今天论文都挺好的
From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities
这篇更好玩,是omni架构系列的工作,作者的想法是:能不能把bpe的思路应用都图片上,给每个patch打出来一个id,然后做image encoder。作者发现这样搞效果巨好
不是,哥们……

Video Instruction Tuning With Synthetic Data
很经典的llava系工作,作者整合了各种video caption数据集,最后合成出来了187k video sft数据,然后找了一波超参数,搞了个效果不错的llava-video模型。
这个和之前的llava-interleave的区别在哪
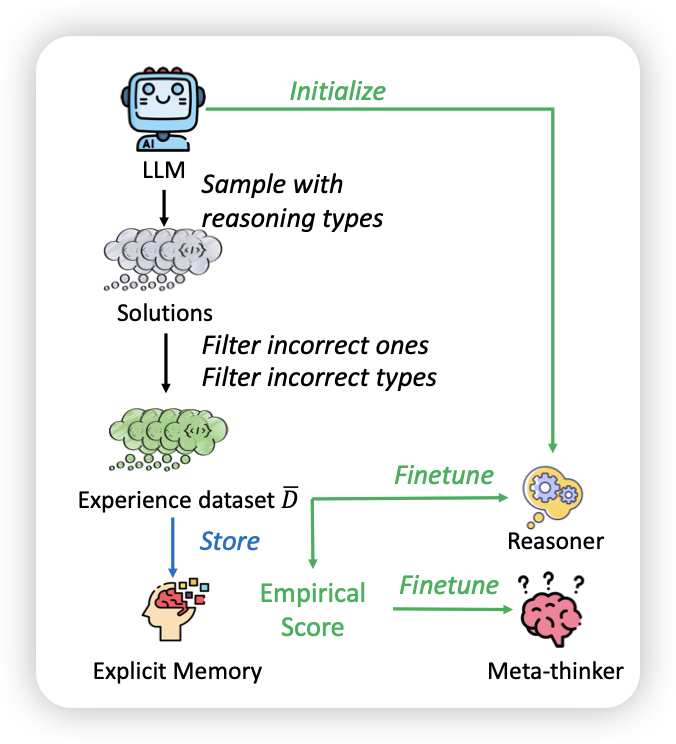
TypedThinker: Typed Thinking Improves Large Language Model Reasoning
Qwen团队的工作,幽默老中十一挂论文。沿着self-discover继续深入,作者发现不同的reasoning module适合不同的场景,如果让模型给每个query尝试不同的reasoning module,然后把答案正确的样本挑出来作为正样本,似乎可以让模型持续地自我迭代学会如何灵活运用各种reasoning module。
