SeedEdit: Align Image Re-Generation to Image Editing
字节的工作,主要做image editing的任务:用一个自然语言的修图指令,就可以对图片做微调。作者认为在这个任务里有两个关键点,一个是模型能不能遵循指令,另一个是模型能不能生成和原图一样的图片。

Moving Off-the-Grid: Scene-Grounded Video Representations
作者提到,目前的VLM或者CV模型,都是把图片的空间信息编码到固定的token上,叫做on-the-grid。这会导致模型给特定的patch学到特定的含义(比如太阳总会出现在上面的patch里)。由此,作者设计了一套off-the-grid的方案,可以提升图像embedding的鲁棒性和质量
I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength
上周出了个pika camera-control的复刻版,这周又来了个复刻版,感觉这个方向变得火了起来。
说回来,video generation camera-control和GameNGen那种生成游戏画面,感觉都是给视频生成多了个输入维度,但是在不同的场景……不知道有没有人做个多场景统一的camera-control出来

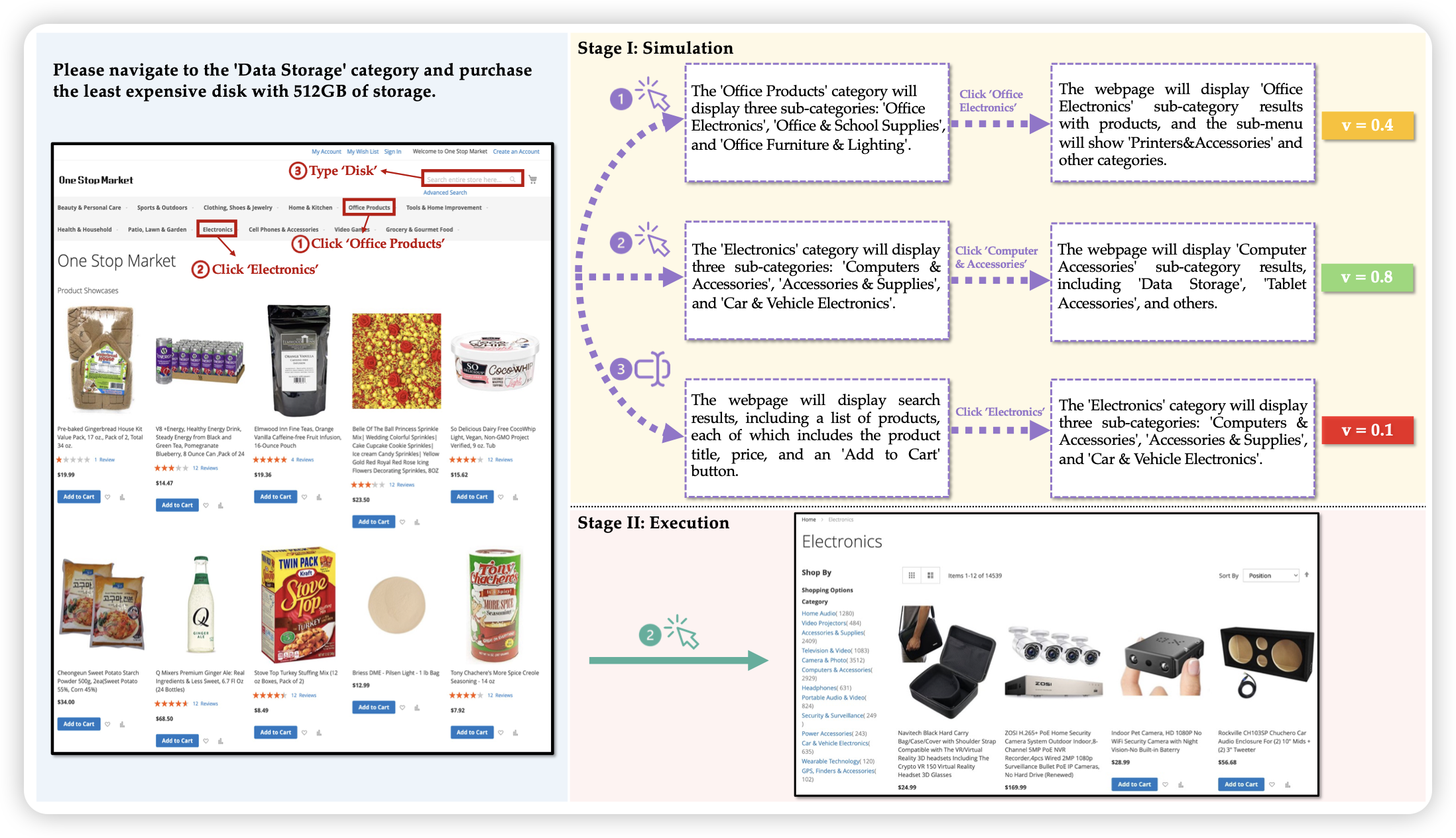
Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
一个挺有趣的GUI Agent工作,作者思考了一个问题:模型能不能设想一个action结果是什么呢?如果可以的话,让模型在自己的思考空间做推理,然后选择自己打分高的设想,去真的执行会怎样?作者把这个方案叫做webDreamer,发现还真能在online环境里提分
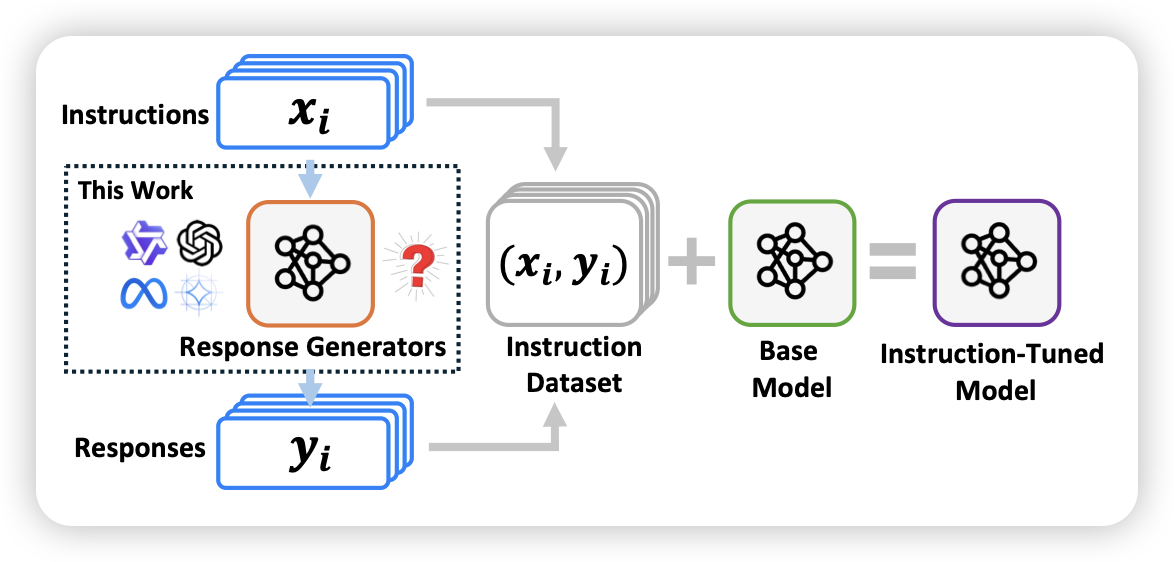
Stronger Models are NOT Stronger Teachers for Instruction Tuning
作者提到,目前的SFT数据,主要就是找一个比较牛的模型在一堆instruction上sample response,再丢给小模型学。然而这里面有个关键的假设:强的模型标的数据,训出来的小模型就会更强。
作者做了一大堆实验,发现竟然不是这样?
为什么呢,难道真有 knowledge boundary的说法?