总算是把过年出去玩欠的账补回来了,总体来说,一共有三天(1.31, 2.4, 2.5)的论文再也回不来了,可能这就是天道有缺吧……
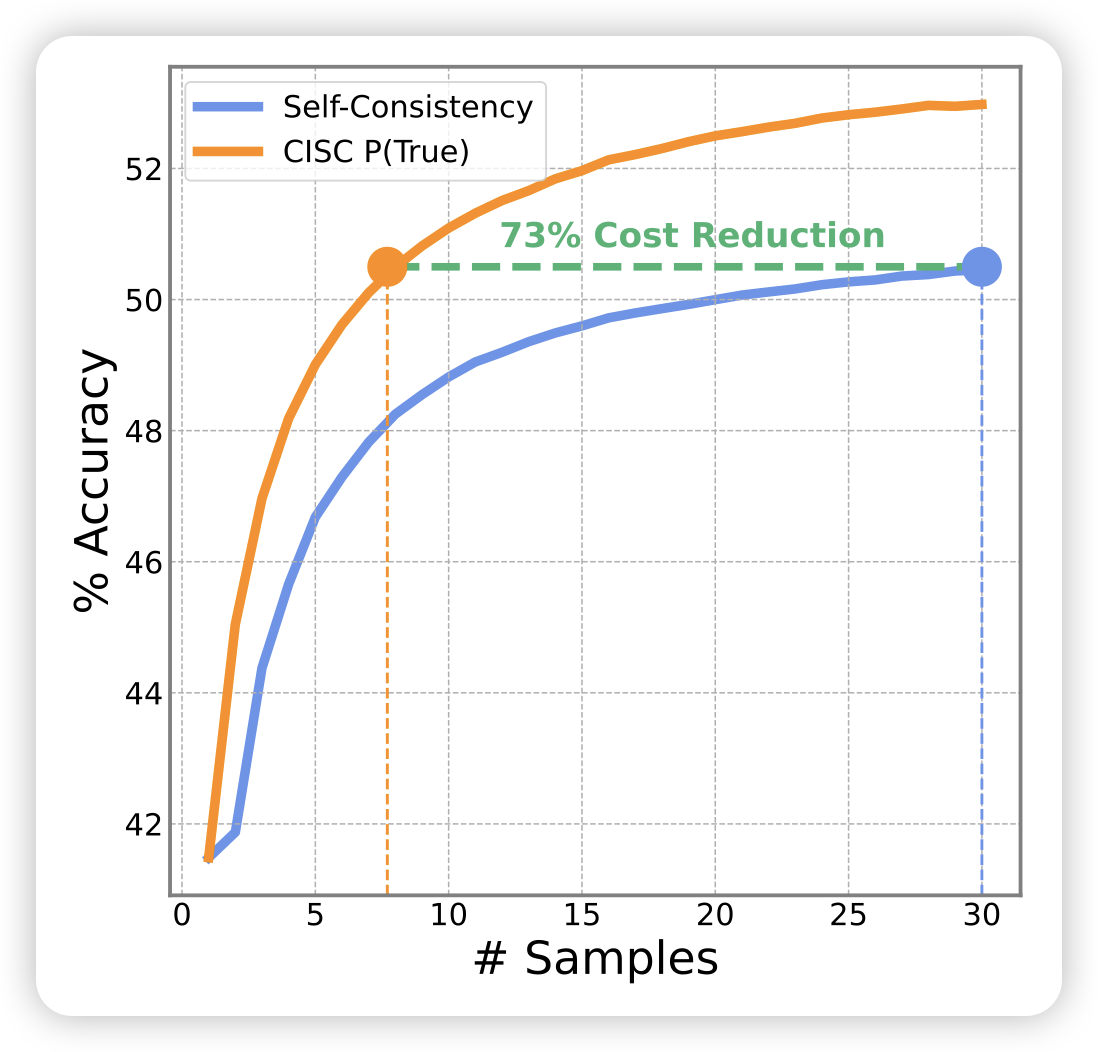
Confidence Improves Self-Consistency in LLMs
o1出来以后,consistency这种传统test time scaling领域好像关注度一下变低了。这篇是一个改进self-consistency的工作,作者发现在投票时,直接把模型生成的ppl做加权,就会比正常的consistency做的好
怎么感觉有点眼熟,去年有个叫more agents is all you need的工作,好像也在讲这个
Towards Internet-Scale Training For Agents
