ICLR的投稿论文质量就是高,感觉逐渐出现了一些看起来像是o1的工作
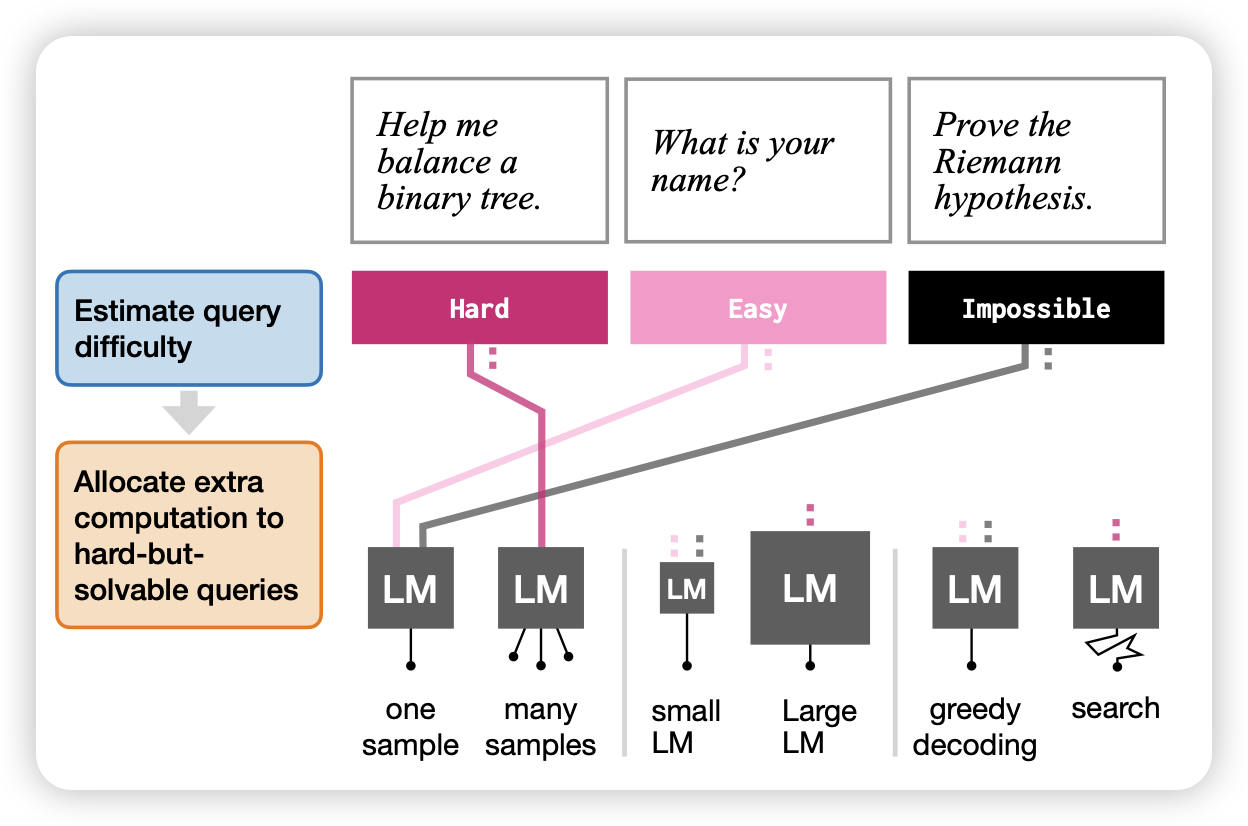
Learning How Hard to Think: Input-Adaptive Allocation of LM Computation
Jacob Andreas的工作:作者探索了能否根据任务难度动态申请计算空间,然后让模型决定做CoT、self-consistency之类的inference-scaling技术。通过这种方法,可以在保证最优效果的前提下,省下来超过50%的计算资源
