前两天看论文解释了emergent ability的出现原因猜想和复现,论文主要表达”涌现“没什么复杂的。我也聊聊我的看法。
作者来自斯坦福大学

论文
其实这篇论文也没什么所谓的方法,都是基于一个假设。
我们之前也聊过emergent ability的博客: 大模型的Emergent-Abilities和最优传输。里面说到其实crossentropy loss是随着模型(指数)大小线性下降,符合power-law的。
作者就从这里出发,提到:我们现在的主流测试函数和loss不是线性关系,具体而言,主流有几种测试score: \[ \text{Multiple Choice Grade} \overset{\text{def}}{=} \left\{ \begin{aligned} & 1, \text{if highest probability mass on correct option} \\ & 0, \text{otherwise} \end{aligned} \right. \]
\[ \text{Exact String Match} \overset{\text{def}}{=} \left\{ \begin{aligned} & 1, \text{if output string exactly matches target string} \\ & 0, \text{otherwise} \end{aligned} \right. \]
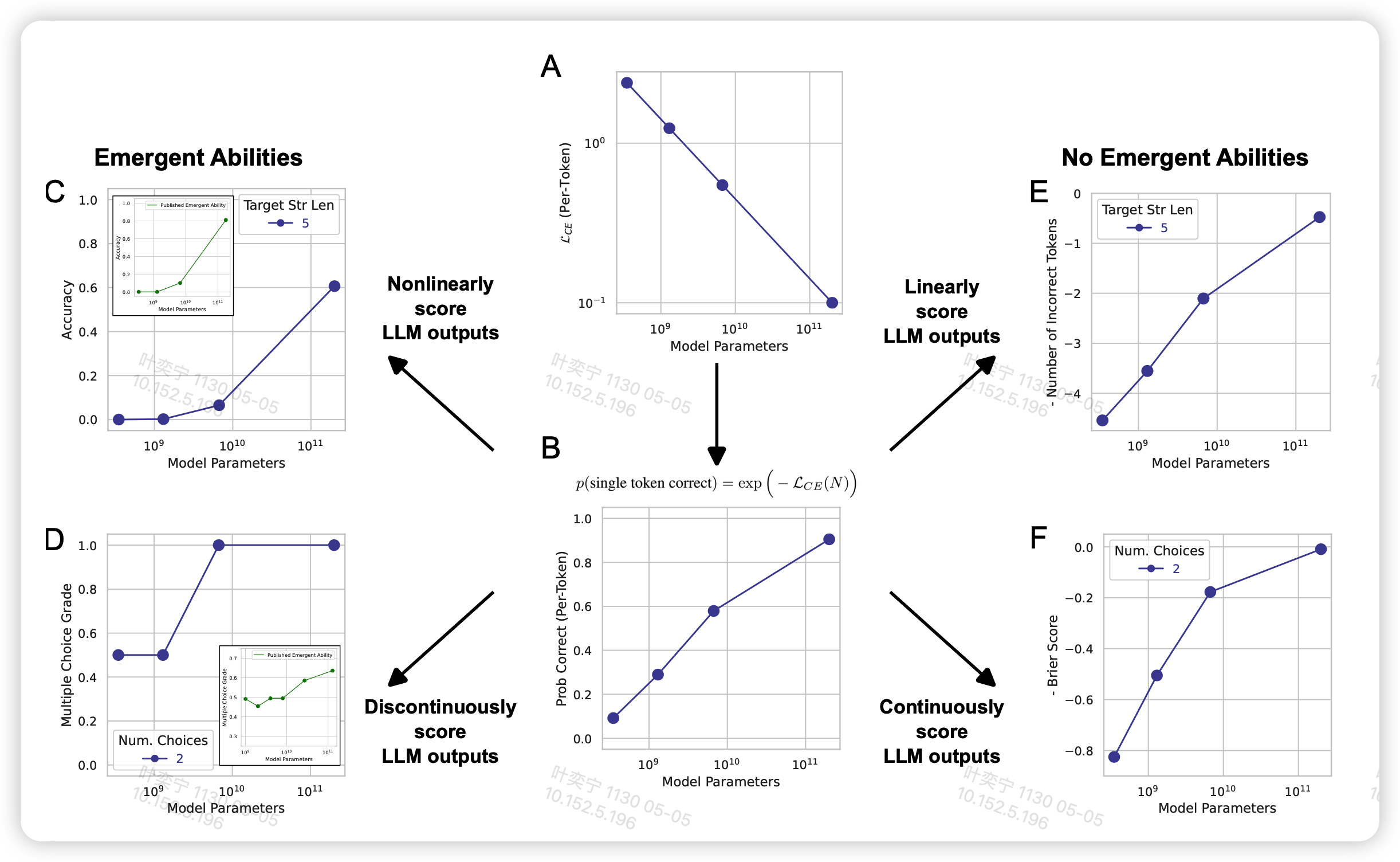
但我们的loss之前解释过 \[ \mathcal{L}_{CE}(N) = - \log P_N(a_j | a_{i<j}) \propto \text{model-size} \] 那么对于一个单独的token,其正确的概率大概是 \[ p(\text{single token correct}) = e^{-\mathcal{L}_{CE}(N)} \] Accuracy-Lc可以视为二项分布,连续L个token都猜对 。string match也是一个意思 \[ P_L \approx p(\text{single token correct})^L \propto (\log \text{model-size})^L \] 因此如果以模型大小为轴,看起来,再加上非常离散的采样方式,看起来就是emergent ability
由此作者提出了现在emergent ability的三个原因:
- 选取的metric和model size不是线性的,而且选取的模型size太稀疏了(GPT-3 family就4个size)
- 测试数据集太小,有偏差
- 无论什么score,增加target string length都会使得表现下降