这篇工作挺有趣的,是一篇合成数据的工作。作者想要让LLM自动合成web navigation的数据,就让模型自己根据网站生成query,自己做,再自己打分,最后把做的比较好的query训练回去。发现通过这种方案,提升了下游任务的效果。
这个领域,最近有AgentTrek,OS-Genesis都挺不错的。

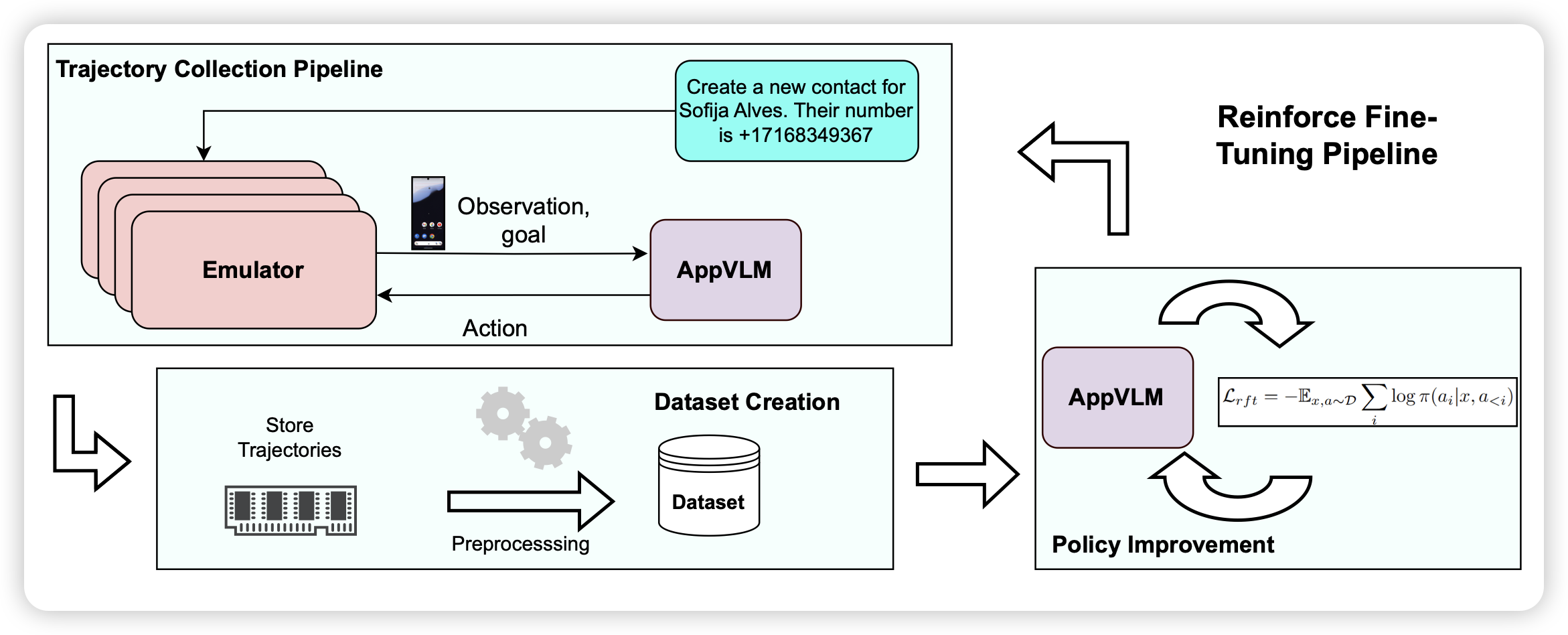
AppVLM: A Lightweight Vision Language Model for Online App Control
这篇工作和我们TARS做的有点像,作者构造了一套先sft再reft的方案,在Androidcontrol训练集训完以后,去androidworld在线测试集测试,把好的trace训回去。发现通过这种方案,大致可以继续提高模型的效果