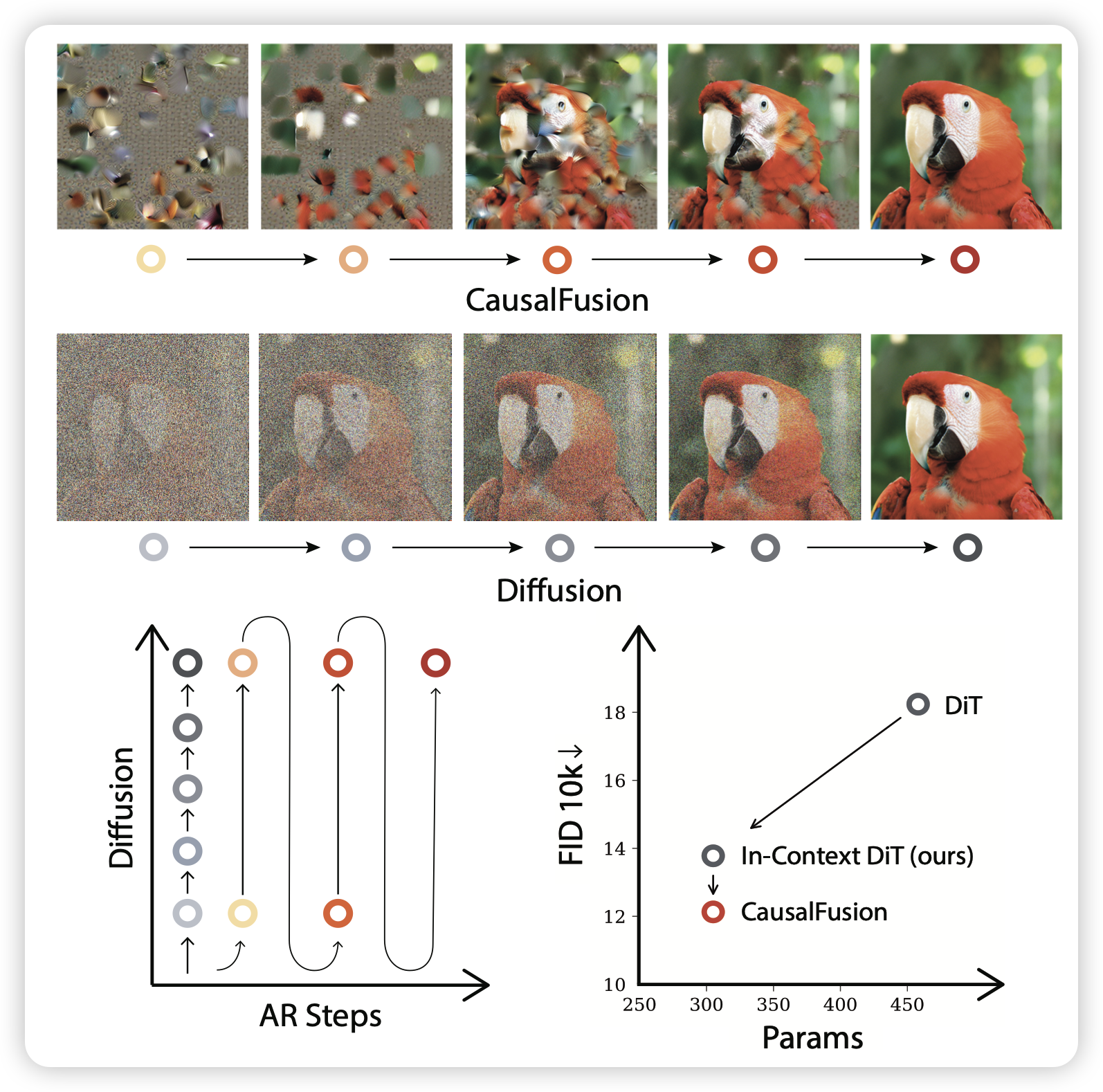
Causal Diffusion Transformers for Generative Modeling
字节的工作,作者发现,之前的ar生图基本都是把diffusion loss引进来,但是能不能像diffusion一样,让ar模型先生成模糊的图片,再慢慢生成清晰版本的呢?
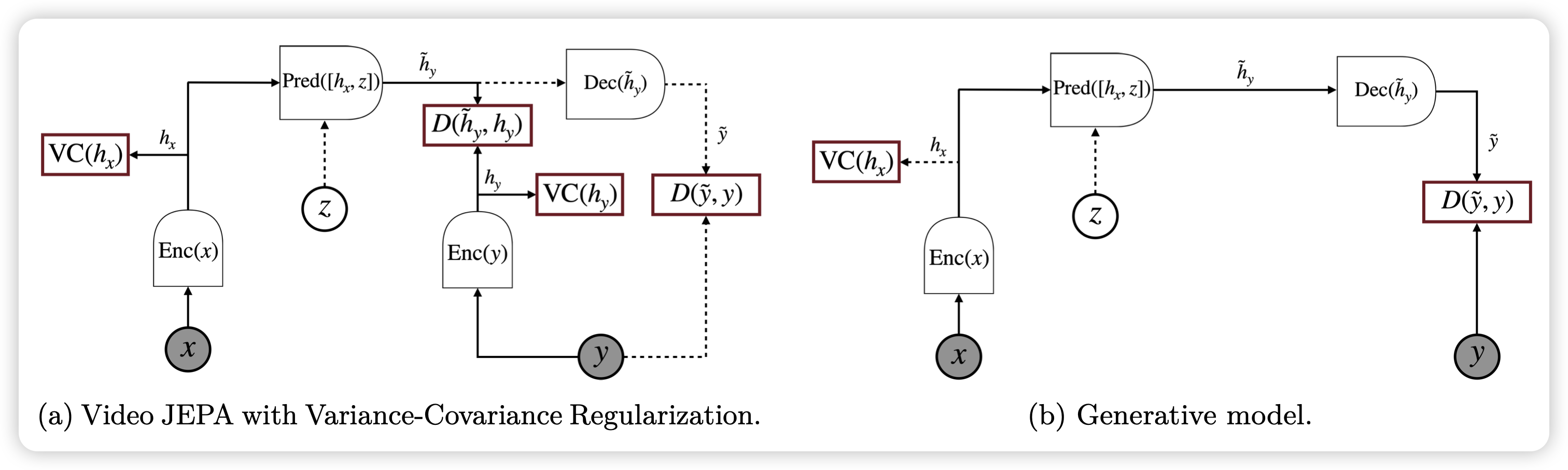
Video Representation Learning with Joint-Embedding Pre- dictive Architectures
Lecun又带着他的世界模型回来了。这次是视频理解,之前好像出过图片理解的版本。
感觉谁在这个基础上搞个VLM,发现真比ViT-based好,大家就全切过来用了
SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language Models
黄老师的工作,之前有个方向是让模型做self-refine,自己该自己的错,下次生成得更好。如果让self-refine的过程组织成一棵树,每次refine好多次,每个refine又可以再refine好多次……最后是不是就能生成出来dpo数据了呢?作者试了一下这个方案生成的dpo训练,发现比正常的dpo数据效果更好。
ultrainteract的多轮版本?