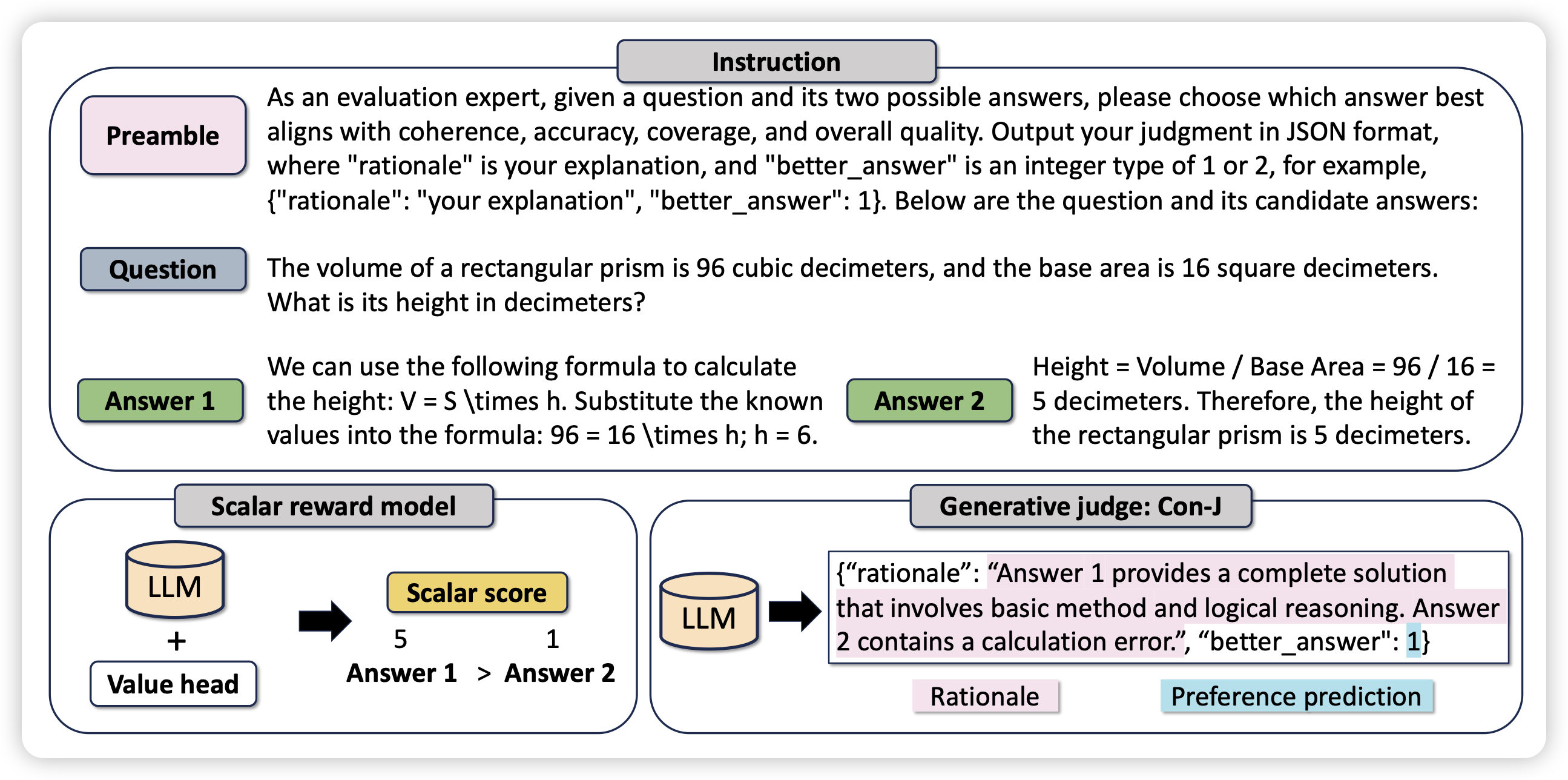
Beyond Scalar Reward Model: Learning Generative Judge from Preference Data
liuyiqun老师转型了,去搞post-training了。这次是generative reward model,是说让reward model也是生成式的、CoT的,而不是从human偏序里蒸馏出来的float。虽然不是第一篇,但我很喜欢这个方向,现在看见就转
