今天是重量级,ICLR投稿直接来了187篇
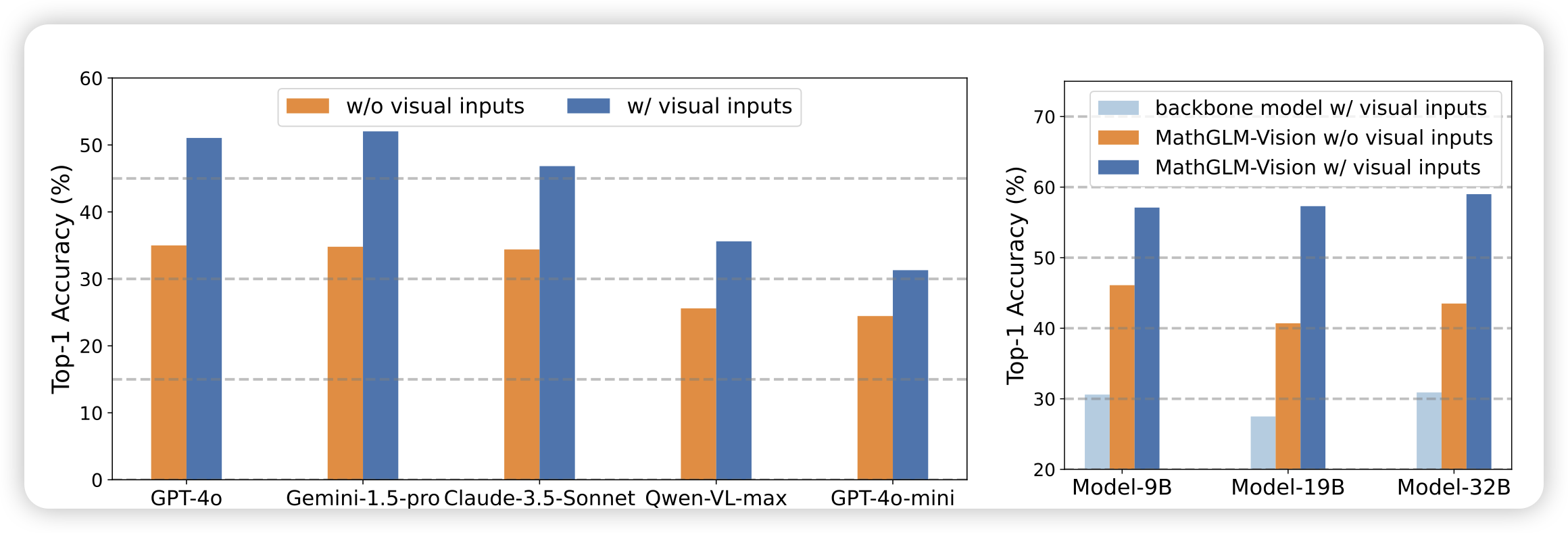
MathGLM-Vision: Solving Mathematical Problems with Multi-Modal Large Language Model
唐杰老师的工作,作者搞了个MathVL sft数据集,把mathglm的多模态数学能力提上去了
talk is cheap, show me your dataset [doge]
VisScience: An Extensive Benchmark for Evaluating K12 Educational Multi-modal Scientific Reasoning
另外唐杰老师还出了个多模态的科学问题测试集,和上面那个就放一起说了
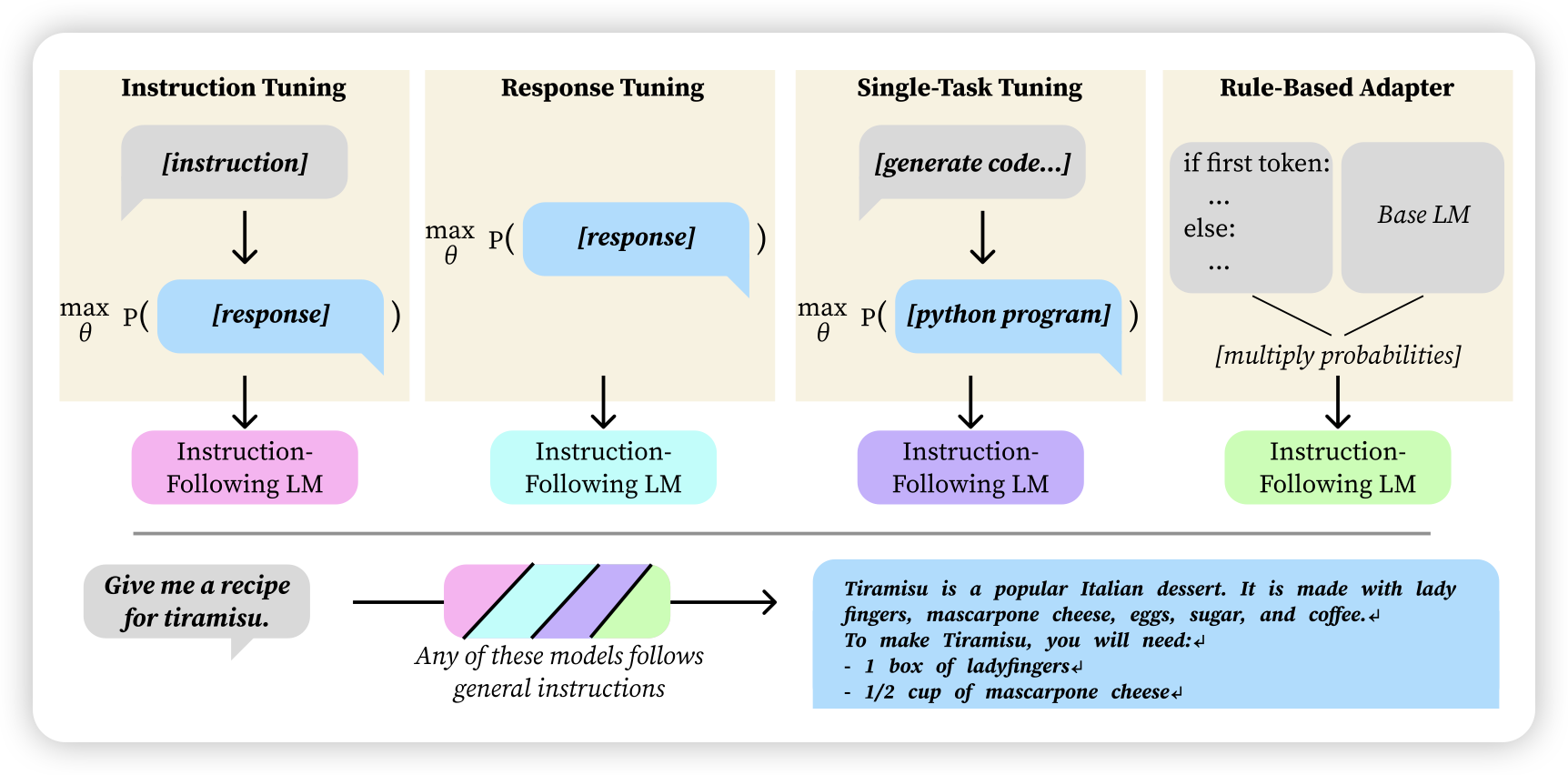
