式也更优雅。但从这篇工作的实验setting来看,会存在有几个风险:
- scratch setting上,想要做出和baseline的增量收益,其实和原始数据的质量有很大关系。如果原始数据质量非常差的话,甚至baseline都不会收敛。从这里出发,其实一个更好的比较形式是paraphrase baseline,因为这样可以缓解本身pretrain数据质量带来的影响,同时本文提出的think augment模式也可以认为是一种更优雅形式的paraphase。
- 由于think-augment是用o1-style model来做的,所以这个过程中其实吃到了很多test-time scaling的红利。但从math这些reasoning-intensive的benchmark来看,testtime红利本身就有很大的收益,没法消融这个收益是来源于 1)ready-to-learn的数据,还是 2) 蒸馏了更多的o1-style数据
值得一提的是,think-augment模式虽然效果更好,也更贵。作者用了20k A100-hour,才做完qwen7B的100B token的重写。如果用工业级pretrain的10T token,70B /gpt-api teacher 来估算,这花费就是天文数字了。如果把training-token固定的比较方法,改成money-budget固定的比较方法(raw-pretrain得以训练更多token),可能结果又有不同。
更激进的尝试
我们重新思考一下刚才think augment的想法,就会发现它类似于actre,有一个无法避免的问题:我们希望模型解释语料里面的事实和题目结果,来展现思考过程。但这会引入无法避免的幻觉——distillation teacher由于提前看到了结果,所以永远可以做强行推理得出结论,但我们又很难以揭穿这种幻觉(因为这大概率需要花更多钱、用一个更强的distillation teacher)。
从另外一个角度来想:既然think augment目的是得出语料背后的原始推理过程,那我不如把顺序颠倒,换成一个更像 star/rft 风格的框架:
- 让模型看到前文,看不到后文
- 生成thought,得出一个结论
