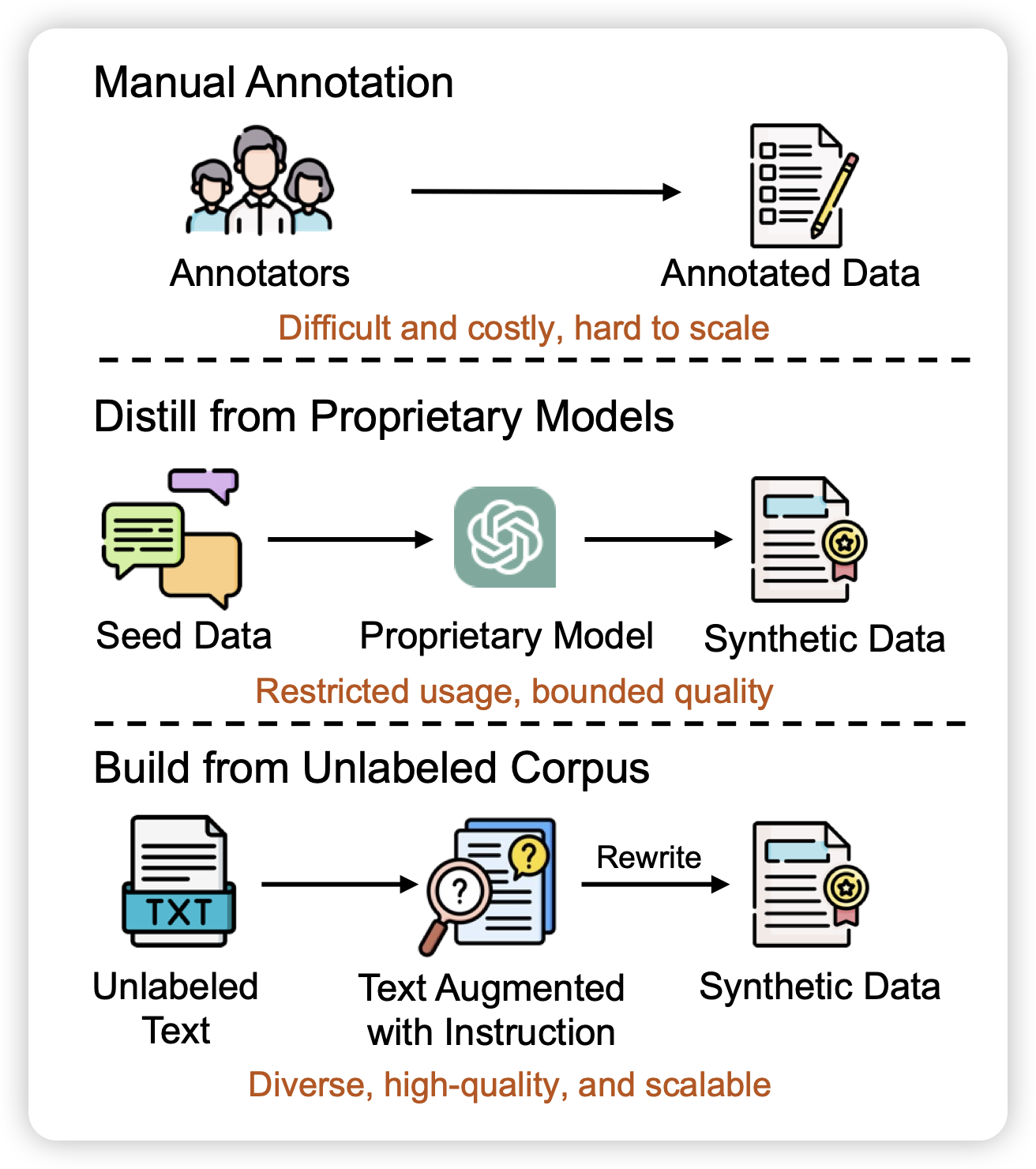
REInstruct: Building Instruction Data from Unlabeled Corpus
如果大家还记得mammoth2,这篇文章探索了类似的事情:能不能从大规模、无监督的预训练数据里挖掘出来SFT数据?