Instruction Following without Instruction Tuning
很有趣的工作,作者发现一个滑点:现在大家做instruction tuning训练,都是在(ins, response)对上训练,但这是必要的吗?作者发现,即使去掉ins,只让模型训练去直接生成response,竟然训出来的模型也有instruction following能力???甚至是,不需要在所有domain,即使只在某些domain看到一些response,也能在所有domain泛化出instruction following能力
让我想起来之前看到的inverse Instruction tuning,模型有能力只看到response去猜到query是什么。所以,假设模型能做inverse instruction tuning,那好像确实不太需要看到instruction
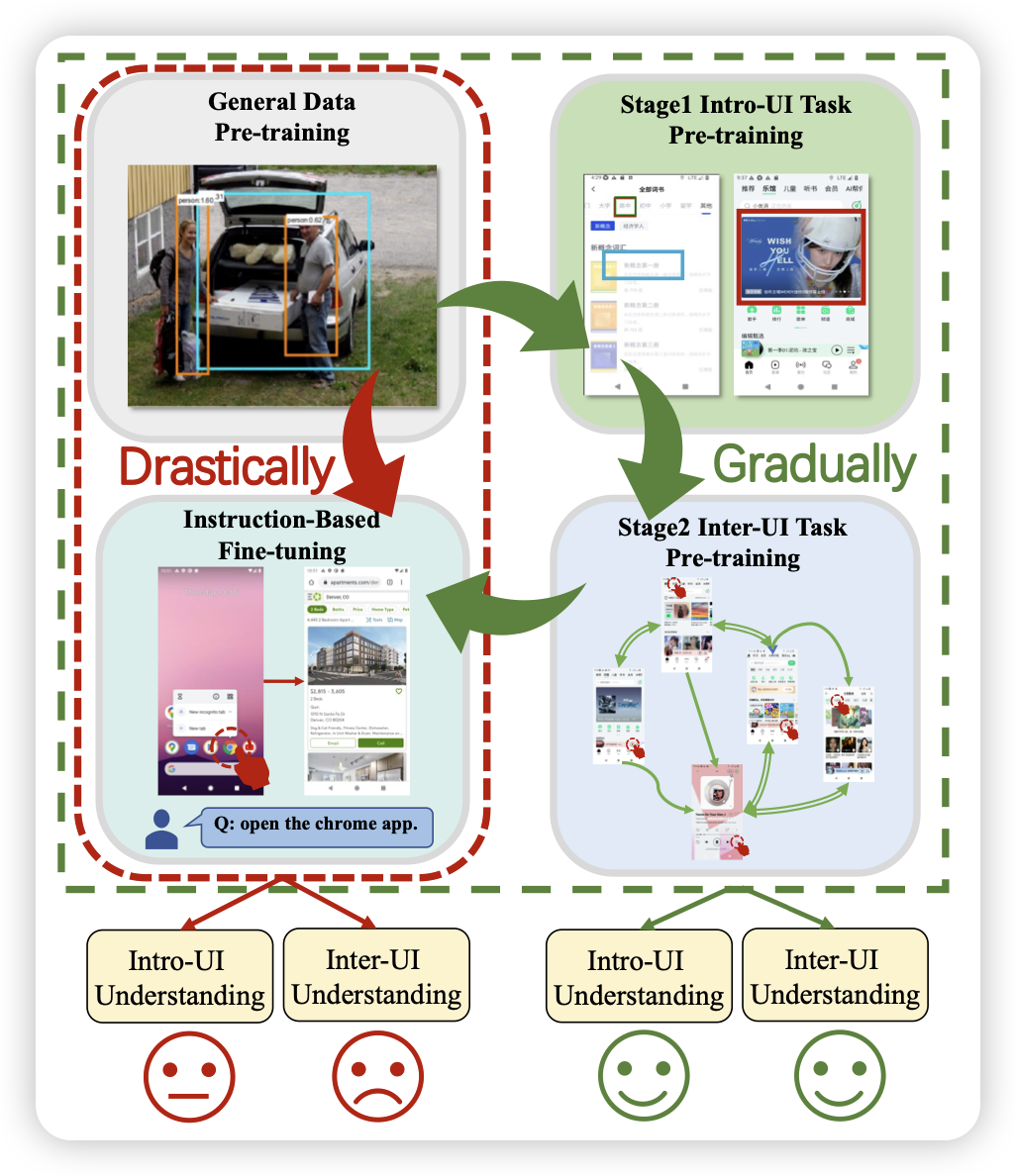
MobileVLM: A Vision-Language Model for Better Intra- and Inter-UI Understanding
小米的工作,最近挺少见的GUI
Automation相关的论文。他们几个月前出了一篇MobileBench,原来有后手在这里等着。标注了几百万张安卓手机的截屏,
从里面挖掘出了一些文本的训练信号。
除了不开源,做得都挺好的……
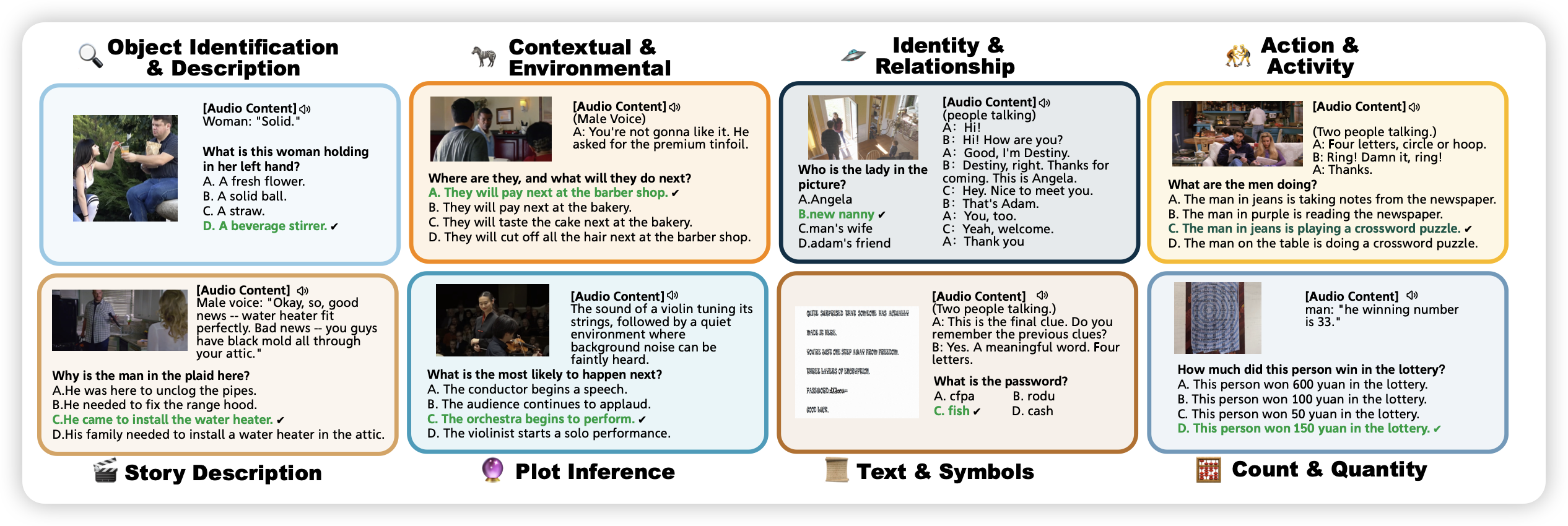
OmniBench: Towards The Future of Universal Omni-Language Models
zhangge又出手了,这次是为omni模型设计的benchmark。涵盖了图片、视频、声音、文字多个模态