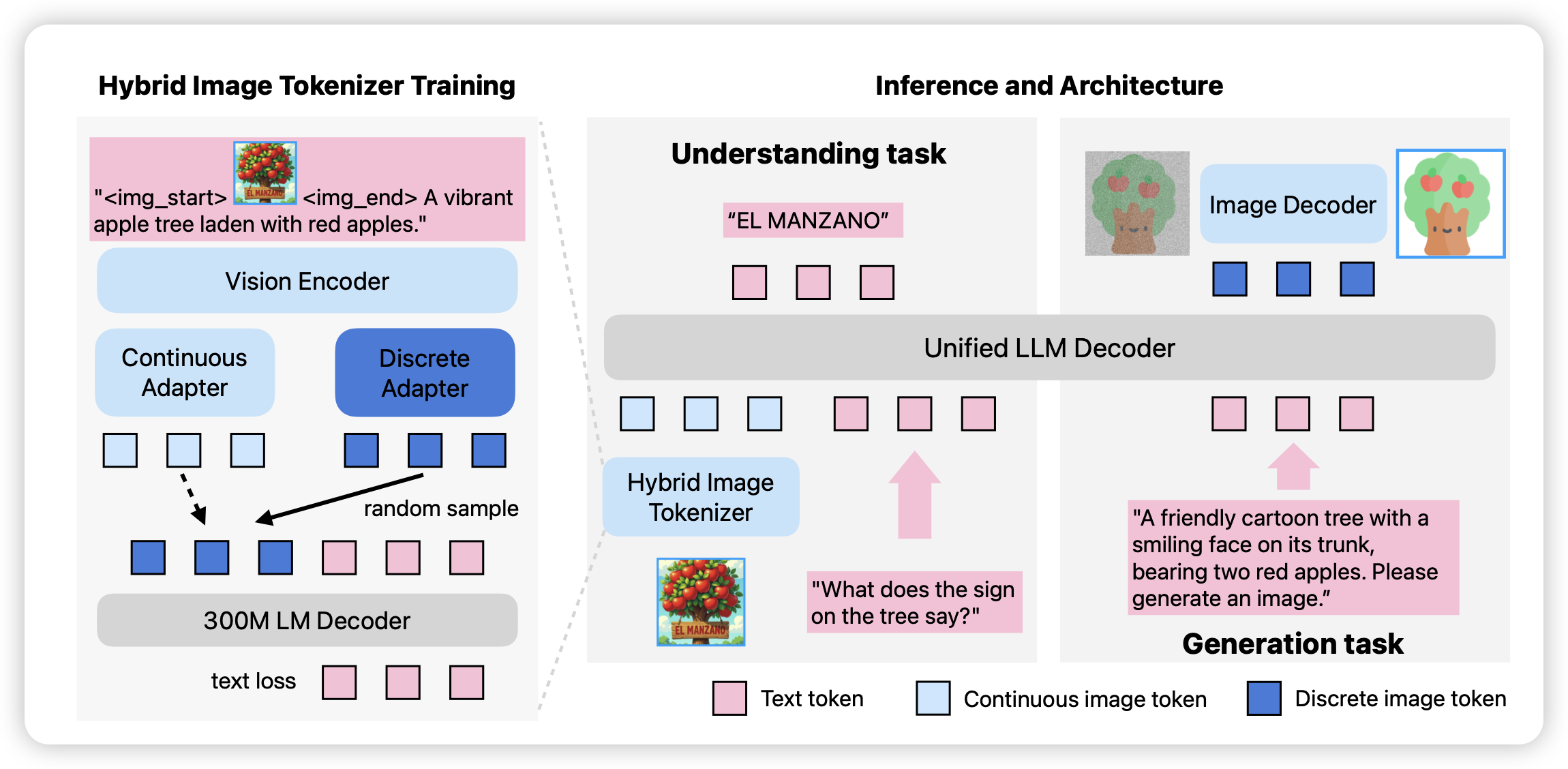
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
apple出的一篇生成理解统一方向的动作,作者认为一个图片天然应该有离散和连续两种类型的embedding,前者用于生成,后者用于理解。所以作者让同一个vision encoder直接就生成两种embedding,并做了对应的encoder pretrain和后续的生成理解统一训练
bagel现在是这个方向的很好的baseline,但似乎大家都在做模型结构方面的探索,不知道数据和结构到底谁更重要些