最近把读过的所有论文重新整理分类了一遍,在o1出来以后,之前prompt、reasoning、prm、sefl-training这些工作看起来得按照新的逻辑去分类了
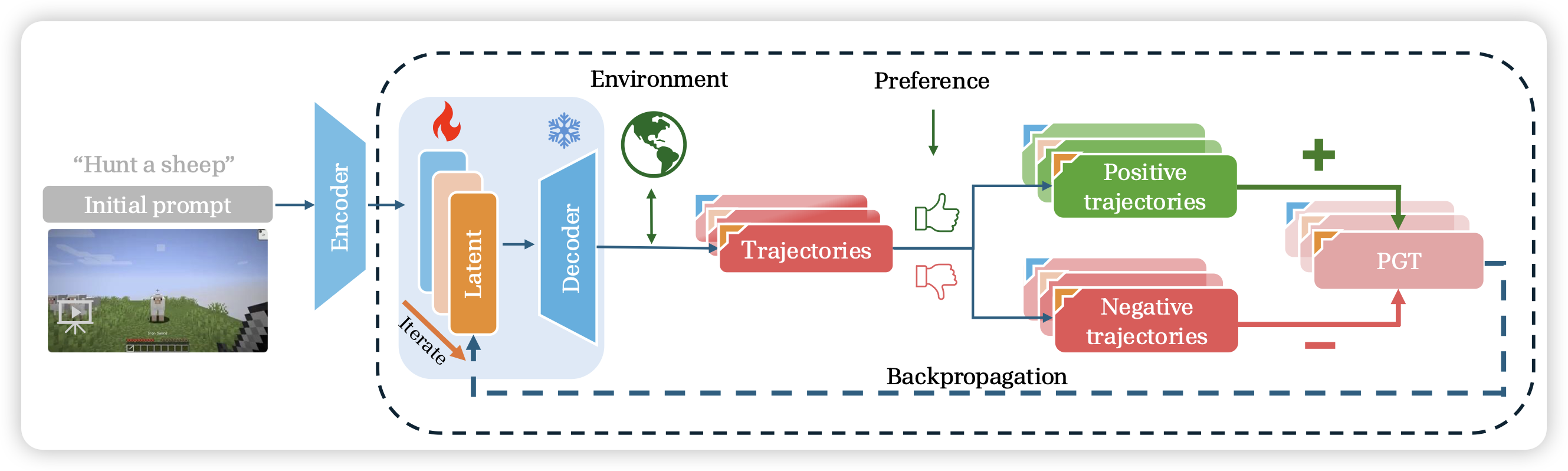
Optimizing Latent Goal by Learning from Trajectory Preference
一篇Minecraft agent的工作,作者提了有趣的观点:很多时候任务做不好,不是因为policy不够好,而是因为没有理解instruction的内容。换句话说,用prompt tuning的方法就能提分。作者想到,能不能解耦开policy和instruction embedding呢?有一个专门的instruction following层可以把自然语言instruction翻译成instruction embedding,再去执行embedding。微调时只tune前面那个层。发现在下游任务上,和全参数微调效果差不多
作者这个建模方式是把他理解成单轮,其实我感觉是不是可以把这个建模成多轮,在agent执行任务前可以用一个小对话组织整个instruction,这样模型有权利自己问一些问题给用户。这个领域,之前有一篇叫star-gate(STaR-GATE: Teaching Language Models to Ask Clarifying Questions)的工作,我一直挺喜欢的……好像没啥人follow