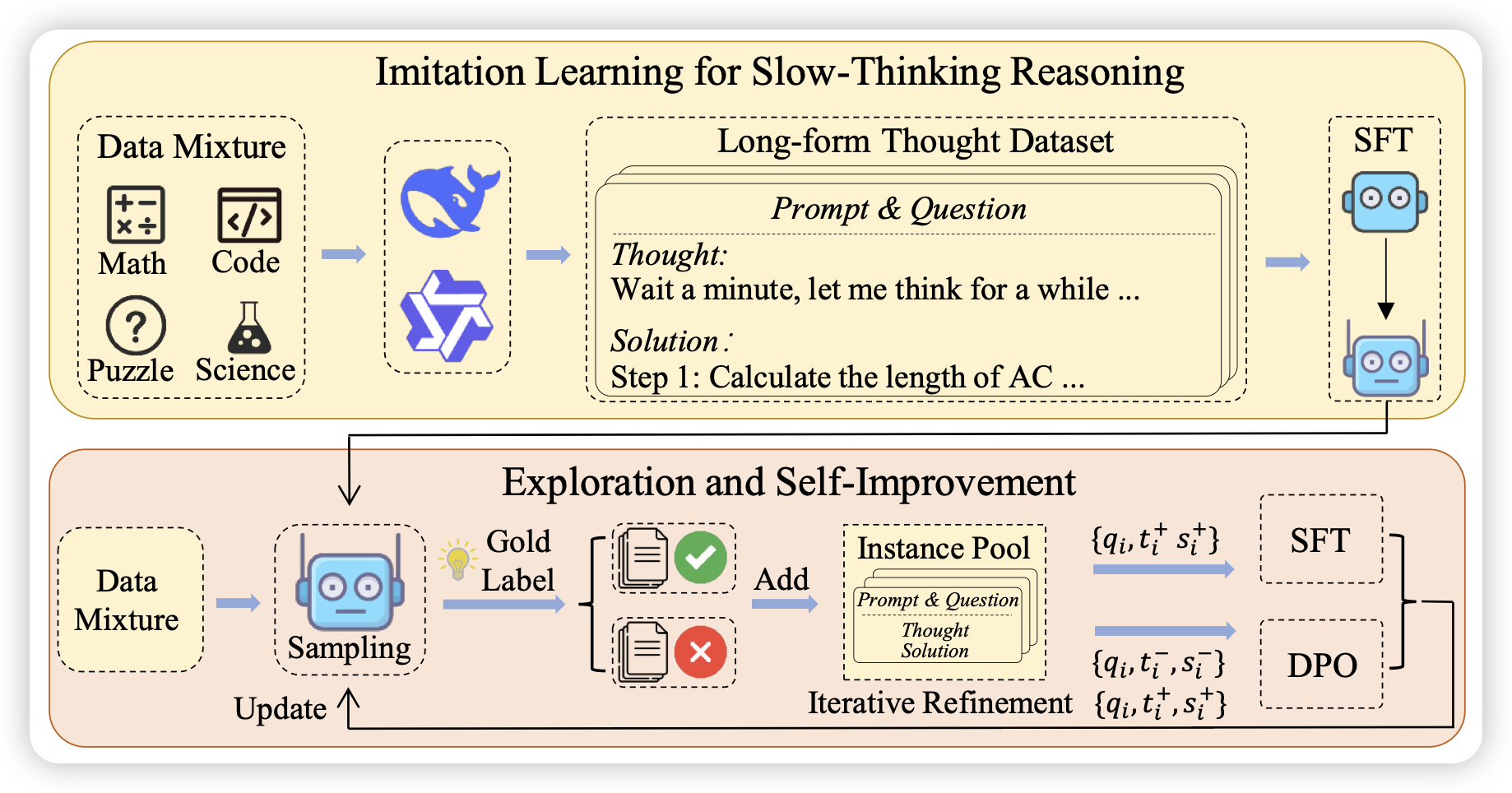
Spectral Image Tokenizer
一篇google research的工作,标得单位不是Google DeepMind。作者认为,old school的Autoregressive image generation,都需要把图片按照空间关系切成一个个小patch做tokenize,这个不符合图片的直觉。因为图片的雷达扫描顺序其实没有天然casual的性质(下一个patch依赖于前面的patch)。那我到频域上按照不同频域生成,是不是就有casual性质了?作者试了一下dwt,发现效果好不少
