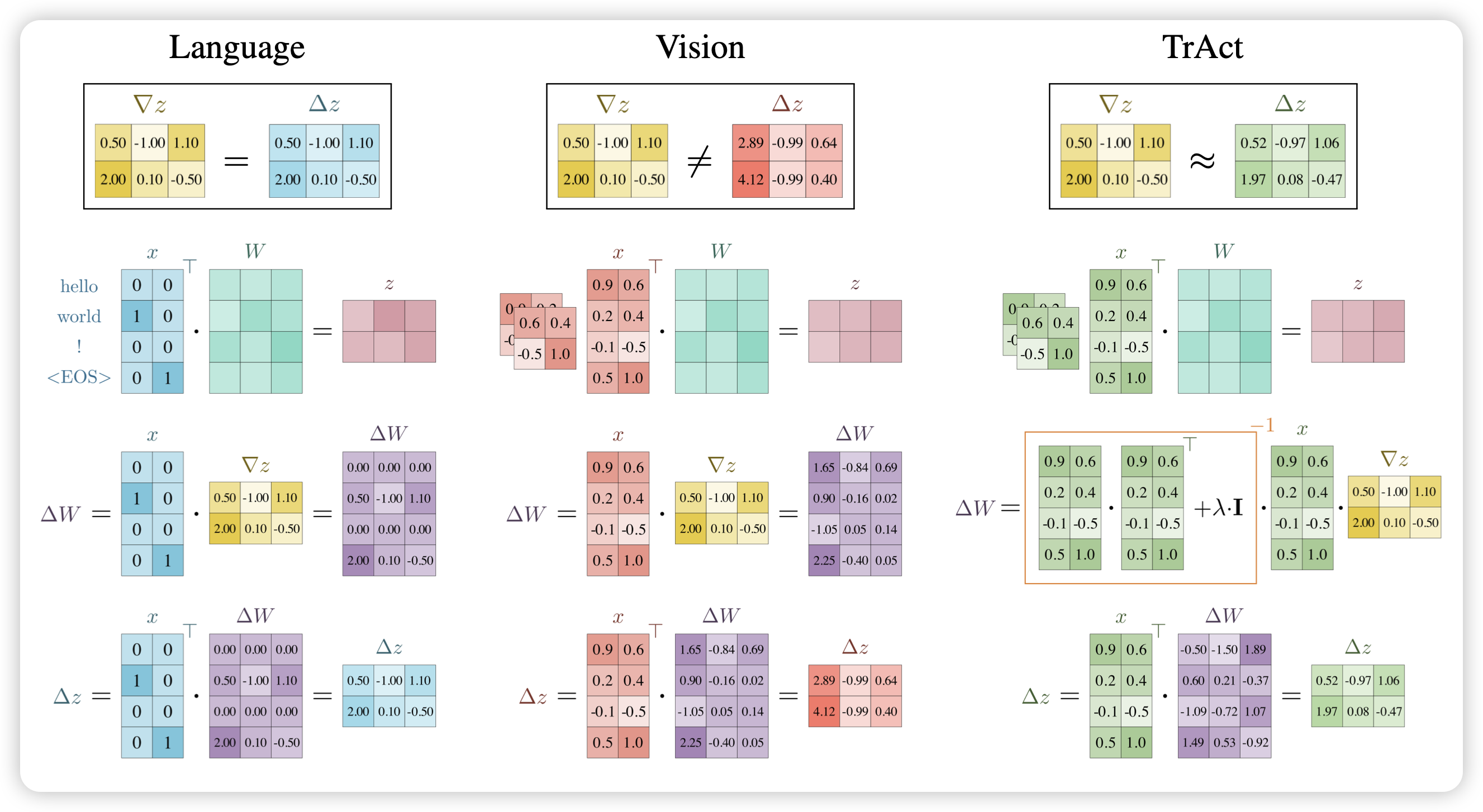
TrAct: Making First-layer Pre-Activations Trainable
很有NeurIPS风格的工作:作者发现,Vison model中第一层vision layer的gradient正比于图片本身的像素均值,所以越亮的图片,不管是什么内容,对模型的效果都影响更大。设计了一套方法把这个bias去掉,在第一层添加梯度衰减以后,发现训练速度直接提升了四倍。
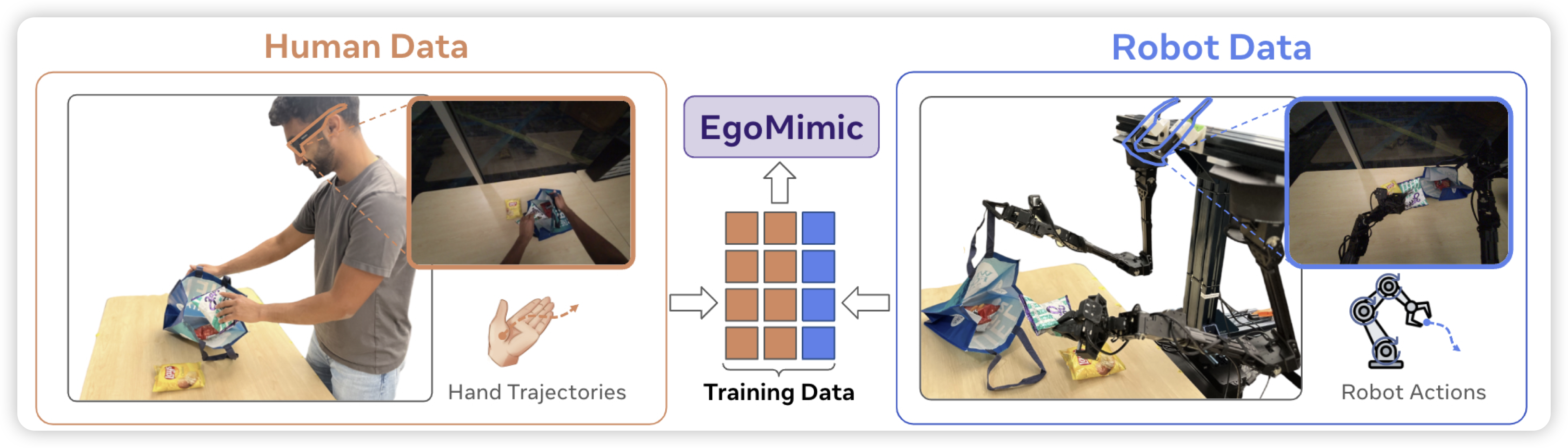
EgoMimic: Scaling Imitation Learning via Egocentric Video
作者软硬件联合开发,搞了一套可以用一套方法论收集机器人和人类的第一人称视角、手姿势的框架,由此就可以让具身和人类有一样的视野和数据建模方式了。由此,作者构建了同时包含人和机器人的sft数据,发现训完以后的机器人效果很不错