下面作者做了几个实验
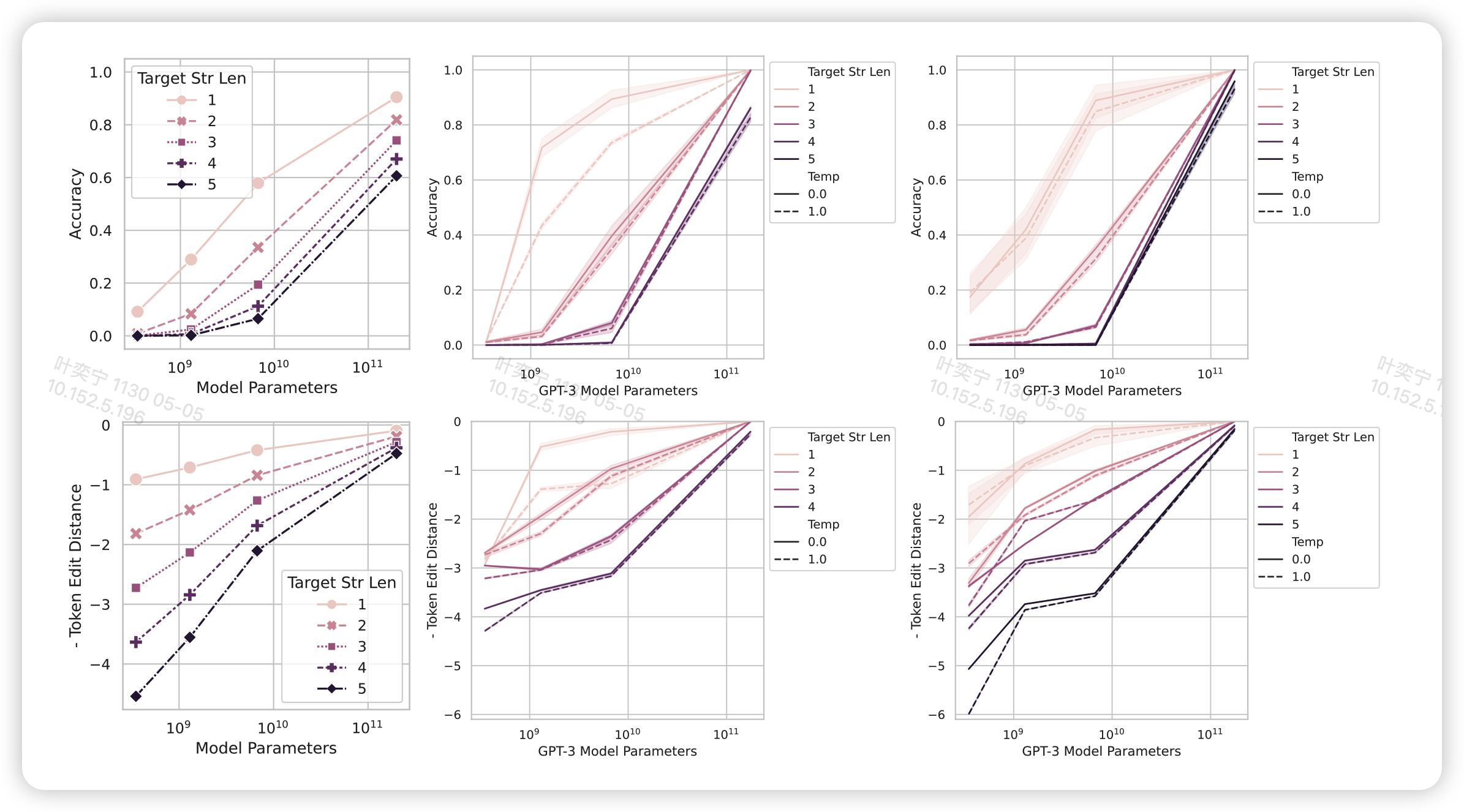
解释下这几个图,作者在GPT3 family的API上做了实验:
- 图中的列从左到右代表三个不同的任务:Mathematical Model, 2-Integer 2-Digit Multiplication Task, 2- Integer 4-Digit Addition Task
- 图的行上下对照是不同的metric,上面是acc。下面是token edit distance,代表错误答案最少修改几个token就能做对。这个score可以近似看做和log model size 成正比,去掉了L的影响:
\[ \text{Token Edit Distance}(N) ≈ L \left(1 − p_N (\text{single token correct})\right) = L(1 − \exp(N/c)^α) \]
从图中可以看到,换成了好的score之后,emergent ability的现象基本就消失了
接下来作者探索了是不是增加测试集大小,普通的score也能看起来好很多
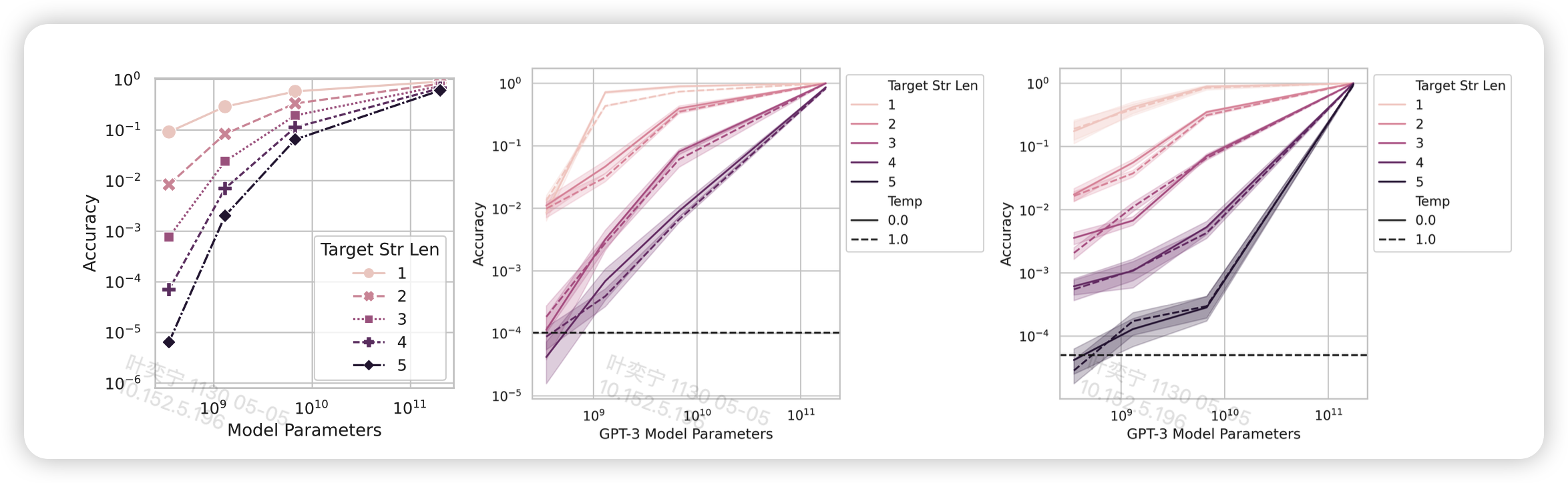
发现看起来确实好了很多,不过这里有个小细节
我戴上赛文眼镜以后,发现这个图的纵坐标变成指数坐标系了?上面图的纵坐标是线性坐标系?
