Teaching VLMs to Localize Specific Objects from In-context Examples
一篇挺聚焦的文章,作者关注的是:模型能否根据上下文图片里的som框,认出来想要grounding什么东西,并且在新图片上做grounding呢?显然,没训练的模型都不行,作者finetune过的模型做的还挺好。
说回来,从语言去grounding,和从som去grounding感觉是两个同样重要的能力,但大家确实主要focus前者现在。

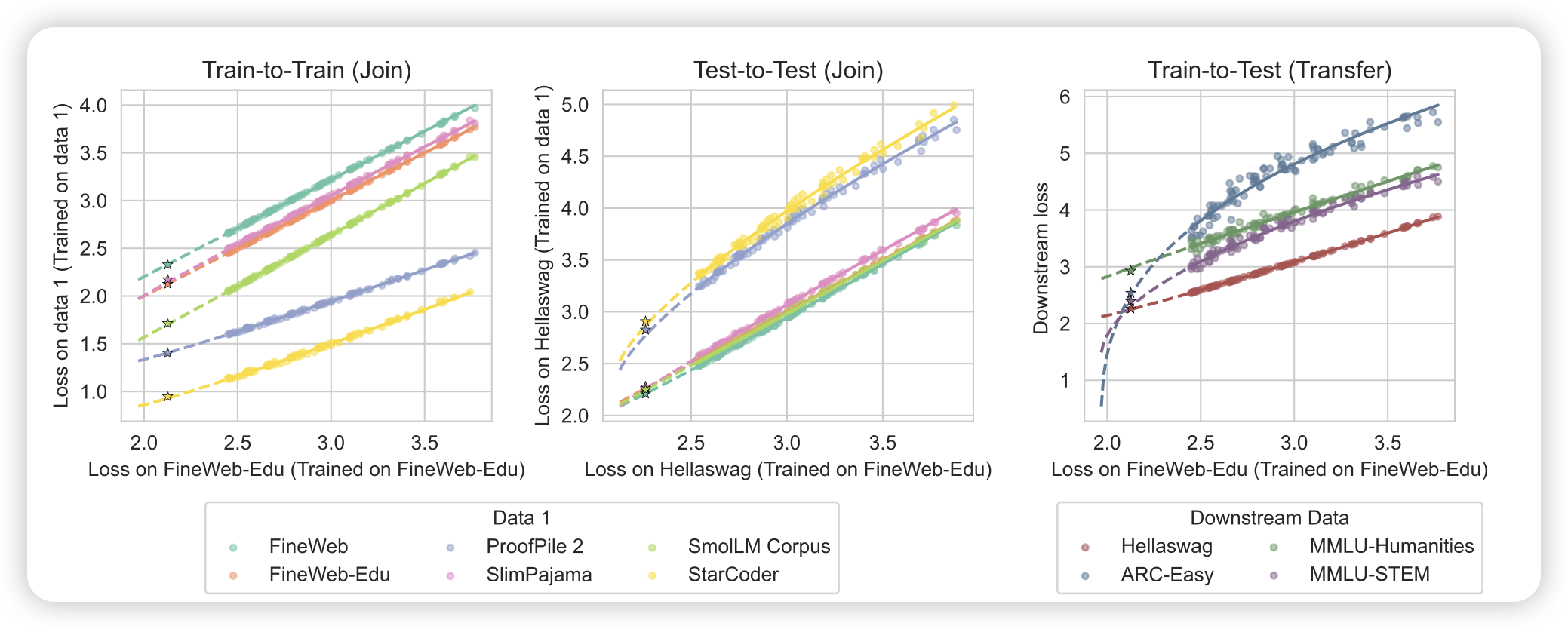
Loss-to-Loss Prediction: Scaling Laws for All Datasets
这名字起得大气,其实是一篇研究scaling prediction的工作。