- 和真正的后文做对比,筛出来结果一致的样本
这就是接下来腾讯这篇工作的主要想法。作者甚至更进一步,不是离线地这样筛数据,而是用on-policy的grpo来过数据
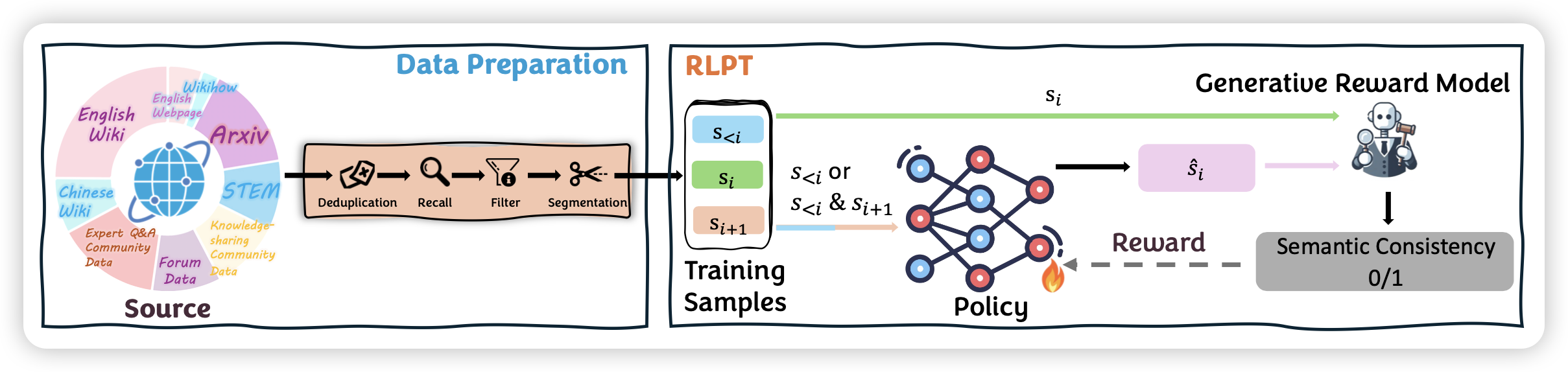
当然,虽然作者把这个工作叫做rl pretrain,声称是一个有潜力做到pretrain级别的事情,但作者其实开展的setting很小。想法激进,实验也就相对更初步。
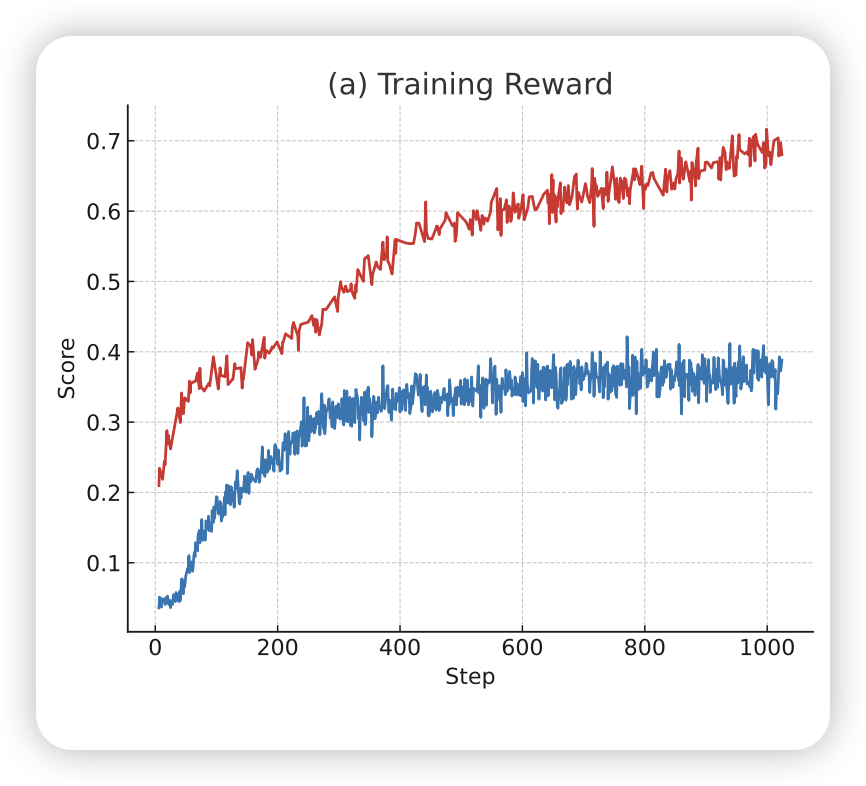
实验部分比较亮点的地方是,作者在对比下游任务时,不仅观察了pass@1,还观察了pass@8。这其实是更关注这个"rl pretrain"过程对模型entropy/diversity的影响。作为对比的是,传统的close-domain rl,一般最后不是以entropy飞掉结束,就是以entropy掉没结束。对应的pass@8上升趋势远远不及pass@1。理论上这种open-domain的训练,是会对于模型提高/保住diversity有帮助的
对于这个o1-style RL对于pass@n上限的影响,其实最近也有一些很棒的工作。未来如果有时间的话,我也可以分享给大家
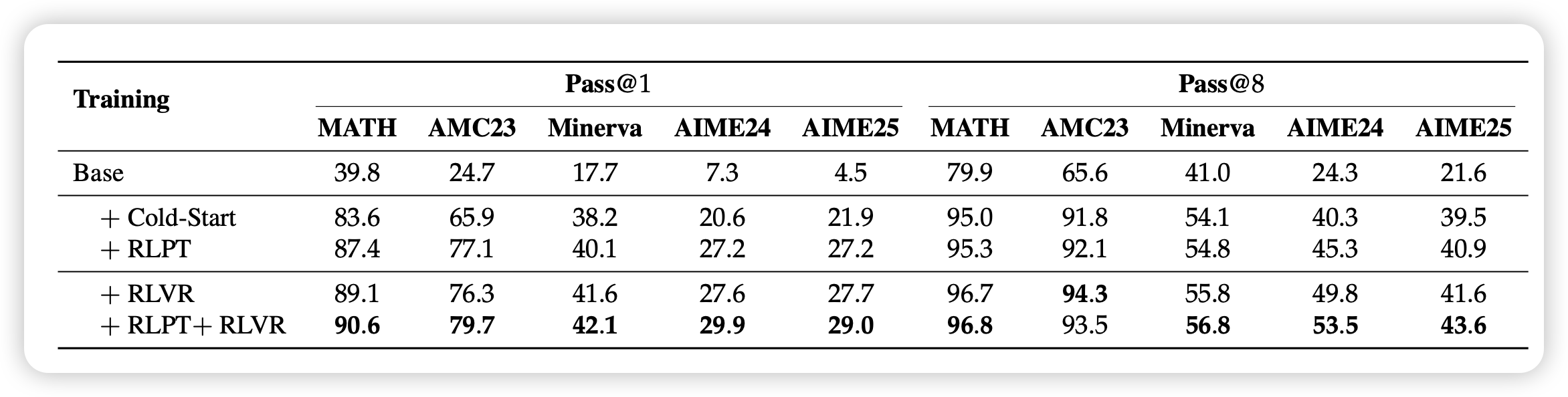
想要真的把这个模式做到pretrain-level,而不是qa-level,就要克服一个真实世界的挑战:如何定义“相等”?对于数学题或者一些知识问答,我可以认为答案正确就think正确,这个假阴假阳率不会高。但如果是开放世界语料,比如story,或者twitter chat sequence,什么叫一致呢?作者在这里用generative reward model,让模型来判断是否一致。但其实作者并没有关于grm本身准确率、以及rm准确率对于训练结果影响的分析,这是我比较关心的问题
我的思考
我们不妨分析一下这两篇工作。把think-augment的方式反过来,变成rl-pretrain,什么是必要的组件?假如真的去做工业级的pretrain,算法效果要给训练稳定性和效率让步,那么这种模式引入了什么开销和不稳定性呢?