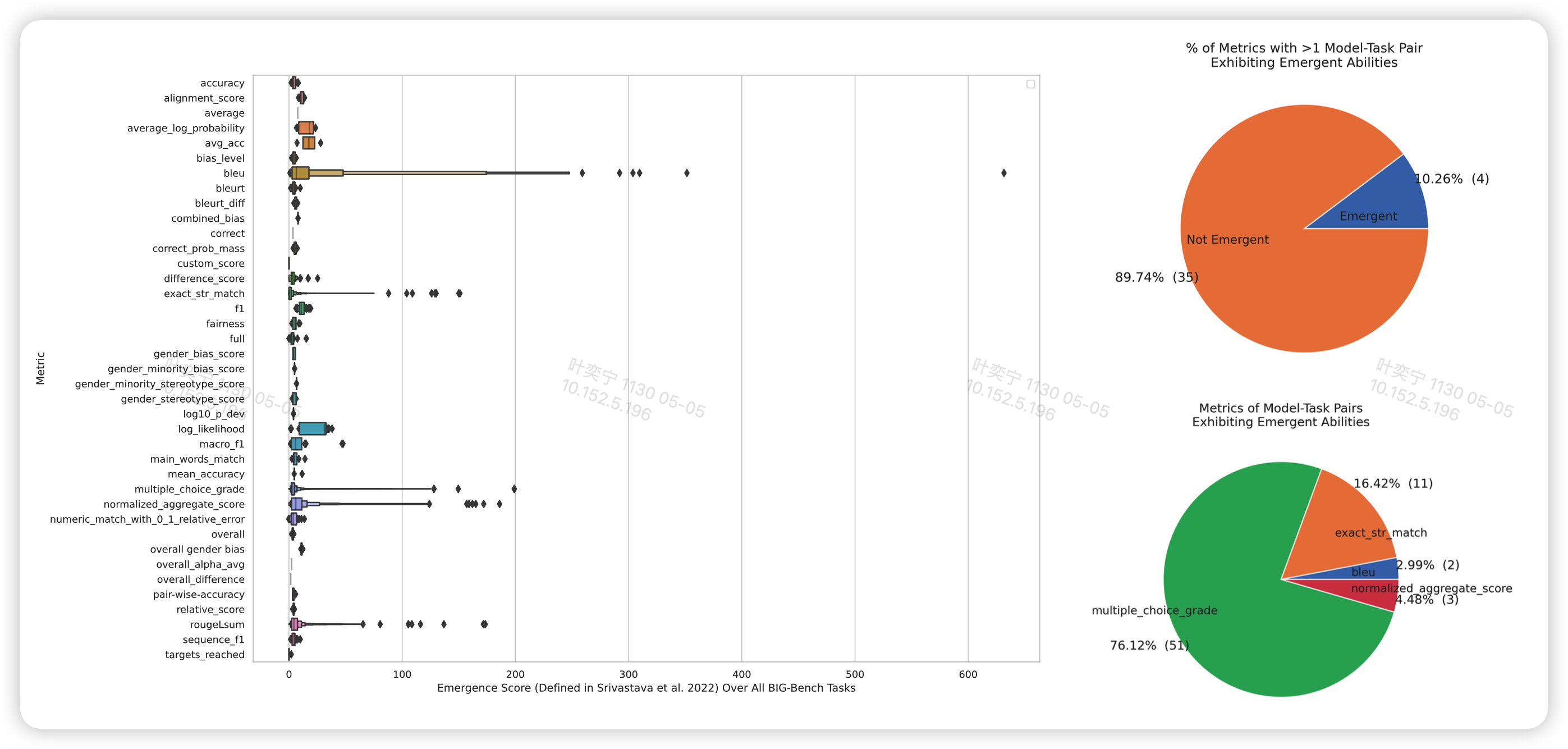
作者还尝试了在big-bench上测试LaMDA一系列的模型,发现出现emergent ability的绝大多数都是这种非线性metric的
最后,作者在CV领域用卷积网络”复现“了emergent ability。它定义了一种非线性score
如果连续K个样本都分类正确,就算正确。K=1时就是图片分类accuracy
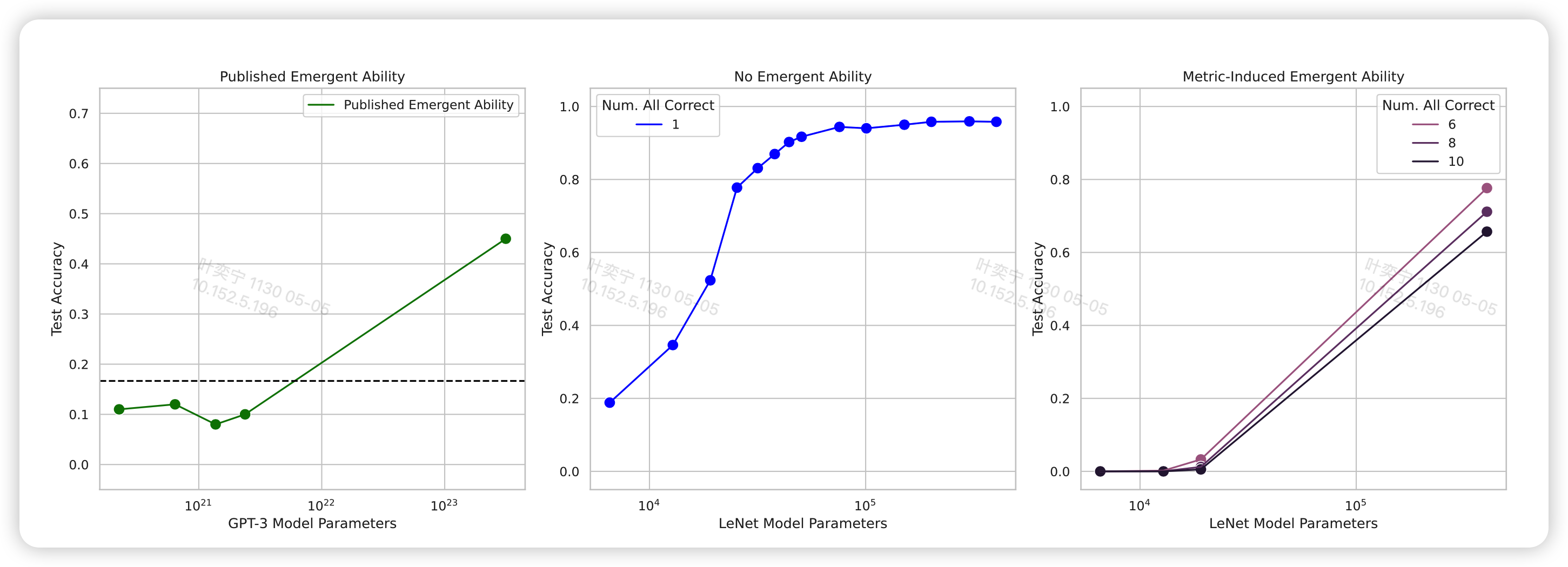
用MNIST数据集做实验,然后稀疏采样了model-size,形成最右侧的图。看起来和最左边GPT3在NLP领域的emergent ability看起来一模一样。
我的思考
我比较认可作者的思路,但这并不是说之前讨论emergent ability就没有意义了。我由此想到了几个问题。
首先,我们在实际应用中,确实就是要用这种类似二项分布的accuracy。而且这个长度L很可能会更大,几十、几百、几千。所谓量变引起质变,这其实对预训练模型领域而言是个很好的现象:虽然模型指数增长,per token loss线性下降;但loss线性下降,对应的是metric的级数级别的的提高。所以pertoken优化的前景仍然广阔。
其次,现在的主流metric如果是如此的非线性,那用他来衡量模型的强度显然是很不合理的。虽然不合理,但是确实符合实际应用场景的。这里面就衍生出了一个bias:有没有什么更好的衡量办法呢?
最后,现在的模型训练显然都是在做NCE、crossentropy loss,这个loss训练很稳定。但这篇文章其实揭示了另一个方面:这种per token的训练和下游任务某种程度上是有偏差的。这接着聊就是老生常谈的teacher-force bias和explosure bias。但其实我们从另一个角度思考一下,现在大火的RLHF其实就是跳出了这个怪圈,从generation级别进行优化,进而得出了很好的实际应用效果。我觉得,也许未来在pertoken的预训练基础上,还能发掘出更多per-generation级别的优化方式。如果设想的再张狂一些,把级别再次拉大,奖励变得更稀疏,是不是就和我们人类对自身的优化方式更像了呢?