MoE-Pruner: Pruning Mixture-of-Experts Large Language Model using the Hints from Its Router
挺好玩的工作。在MoE prune领域,作者发现:已有的MoE都是router算出来一个专家一个得分,然后把得分前两名的专家embedding拿来,按照router得分做加权平均。如果专家本身是可以线性叠加的,那我直接把专家的权重按照router得分线性叠加,把一堆专家变成一个专家会怎样。作者在mixtral上试了试,发现效果出奇的好。
Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective
如果只看CL track,估计就没有这篇论文了。最近有些生成理解统一架构的工作出来,这篇工作更聚焦一些,关注了transformer架构做图片生成。作者把LDM等latent space训练稳定的方法归因到了latent space本身稳定性上。由此魔改了一番transformer,发现效果神奇地挺好
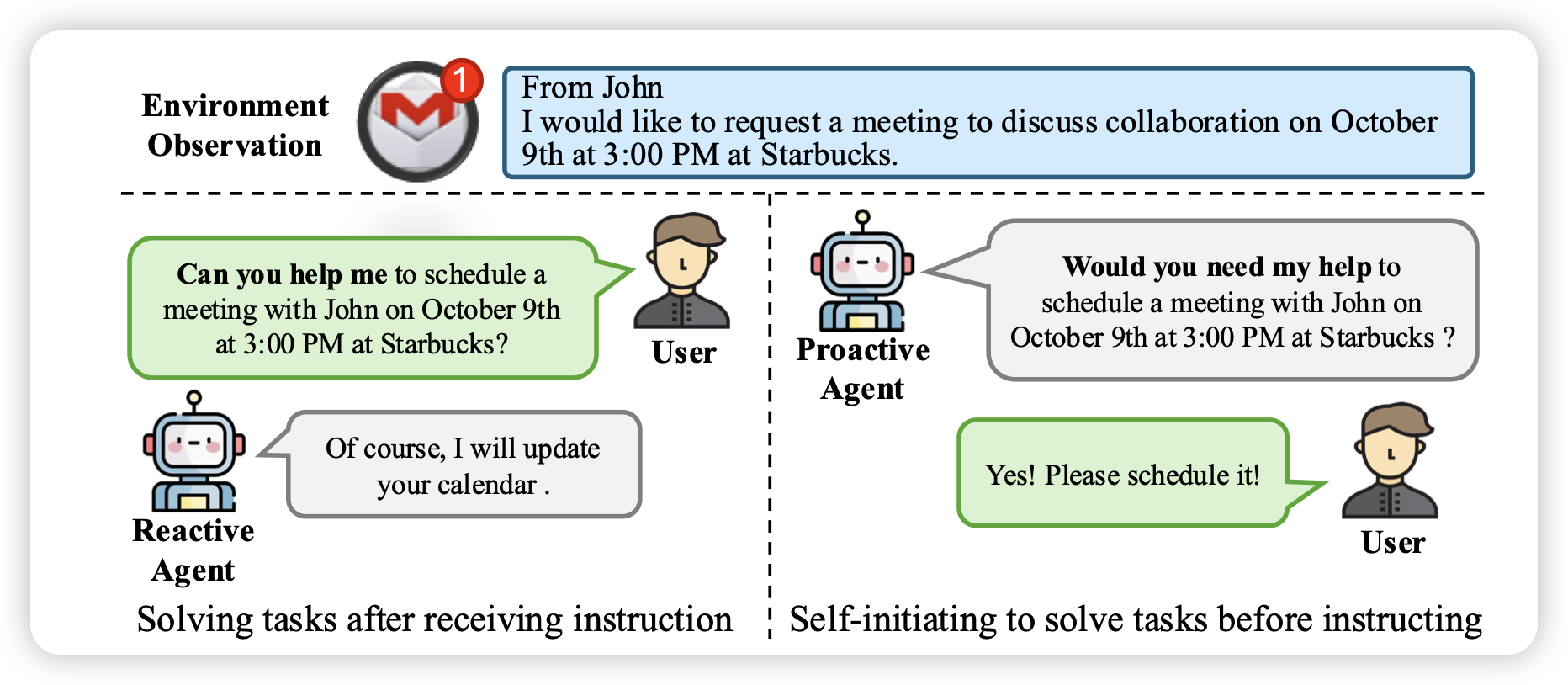
Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance
推荐哥们的工作,其实做了挺久了。作者提到一个问题:目前的agent都是接收式的,下达一个指令,完成一个指令。但在真实世界中,模型如果和人共享一个context,那模型有没有能力直接想到人会有的需求呢?作者标注了6000多数据,让人verify了可能的任务,然后对应训练了reward model。最终在测试集上,发现训练出来的proactive model有F1 66%的可能提到和人类一样的query
copilot变pilot了