AVG-LLaVA: A Large Multimodal Model with Adaptive Visual Granularity
一篇挺有趣的工作:作者发现VLM中,图片分辨率是一个很本质的参数,但不同的query实际上对分辨率的要求不同。能不能设计一个router根据query来确定分辨率呢?作者做了一波实验,搞了一个多分辨率级联的系统,发现还真可以
这个方案感觉有点像是自动丢弃visual token的方向,这个方向感觉一直没有找到很好的回传梯度的方案
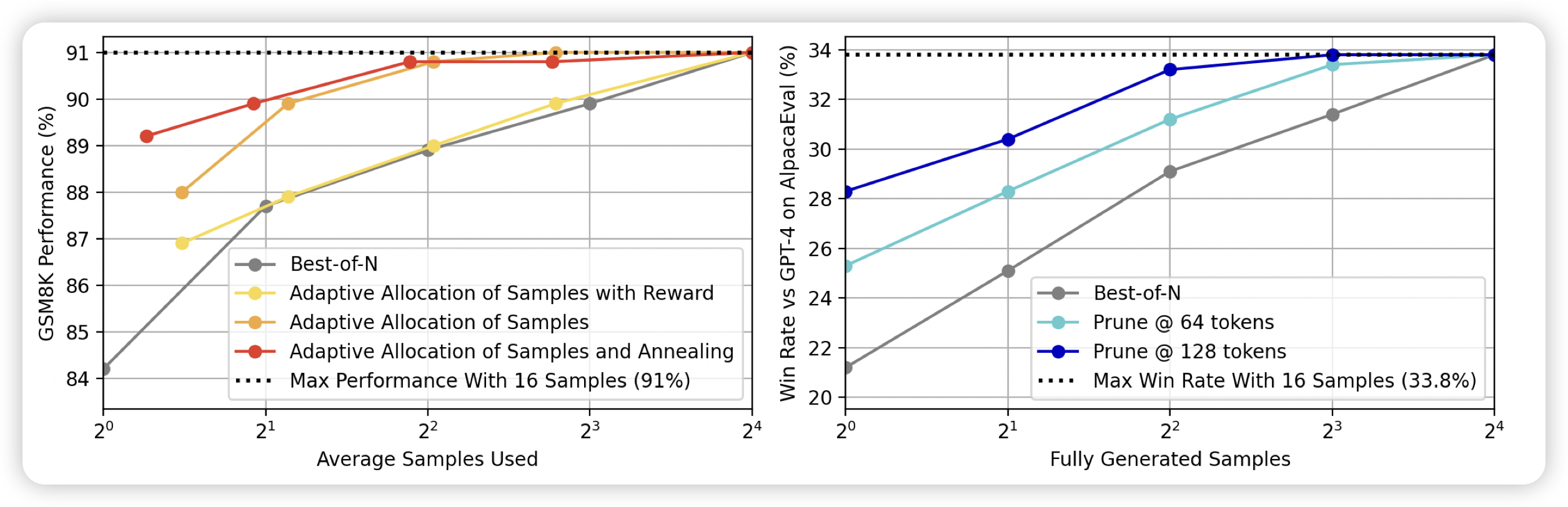
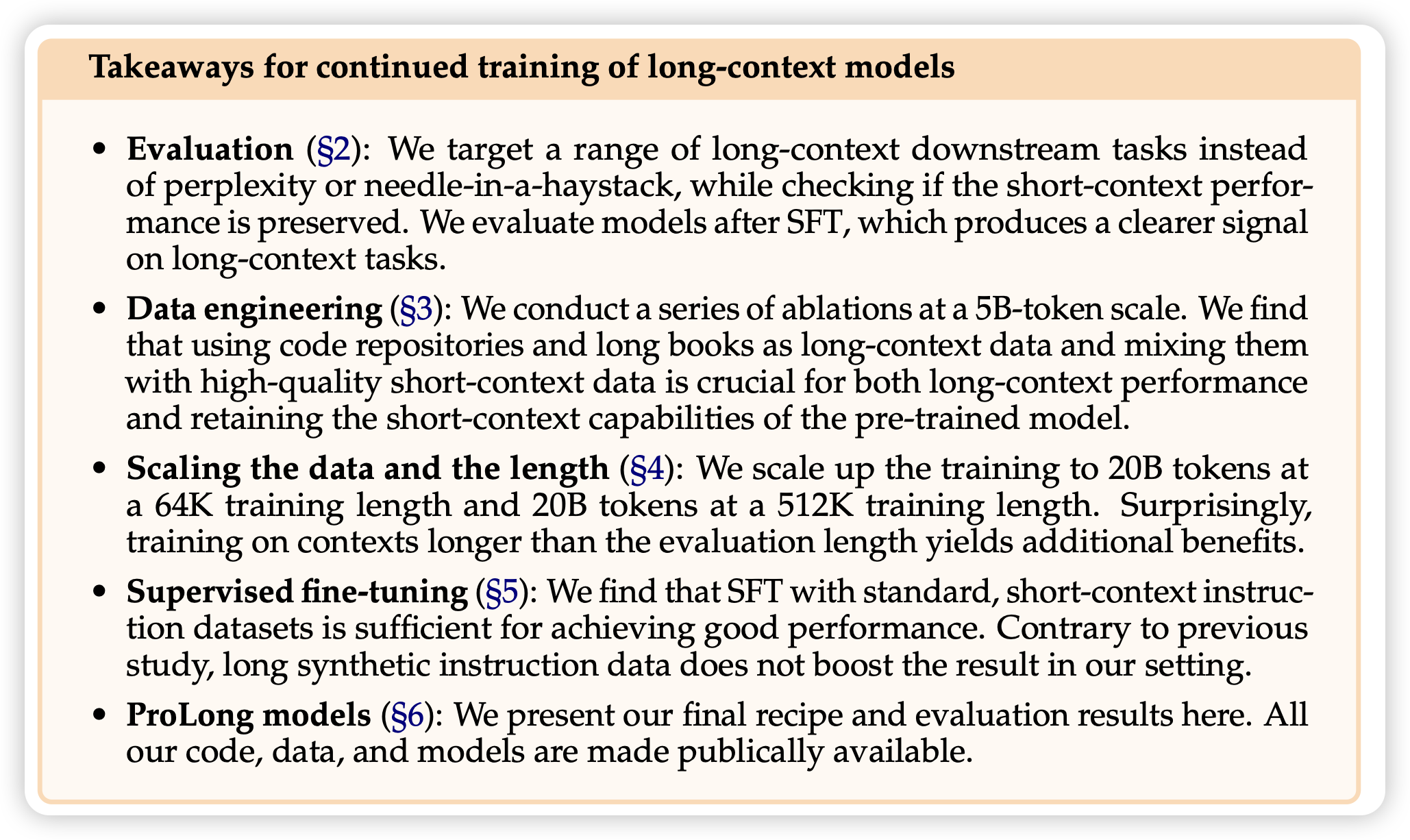
How to Train Long-Context Language Models (Effectively)
Tianyu学长的工作,看标题就很牛,实际上确实工作量很大。主要结果都在下面了↓
Adaptive Inference-Time Compute: LLMs Can Predict if They Can Do Better, Even Mid-Generation
stanford的工作,好像最近挺少见他们的工作不知道为啥。这篇行文挺有deepmind风格的。作者讲的事情是,很多任务中,模型在生成到一半的时候已经犯错了,但已有工作往往是等生成完再打分。能不能让模型有权利生成一半直接掐掉呢?作者探索了一下,发现还真行