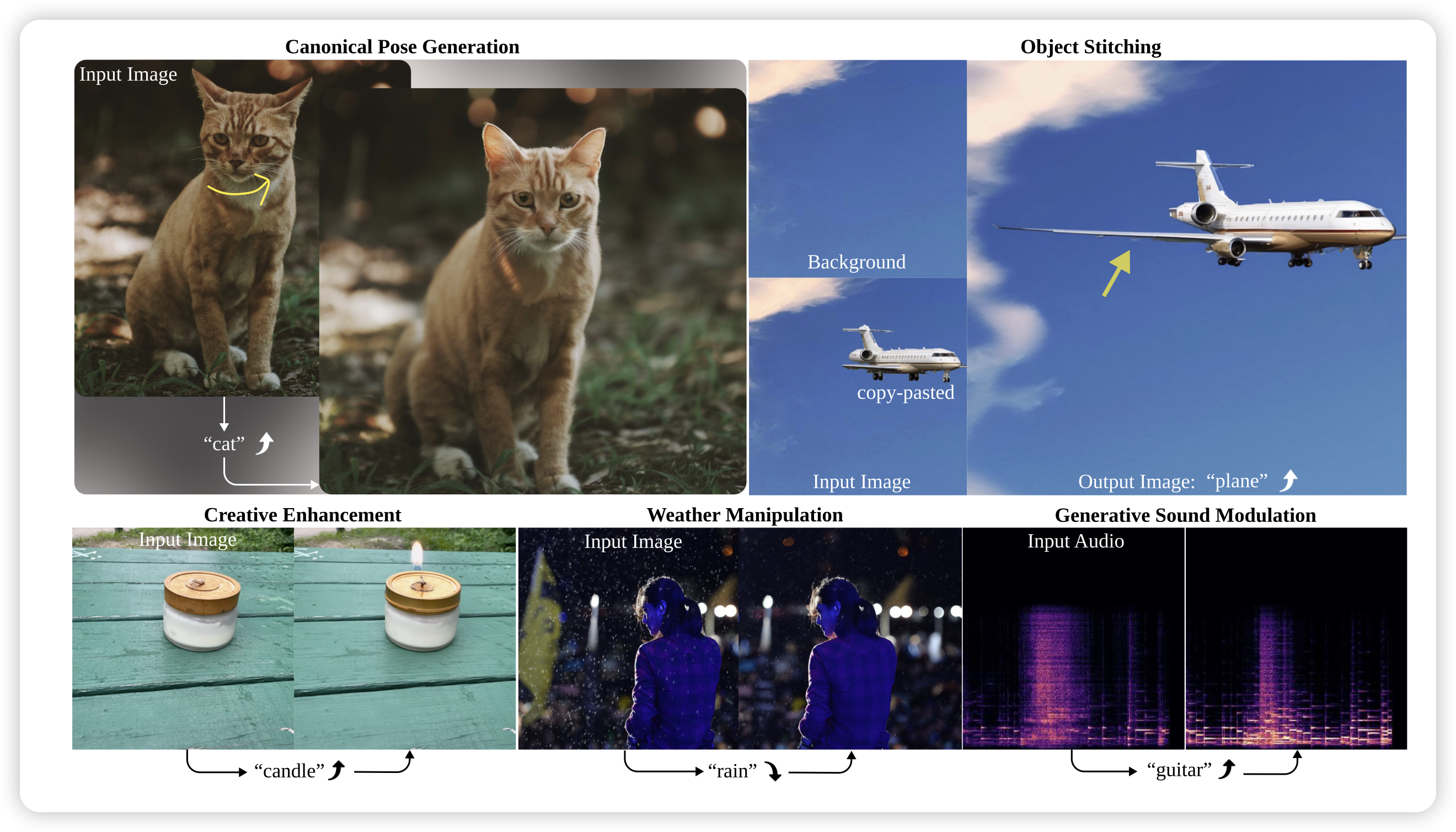
Scaling Concept With Text-Guided Diffusion Models
作者探索了text2image场景中concept的概念。所谓concept,就是说图片里对于某种"元素"的占比,比如一张飞机的图片,加重”plane“的概念,飞机可能会变得更大。如果可以操控模型对于concept的权重,就可以实现很多修图的效果。作者设计了一个pipeline,使得训出来的模型可以按照concept去修改图片
这等于是显示地建模了concept,主要原因是diffusion model没有语言理解的能力。能不能让text2image model本身具有语言理解的能力,进而去隐式地学习不同图片的区别呢?
