Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
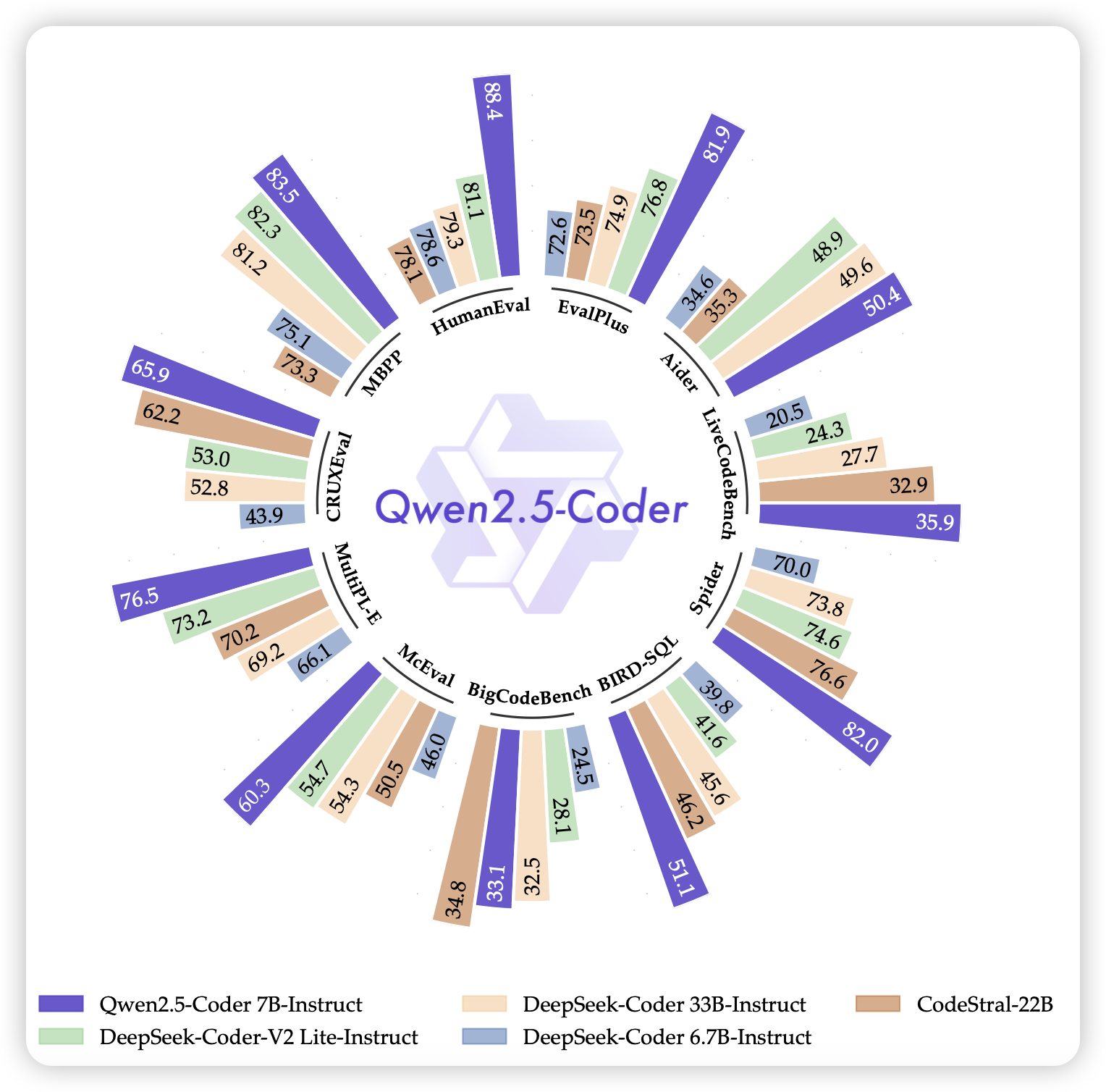
Qwen2.5-Coder Technical Report
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
昨天qwen放了2.5系列的一大堆模型:
math模型,用了self-improvement,2.5 7B就超过了2 72B。MATH直接刷到85%
code模型,光是continue training就用了5.5T token,效果果然强。
vl模型,blog早放了,但是论文现在才挂出来。现在支持了多分辨率