对于这个方法,我一直感觉有个悖论:如果SFT这个过程没有引入额外的信息,为什么对数据进行重组会让模型获得额外的知识呢?有的人会说,"把数据重组成QA可以帮助模型更好地学会知识",不过我现在隐约感觉这里的"更好地学会"对于强模型会变得非常marginal……不知道
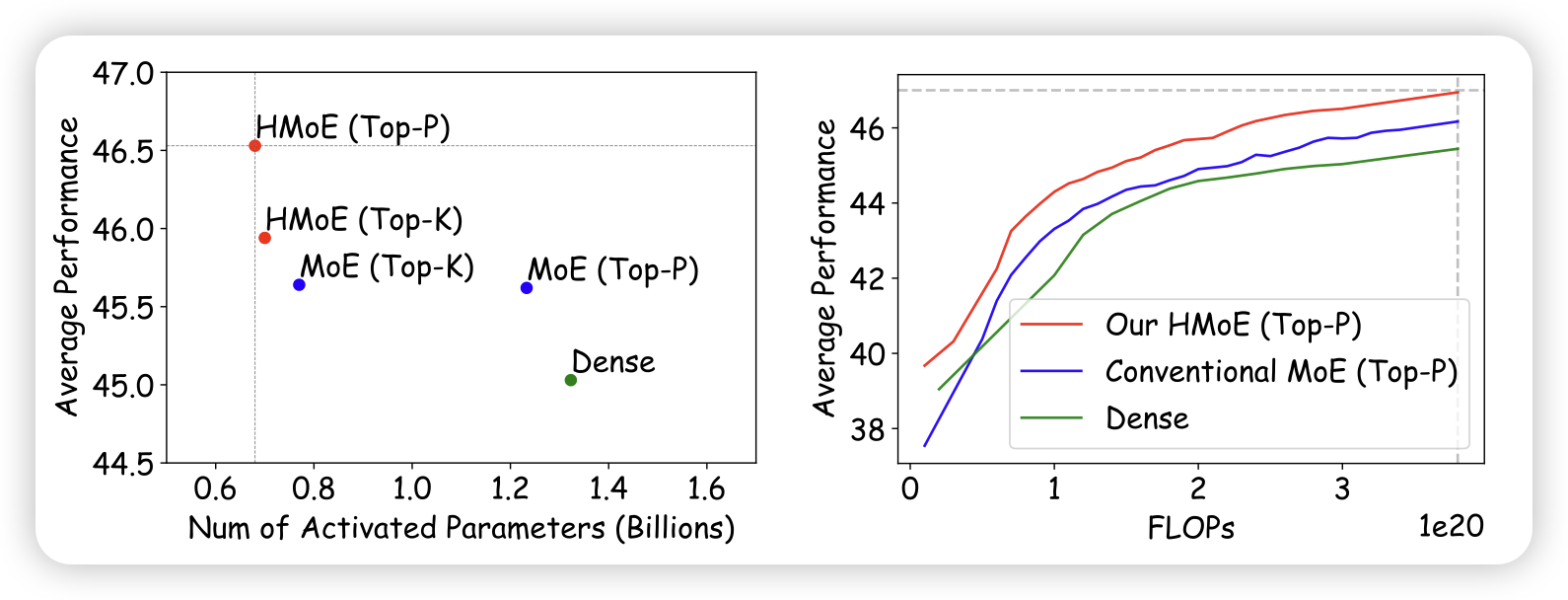
HMoE: Heterogeneous Mixture of Experts for Language Modeling
如果MoE里不同专家的大小不一样会怎么样?这篇工作探索了,发现显然,模型会更倾向于激活大专家。所以作者改了loss让模型更多地去尝试激活小专家。经过训练,这样的HMoE比传统MoE数据效率更高。
在我看来,这个东西有点像是让"小专家"从"大专家"上蒸馏知识,小专家为了被激活不得不去学着表现得像大专家。
比如说啊,如果infer时我把大专家删了,是不是就成功训练出来了一个"高效小模型"呢?但本质上是从大模型上蒸馏下来了参数?