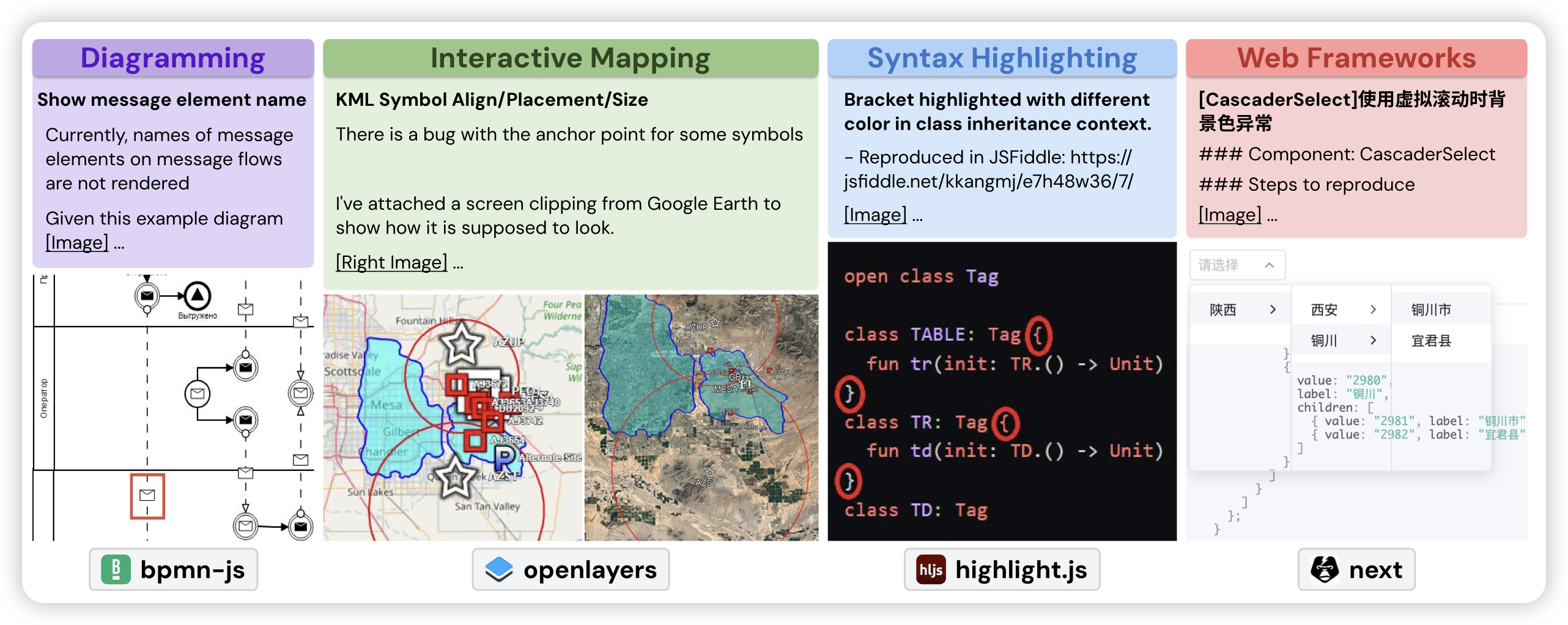
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
我最开始看到这篇工作,还以为是让模型通过键鼠操作vscode来编程……仔细一看是解决多模态的编程问题。作者构建了一个新的bench,输入的问题描述或者testcase里最少有一张图片,需要多模态模型运用多模态能力来理解或者解决问题
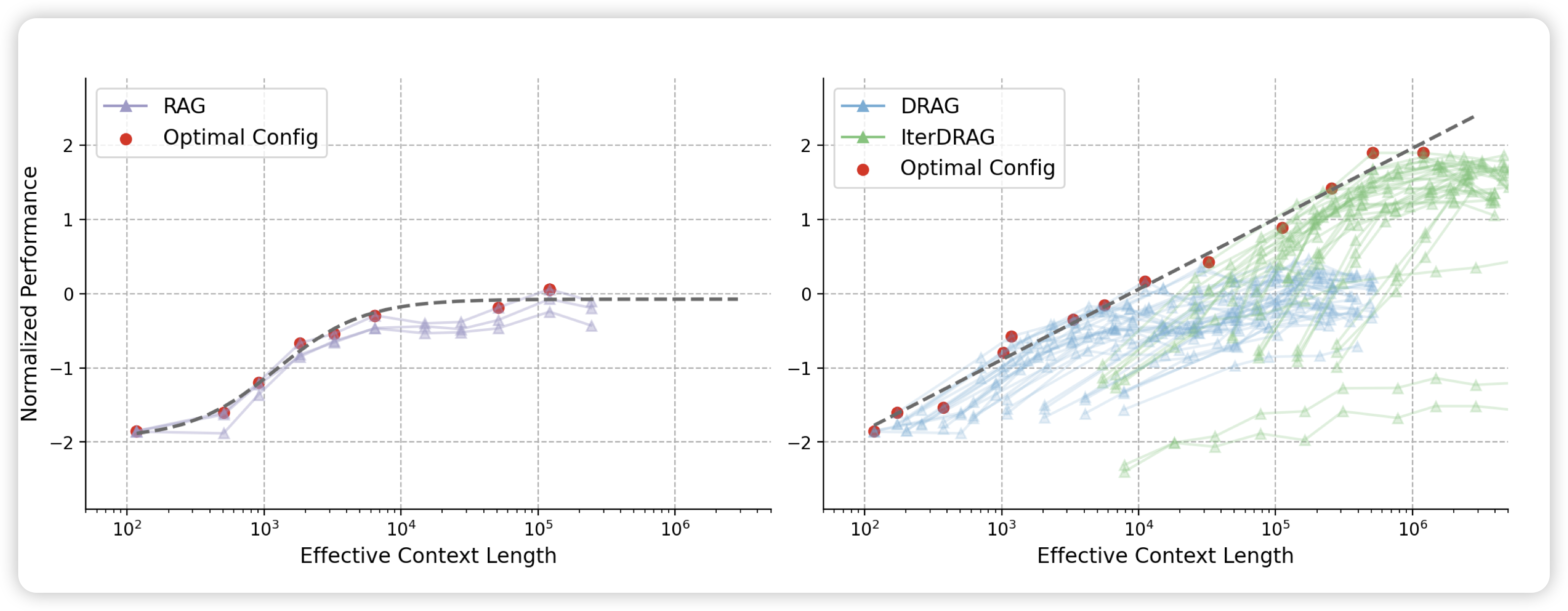