看来llama3 的15t token影响了所有人呀
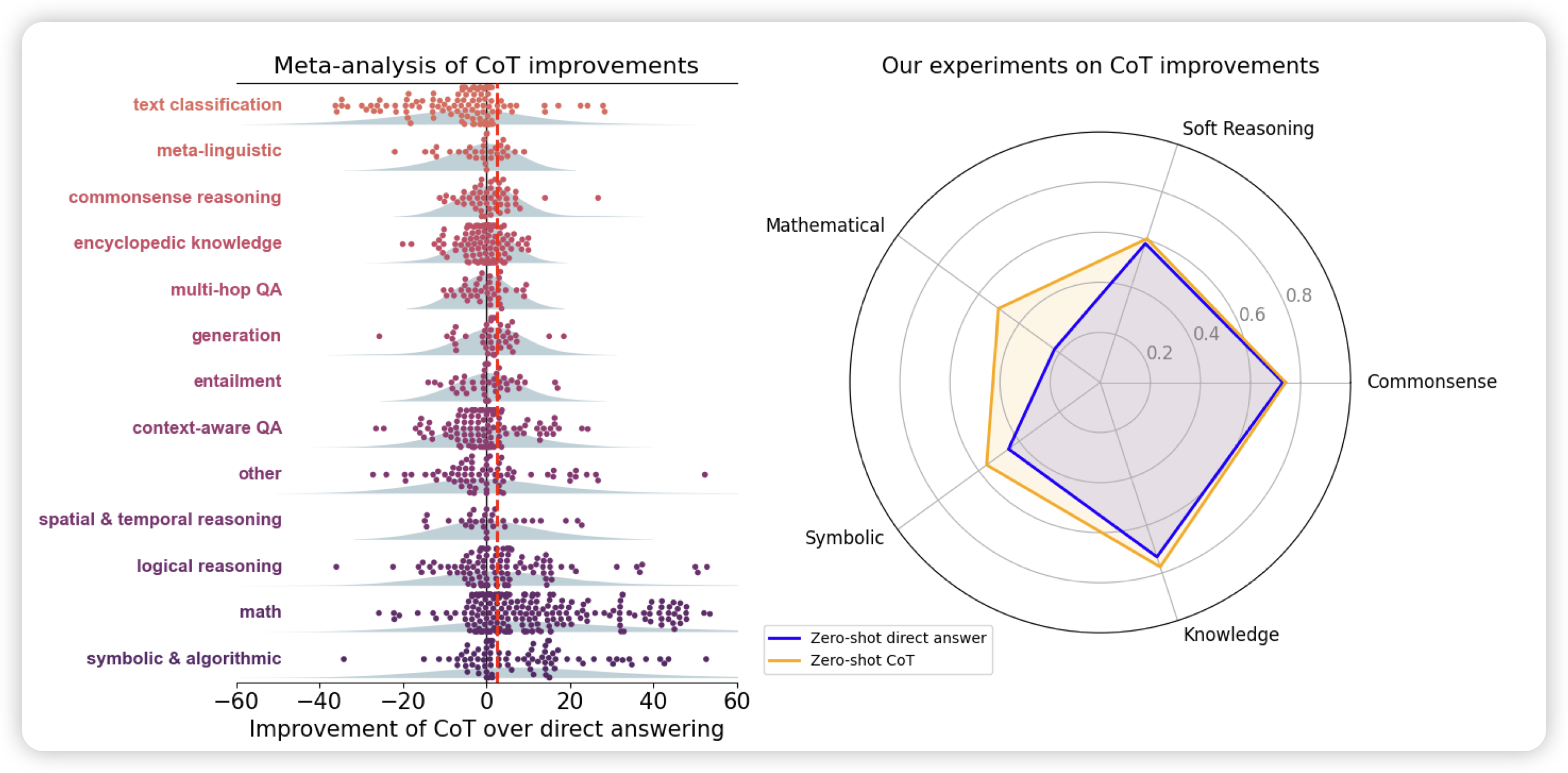
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
作者研究了多个模型在不同数据集上用CoT的效果,发现所有的提升基本都在math和symbolic场景上。在比如MMLU这样的知识题目上,除非问题里包含“=”符号,否则根本没有提升。所以作者怀疑CoT有其适用范围
我在想:会不会和cot的语义有关系,现在大家更愿意称为“scaling inference time compute”,是不是因为cot的内容不够diverse,没有涉及到“对知识场景有提升的prompt上”。