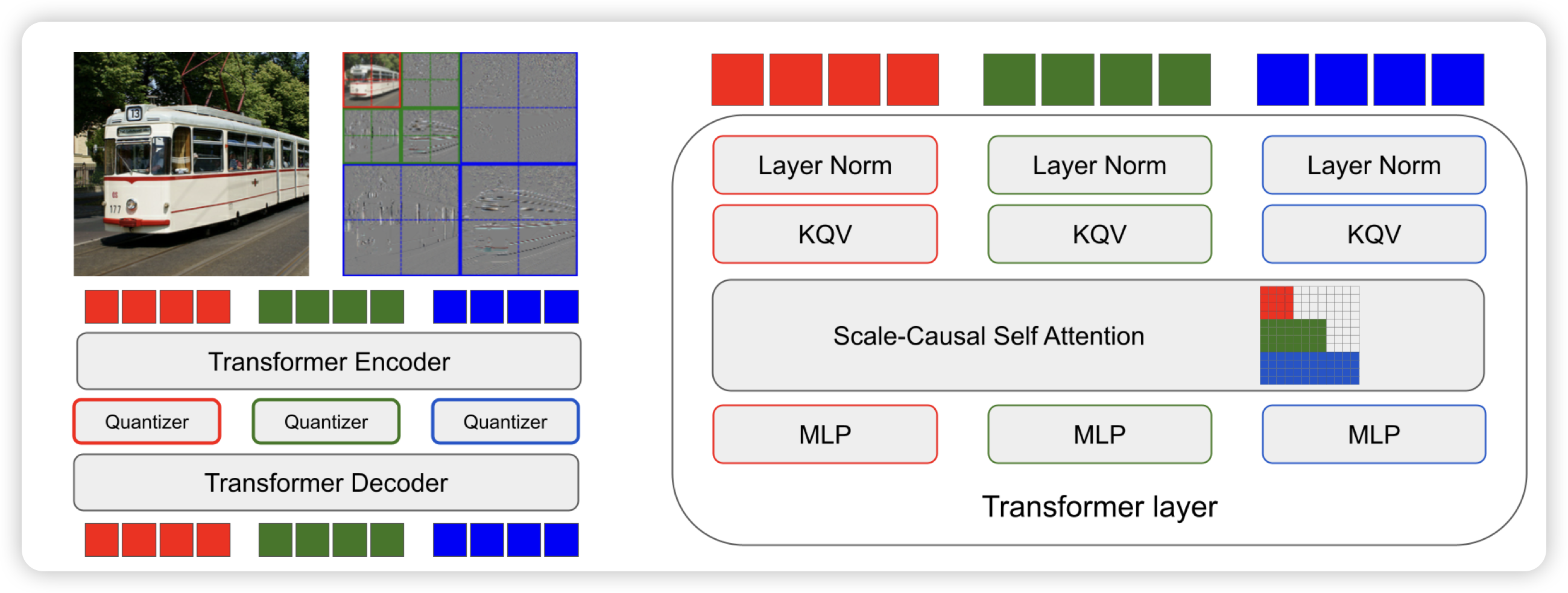
Phi-4 Technical Report
之前主打小模型的phi系列,第四代也变成14B了,果然参数少就是没前途吗。phi4研习了gpt4合成预训练数据的老路,MATH都给你刷到80分。
这次在很多任务上超过了teacher model(gpt4),说明合成数据的前途一片光明。不过这是为什么呢……
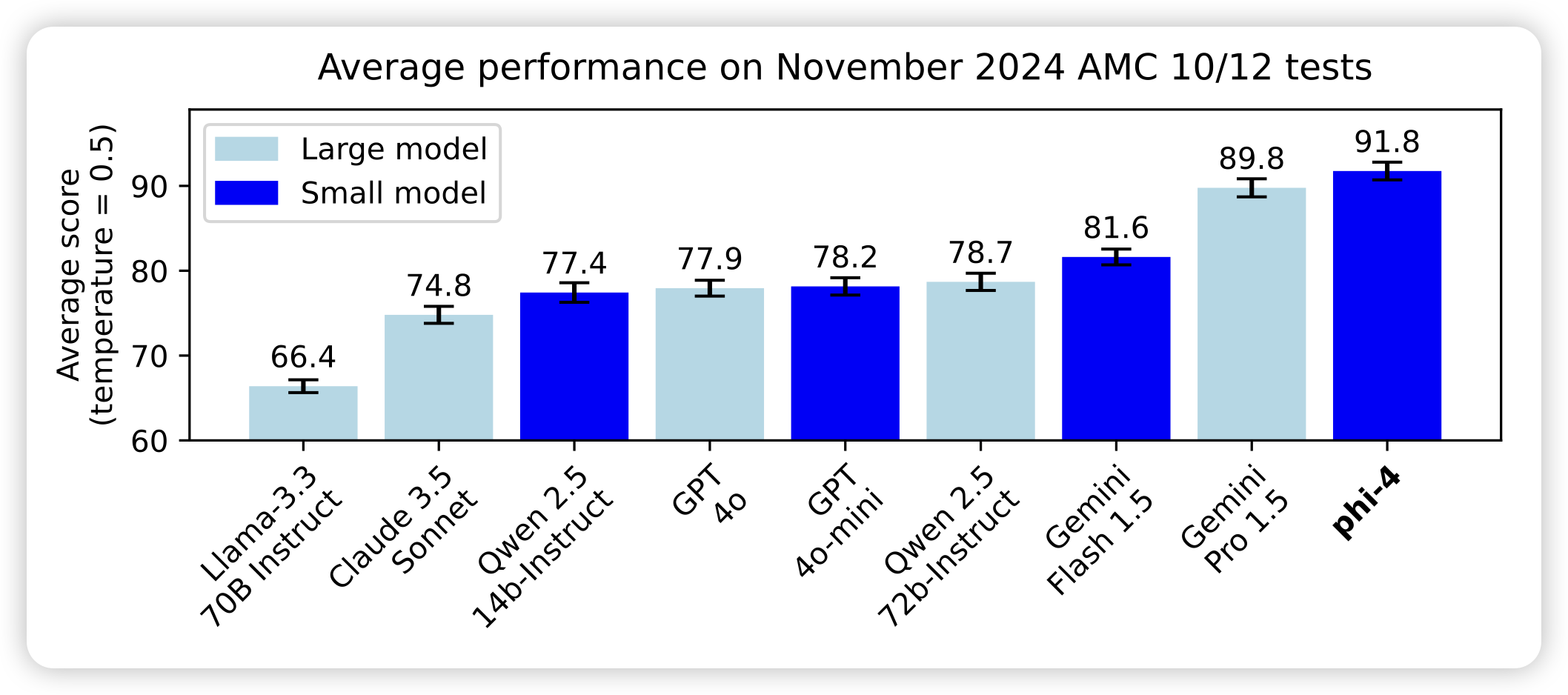
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems
BAAI出的o1-like model,方法论和STaR几乎一样:
- 找一个base model,在o1 distill数据上获得基础的推理diversity
- 然后持续地找数据集在上面"练功",生成一堆reasoning trace然后按照答案分类成正负样本
- 最后把数据训练回去,发现可以涨分
大家的探索最近聚焦在了这个形态,问题在于:除了第一步是需要o1才能蒸馏的,后面两步都是"古已有之"的思路。
那么o1蒸馏出的数据为何可以做出来第一步呢?