Inference Scaling for Long-Context Retrieval Augmented Generation
Deepmind的工作:作者结合了之前的many-shot ICL,认为其是RAG的inference-time compute领域的一种scaling方案。另一种方案是使用不同的RAG prompt抽取很多次做一堆infer。对于每个query,都可以使用这两种方案做各种实验,比如100-shot,或者用10个rag prompt做10次10-shot拼成一个100-shot,总体budget一致。作者经过研究,发现如果给所有budget做到optimal的情况下,performance和context-length是可以符合scaling law的
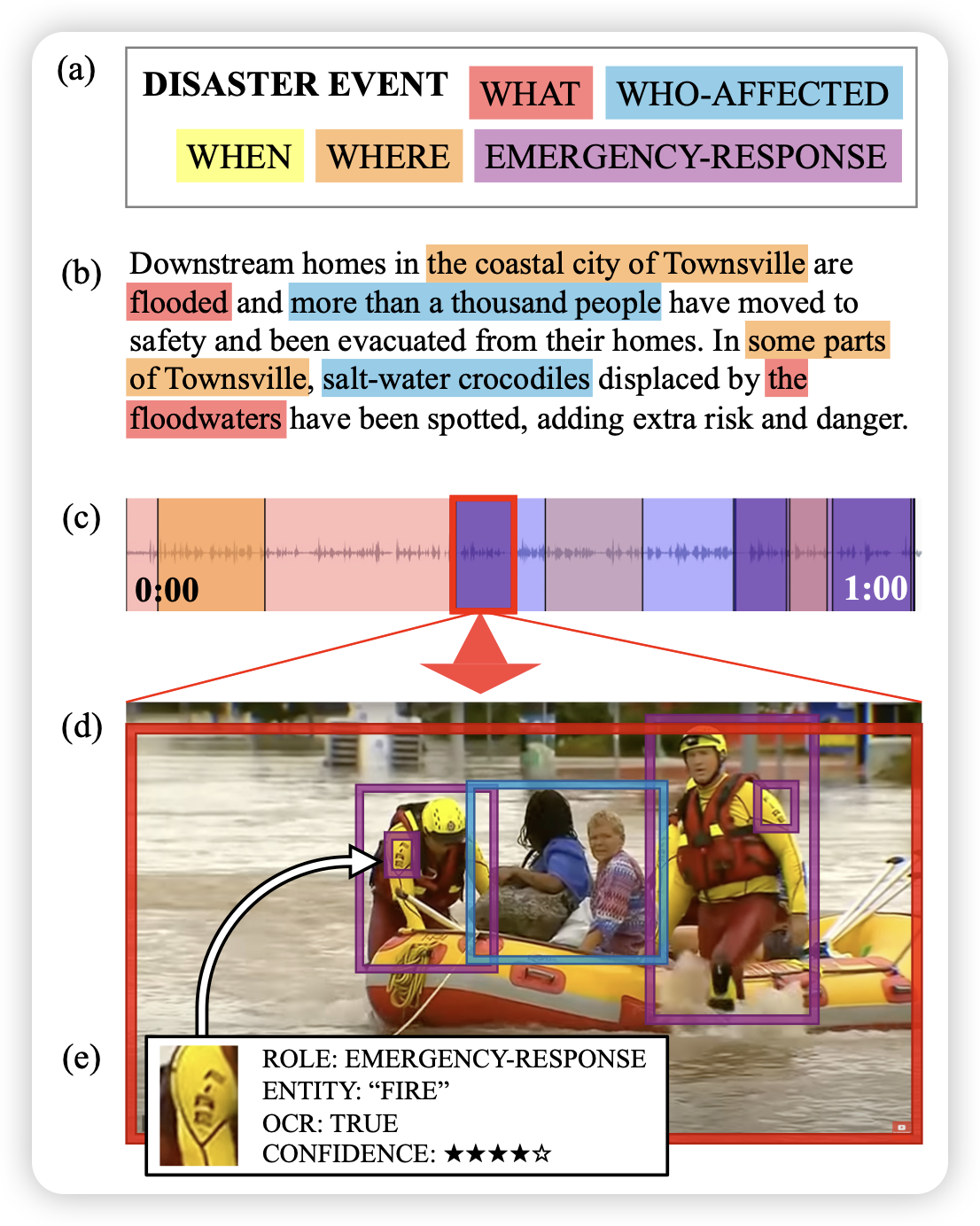
Grounding Partially-Defined Events in Multimodal Data
作者标注了一个dense数据集,可以把caption中的各种实体、事件链接到时间信息,并进一步在空间中给出坐标,包含大约15h的标注视频。