传统scaling prediction讲的是从一个小模型、或者大模型少步数的loss里,预测大模型在同样setting下的loss。作者认为,限制setting一样是一个很大的限制,能不能做跨越setting的预测呢?比如从task A loss预测task B loss。作者发现是可以的
之前有篇叫 observational scaling law的工作,想要通过不同模型家族的指标预测另一个家族的模型。这个是从一个task预测另一个task。所以曲线输入的维度越多就越准吗……
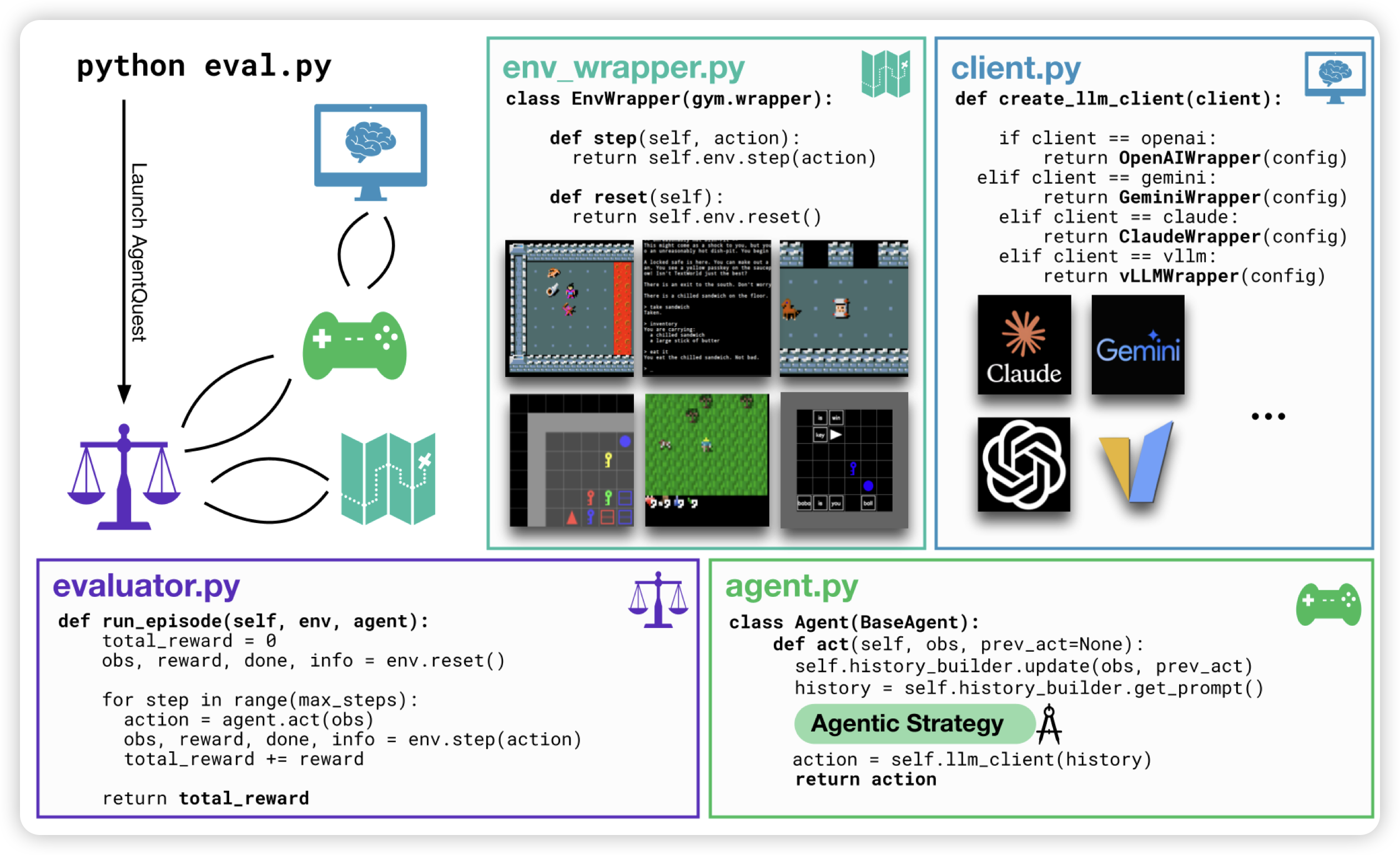
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
一篇benchmark工作,作者接入了几个游戏,然后提供了对于agent的封装的接口,并且给这些游戏设计了一些中间的稠密reward。可以在里面测试LLM as Game Agent