今天肉眼可见多了一堆planning token、MCTS类的工作……OpenAI又引领学术界发展了
Language Models “Grok” to Copy
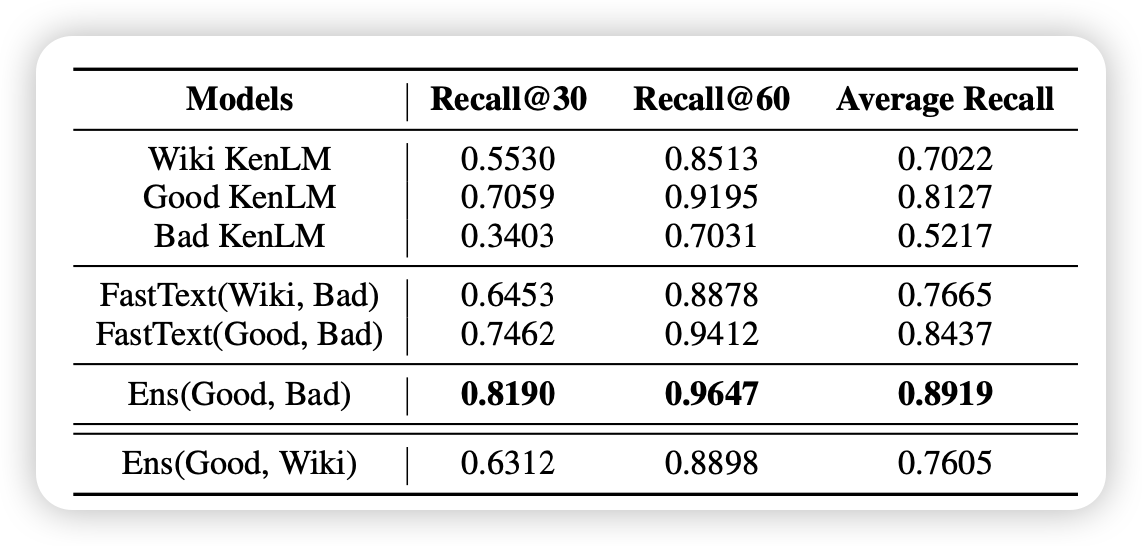
作者探索了LLM在训练中学习copy的能力:从context中直接找到一些片段来抄袭。像下面这个sample,上下文是50组随机数(有些组是重复的),然后输入其中一个的前缀,比较牛的模型可能就会发现降低ppl的好方式是抄袭前面出现过的串。作者发现不同训练阶段模型的表现类似于grokking现象:在训练集上很快过拟合,在测试集表现一坨;但是过了很久以后,在测试集上突然领悟了
大家对于grokking的解释一般是”学习快但上限低的记忆回路和学习慢但上限高的泛化回路互相竞争“。但在这个场景中,记忆回路按理来说也可以解决?
Rethinking KenLM: Good and Bad Model Ensembles for Efficient Text Quality Filtering in Large Web Corpora
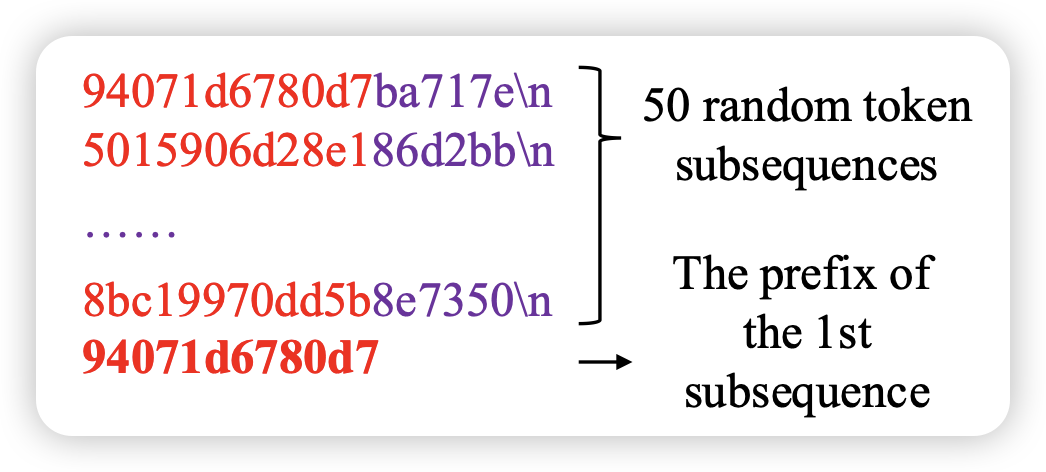
一篇挺专的论文:如何从预训练语料里挖掘高质量数据。已有工作kenlm的方案是用一个在高质量语料上训练的n-gram LM作为数据筛,作者认为这种方案只看到了好的语料,没看到坏的语料,没有对比学习的思路在里面。所以作者训练了两个kenlm,一个在好语料一个在坏语料,综合两个模型的结果,最终的筛选质量比fasText高。
感觉挺不错的小品工作,说起来upstage AI最近论文都挺好的