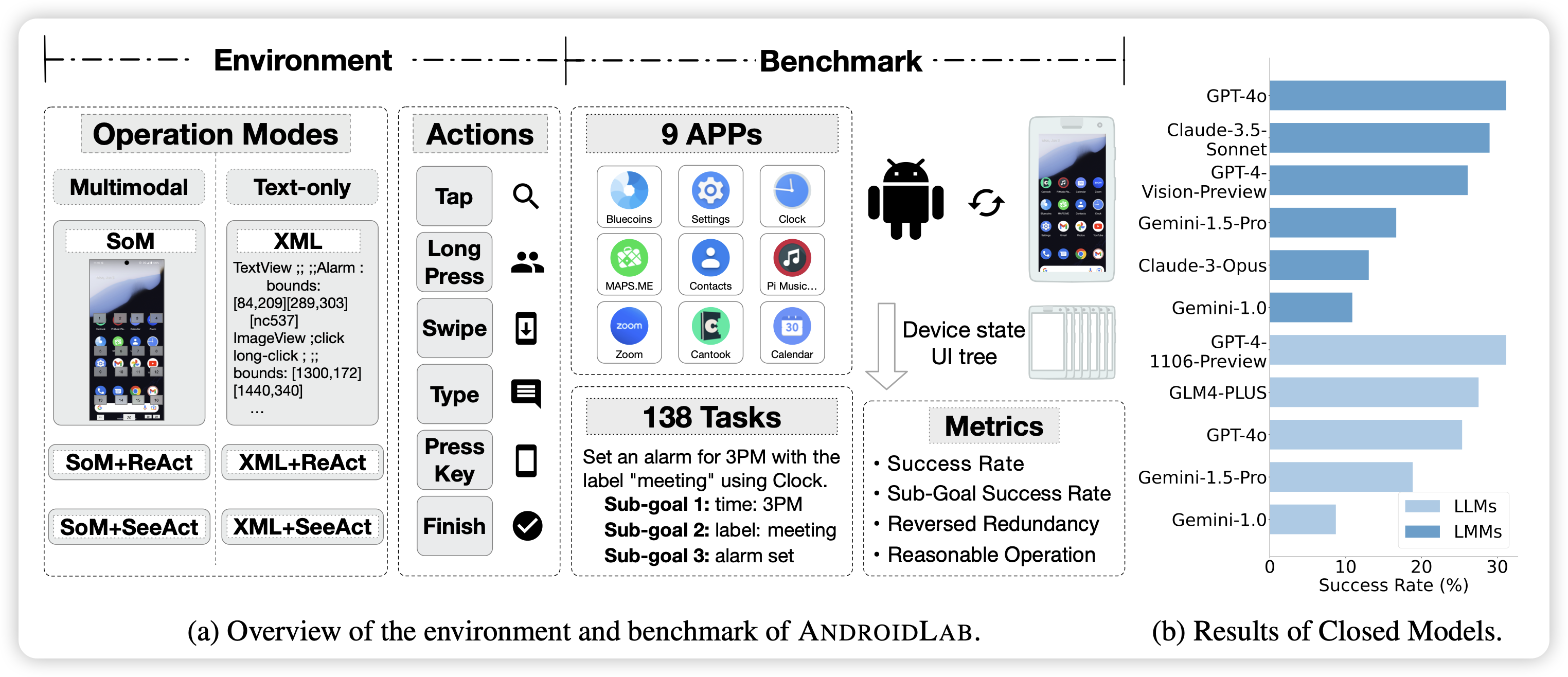
AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents
唐杰老师的新工作,出了一个安卓的benchmark和SFT数据,有点类似之前google的androidControl。
这是准备布局手机场景了,之前出了AutoWebGLM布局网页