- 一个专门的模块来判断think和语料的一致性?从Phi-4的原则看,这是必要的,但其实我们确实不知道,如果本身有比较强的不一致时,这类方法是否还有正收益。判断模块会带来额外的计算开销,而且会筛掉一部分数据,让总体的算力空转更明显。
- on-policy?腾讯这篇工作主要区别是,永远用比较“近”的参数更新模型。从结果上来,接受率的上升是比较明显的。这对应着筛掉数据的比例在快速下降。然而,on-policy rollout的问题是,rollout系统会带来训练利用率下降和训练稳定性下降,而如果我是离线地把整个数据集infer一遍,相对就会利用率更高
现在大家常常在说“pretrain-level RL”,是指在RL阶段投入和预训练同样多的算力,开展pretrain + rl两阶段对等算力的训练。概念听上去很酷,但实际的开展目标是“万卡集群跑单次close-domain RL”。这几篇工作给出了另一个理解这个问题的视角:能不能反过来把pretrain做得就更像rl,甚至干脆就是RL呢?
如果从这个维度讨论,其实还有一些工作是可以参与进来的:
- Open-domain RL:最近有些工作试图从pretrain dataset中挖掘一些更diverse的rl数据。这个过程本质上是把预训练数据冲构成一个“easy to verify”的形式。这样想,就和腾讯这个工作有点像了。这个领域,从o1出来之前,就有人在传统instruction following搞了,最近又迭代到了o1 setting上
- Importance Sampling on SFT:最近有些工作仍然使用single-forward, single-backward的方式过数。但setting基础,loss就不基础。会把迭代方式做出一个old_policy,让模型优先去学习自己需要的东西。代价是一部分token的梯度被clip掉,没了
我认为,可以下一个可以影响世界的、和GPT1一样伟大的学术工作,今年已经诞生了。它很可能是一种SFT/RL耦合的模式,先在语料上做一个pretrain(从RL的话说也可以叫cold-start),然后让模型自由gen + verify,进行一个比较open-domain训练。对我们来说最重要的是:我该怎么发现它,并在2025年就认知到他是对的?🤔