国庆要来了,大家猛挂一波论文出去玩,周一都卷到500篇了…周二岂不是得1000篇
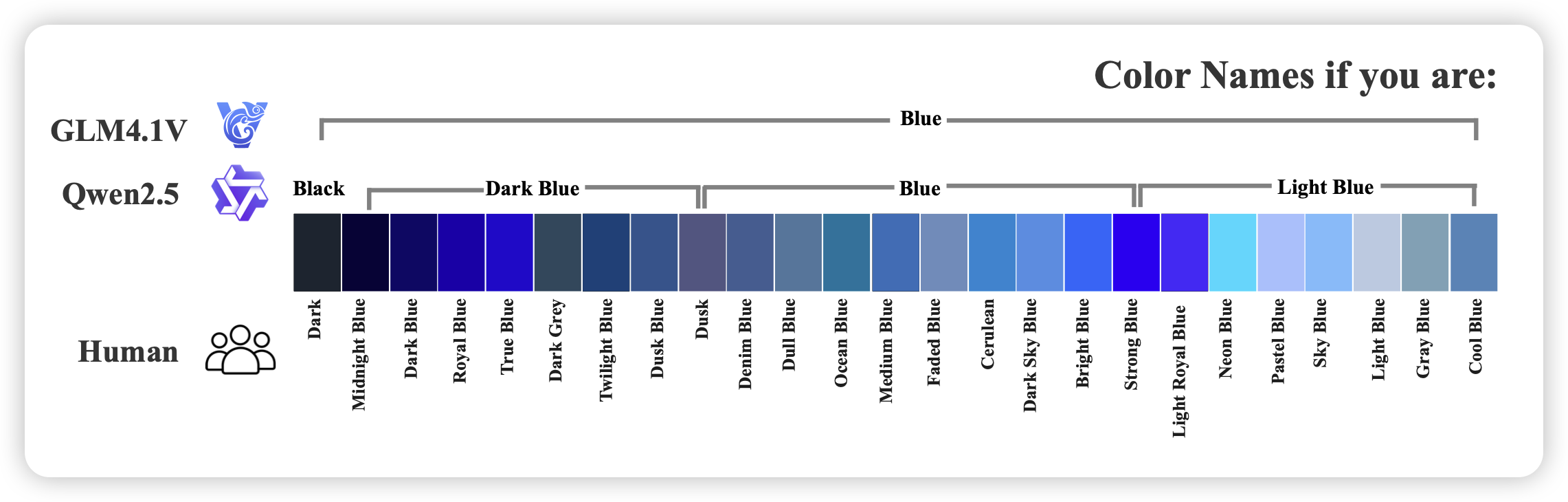
Color Names in Vision-Language Models
这篇工作评测了VLM看图片说颜色能力
我主要想share下这个首图…我感觉我就是qwen2.5。下次再来个视频生成版,找veo3生成一下Dusk看看是什么颜色
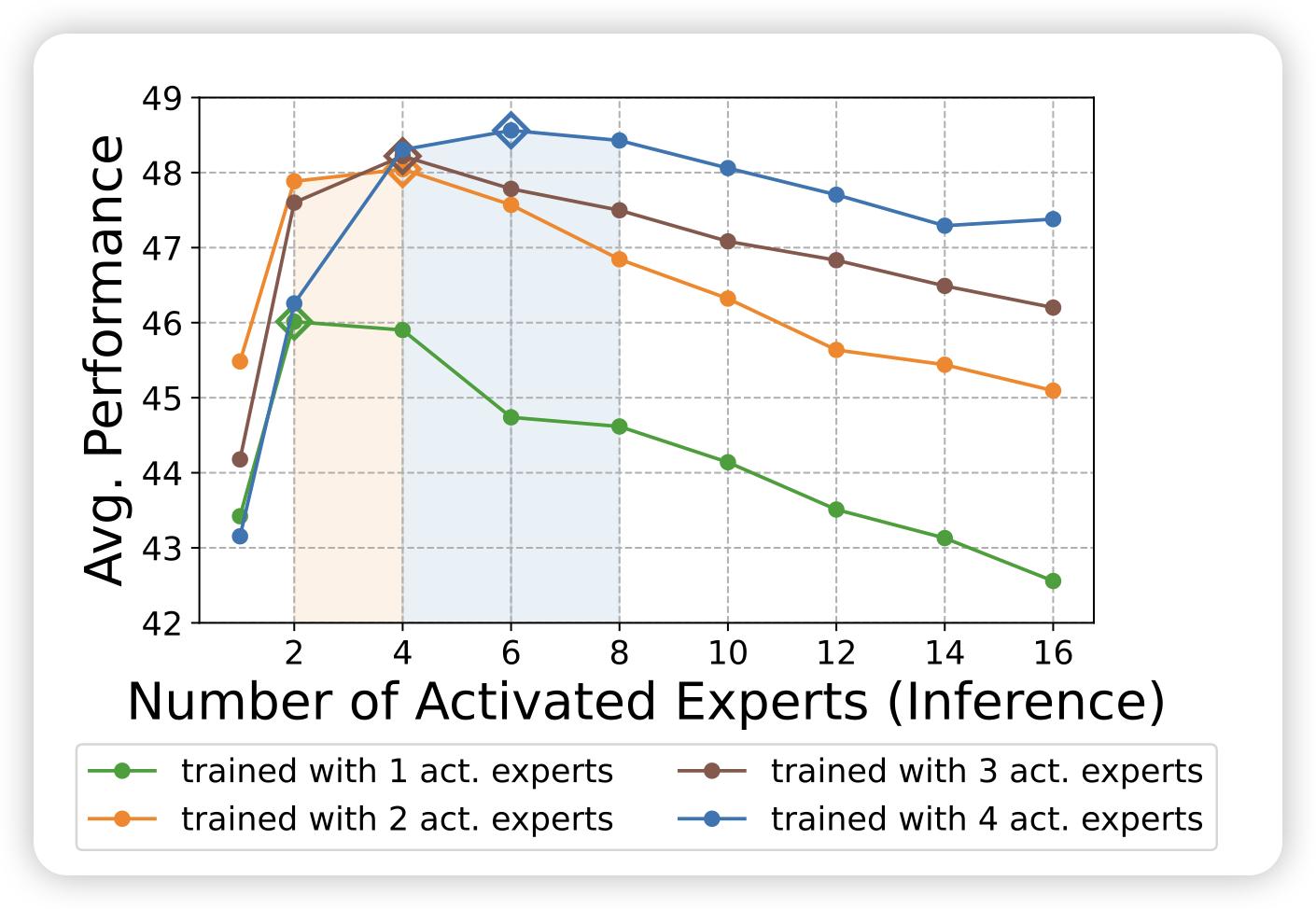
Elastic MoE: Unlocking the Inference-Time Scalability of Mixture-of-Experts
众所周知,moe模型现在一般就是16个专家平均激活一个的比例,那么有人就会问:如果我激活更多,甚至dynamic地激活更多,会不会表现更好呢?其实之前早有人研究过这个问题,叫做dynamic computation require,但是大模型时代倒是没有见到了,我之前推荐过一篇 2024-03-13-insight 用topp而不是topk激活MoE的论文,而今天这篇工作尝试了一个训练的方案:每次去topK,从中随机取k个,让模型训练时就适应激活多种不同数量专家的模式。
不过现在大家没有这么做,我感觉主要是推理时的资源考虑?激活1-k个专家,资源需求量等于稳定激活k个专家